윈도우 함수

행과 행 간의 관계를 정의하는 함수
순위, 합계, 평균, 행 위치 등 계산 결과를 사용할 수 있다.종류
•
순위 함수
•
집계 함수
•
행 순서 함수
•
비율 함수
문법 구조
SELECT 윈도우함수( 인수 )
OVER (
[PARTITION BY 컬럼1, 컬럼2, ...]
[ORDER BY 컬럼1 [ASC | DESC], 컬럼2 [ASC | DESC], ...]
[WINDOWING 절]
)
FROM 테이블;
SQL
복사
•
기본 구성 요소
구성 요소 | 설명 |
함수 | 윈도우 함수의 종류를 나타냅니다.
예를 들어, SUM(), AVG(), ROW_NUMBER() 등이 있습니다. |
OVER | 윈도우 함수를 사용하기 위한 키워드입니다. |
PARTITION BY | 선택적으로 사용됩니다.
데이터를 파티션으로 나누는 데 사용됩니다. |
ORDER BY | 선택적으로 사용됩니다.
윈도우 함수를 적용할 때 정렬 순서를 지정합니다.
기본적으로 정렬 순서는 현재 행을 중심으로 적용됩니다. |
•
WINDOWING 절

윈도우 함수가 적용이 될 범위를 지정하는 키워드
용어 | 설명 |
ROWS | ROWS 키워드는 윈도우에서 ROWS를 기준으로 범위를 지정합니다.
예를 들어, ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING은
현재 행을 중심으로 앞의 1개의 행과 뒤의 1개의 행을 포함하는 윈도우 범위를 정의합니다. |
RANGE | RANGE 키워드는 윈도우에서 값의 범위를 기준으로 범위를 지정합니다.
주로 숫자나 날짜와 같은 순서형 데이터 유형의 컬럼에 대해 사용됩니다. |
BETWEEN~AND | BETWEEN~AND 키워드는 윈도우의 범위를 지정할 때 사용됩니다.
예를 들어, ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING과 같이 사용됩니다. |
UNBOUNDED PRECEDING | UNBOUNDED PRECEDING은 윈도우의 시작을 나타내며,
현재 행보다 앞의 모든 행을 포함합니다. |
UNBOUNDED FOLLOWING | UNBOUNDED FOLLOWING은 윈도우의 끝을 나타내며,
현재 행보다 뒤의 모든 행을 포함합니다. |
CURRENT ROW | CURRENT ROW는 윈도우에서 현재 행을 나타냅니다. |
PRECEDING | 현재 행 이전에 위치한 행들 가리킵니다. |
FOLLOWING | 현재 행 이후에 위치한 행들을 가리킵니다. |
순위 함수
결과 집합 내에서 행의 순위를 결정하는 함수
함수명 | 설명 |
RANK
(공동 순위 다음 SKIP) | 동일한 값에 대한 순위를 부여하고 같은 순위에
동일한 값이 있다면 다음 순위는 건너뛰고 그 다음 순위를 부여한다. |
DENSE_RANK
(공동 순위 다음이어서) | 동일한 값에 대한 순위를 부여하고 같은 순위에
동일한 값이 있다면 다음 순위도 그 다음 순위와 동일한 값을 가진다. |
ROW_NUMBER
( 넘버링) | 순서대로 숫자를 부여하여 각 행에 대한 유일한 순위를 부여한다. |
순위 함수 예시 코드
•
RANK
•
DENSE_RANK
•
ROW_NUMBER
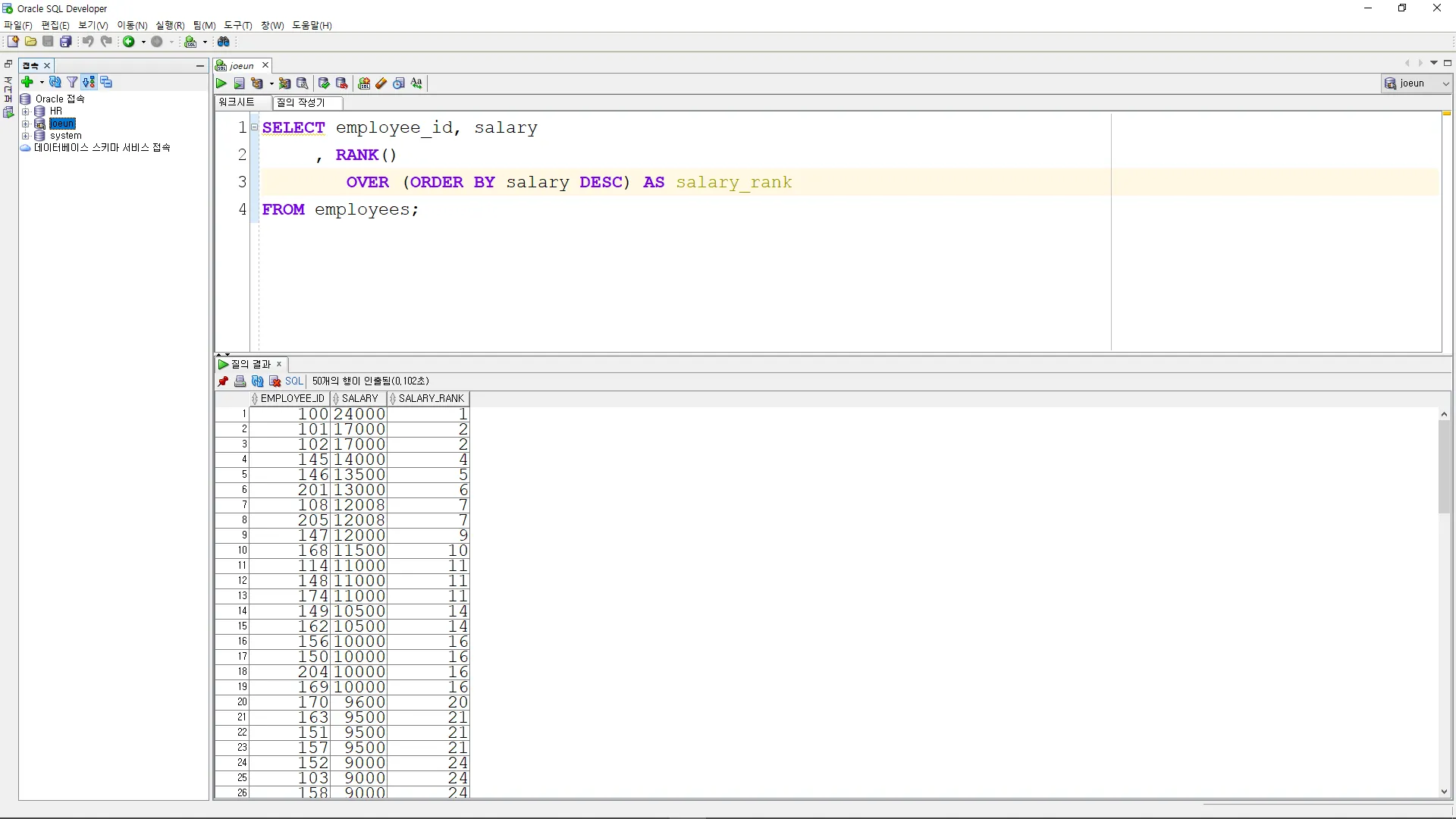
RANK
급여 내림차순으로 순위를 구하시오. (공동 순위면 다음 순위 없앰)
SELECT employee_id, salary
, RANK()
OVER (ORDER BY salary DESC) AS salary_rank
FROM employees;
SQL
복사
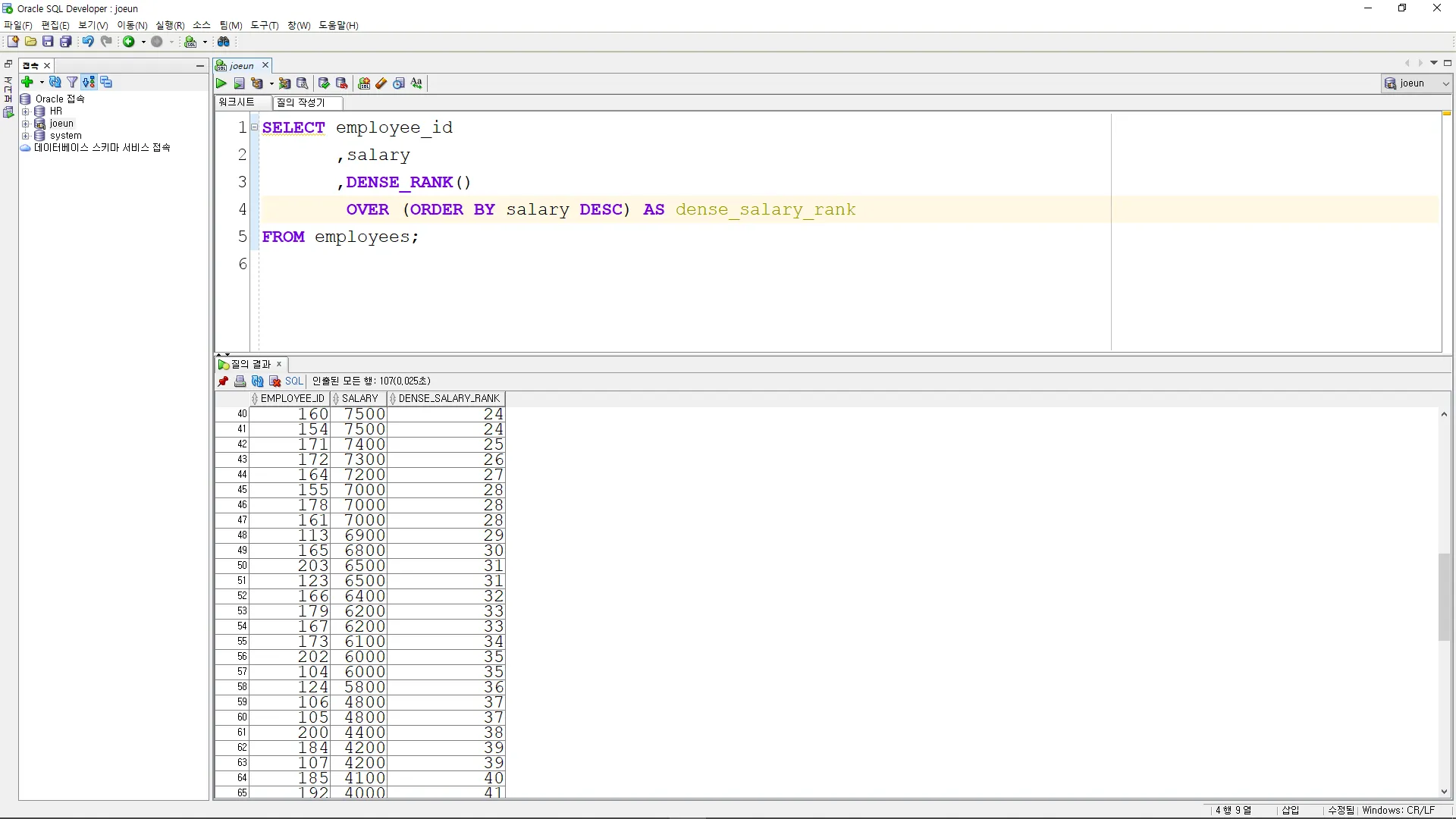
DENSE_RANK
급여 내림차순으로 순위를 구하시오. (공동 순위가 있어도 다음 순위 살림)
SELECT employee_id
,salary
,DENSE_RANK()
OVER (ORDER BY salary DESC) AS dense_salary_rank
FROM employees;
SQL
복사
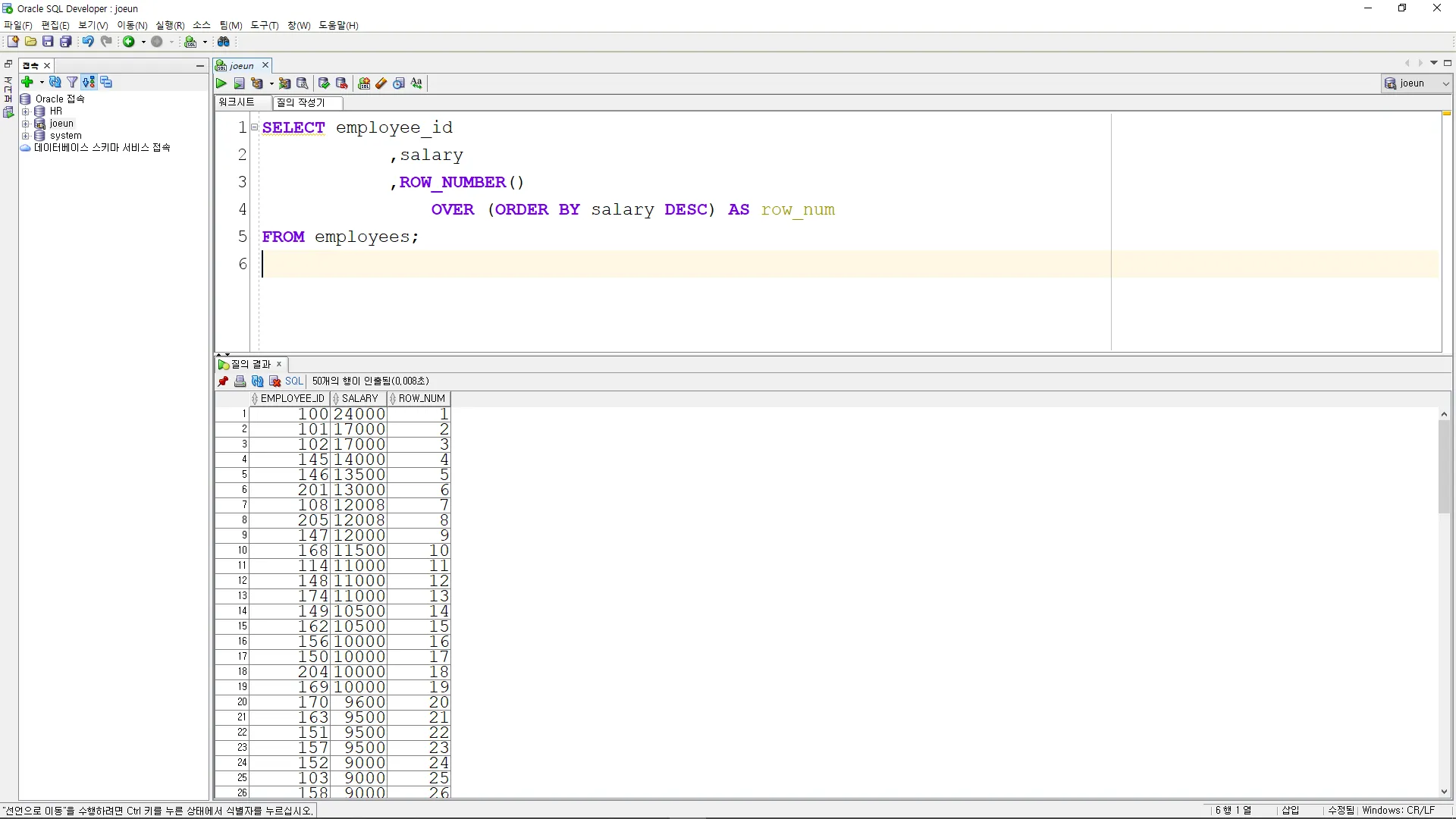
ROW_NUMBER
중복 순위 상관없이, 유일한 순서 번호로, 말 그대로 행번호를 출력
SELECT employee_id
,salary
,ROW_NUMBER()
OVER (ORDER BY salary DESC) AS row_num
FROM employees;
SQL
복사
집계 함수
여러 행의 값을 그룹화하고 집계하여 단일 결과 값을 반환하는 함수
함수명 | 설명 |
SUM | 숫자형 데이터의 합계를 계산합니다. |
AVG | 숫자형 데이터의 평균을 계산합니다. |
COUNT | 결과 집합이나 그룹의 행 수를 계산합니다. |
MAX | 숫자나 날짜 데이터의 최댓값을 찾습니다. |
MIN | 숫자나 날짜 데이터의 최솟값을 찾습니다. |
집계 함수 예시 코드
•
SUM
•
AVG
•
COUNT
•
MAX
•
MIN
SUM
SELECT SUM(salary) AS total_salary
FROM employees;
SQL
복사
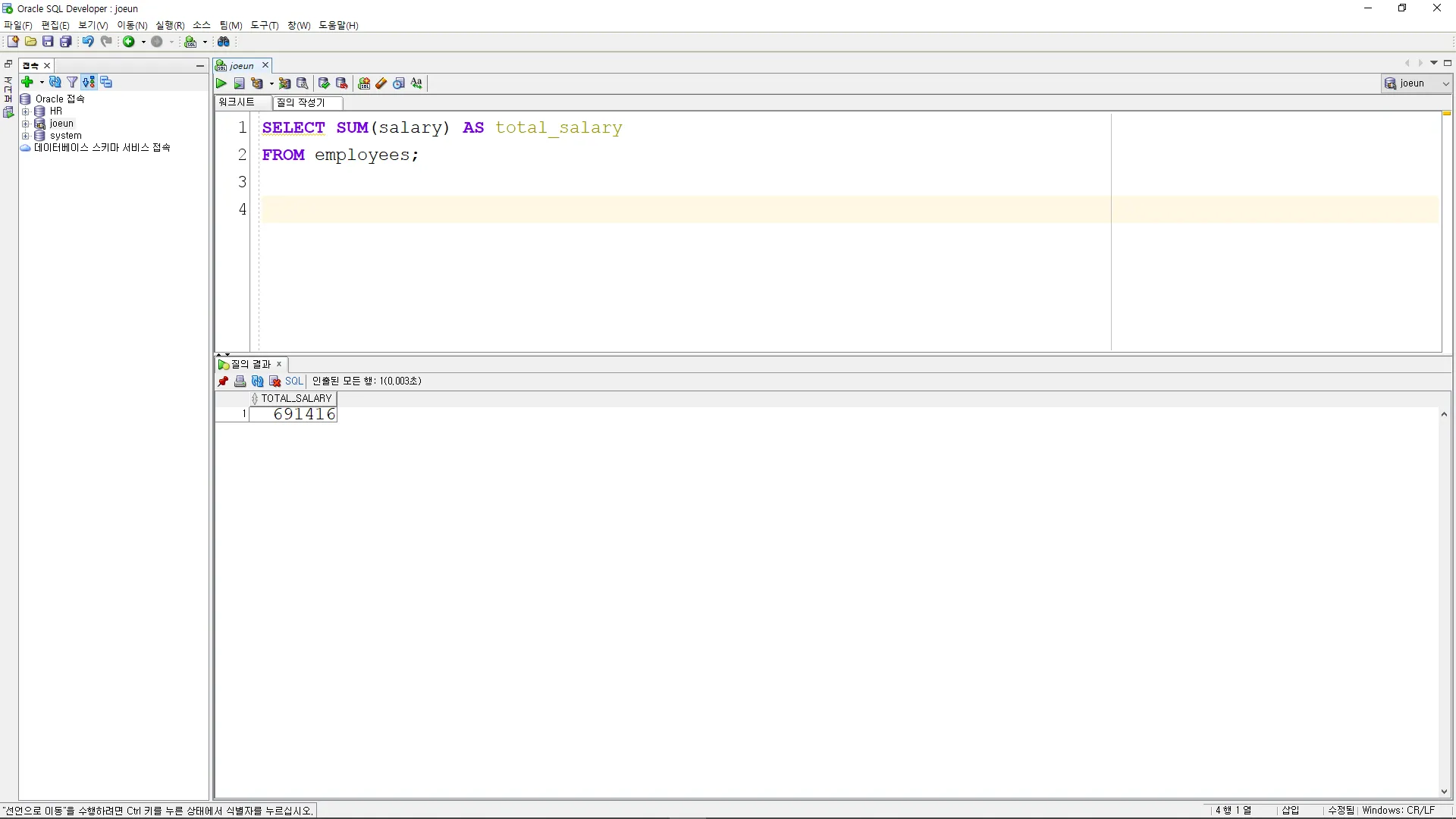
AVG
SELECT AVG(salary) AS average_salary
FROM employees;
SQL
복사
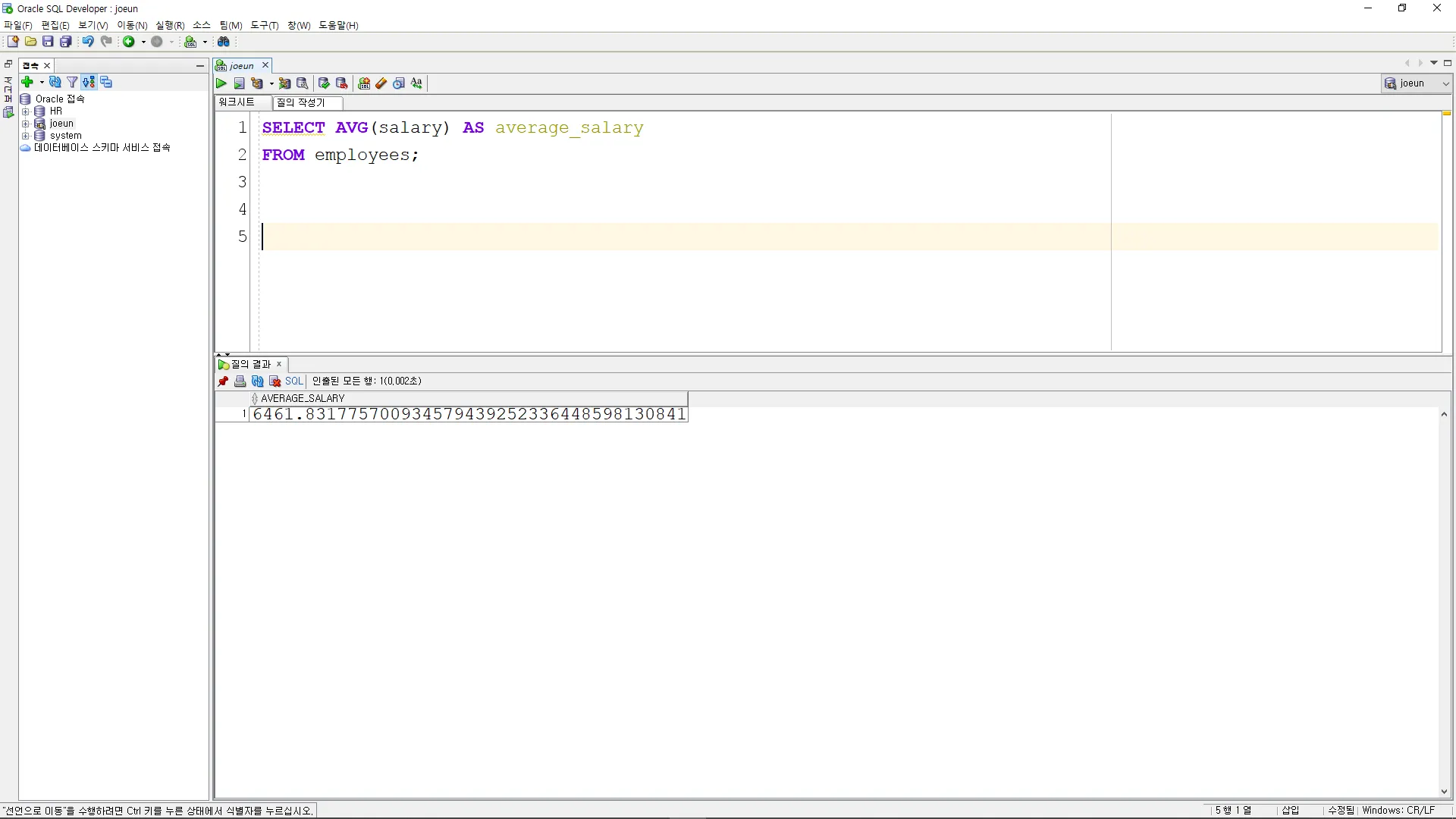
COUNT
SELECT COUNT(*) AS total_employees
FROM employees;
SQL
복사
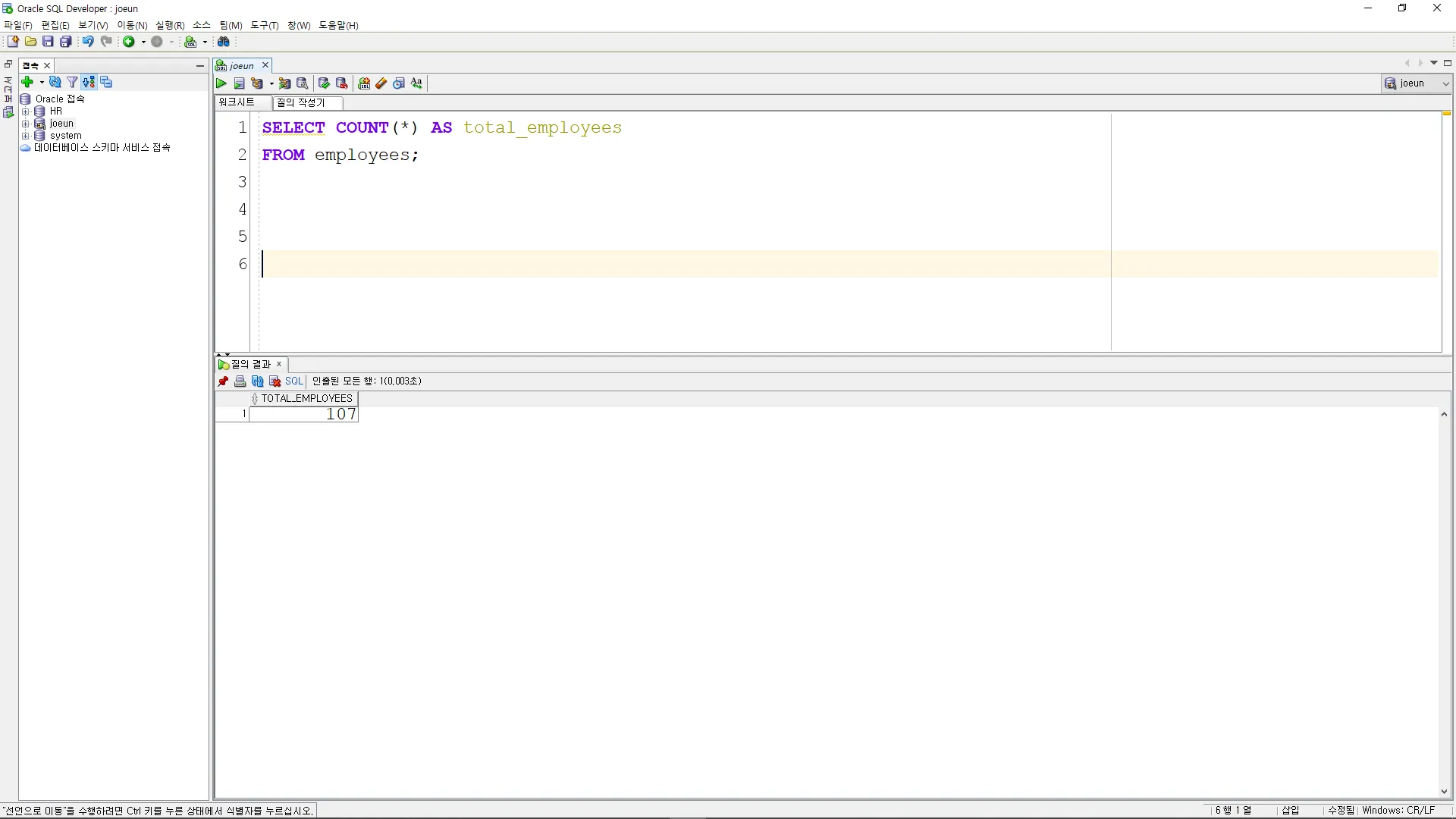
MAX
SELECT MAX(salary) AS max_salary
FROM employees;
SQL
복사
MIN
SELECT MIN(salary) AS min_salary
FROM employees;
SQL
복사
행 순서 함수
결과 집합 내에서 특정 행의 위치나 순서를 결정하는 함수
함수명 | 설명 |
FIRST_VALUE | 그룹 내에서 첫 번째 행의 값을 반환합니다. |
LAST_VALUE | 그룹 내에서 마지막 행의 값을 반환합니다. |
LAG | 현재 행 이전의 값을 가져옵니다. |
LEAD | 현재 행 다음의 값을 가져옵니다. |
행 순서 함수 예시 코드
•
FIRST_VALUE
•
LAST_VALUE
•
LAG
•
LEAD
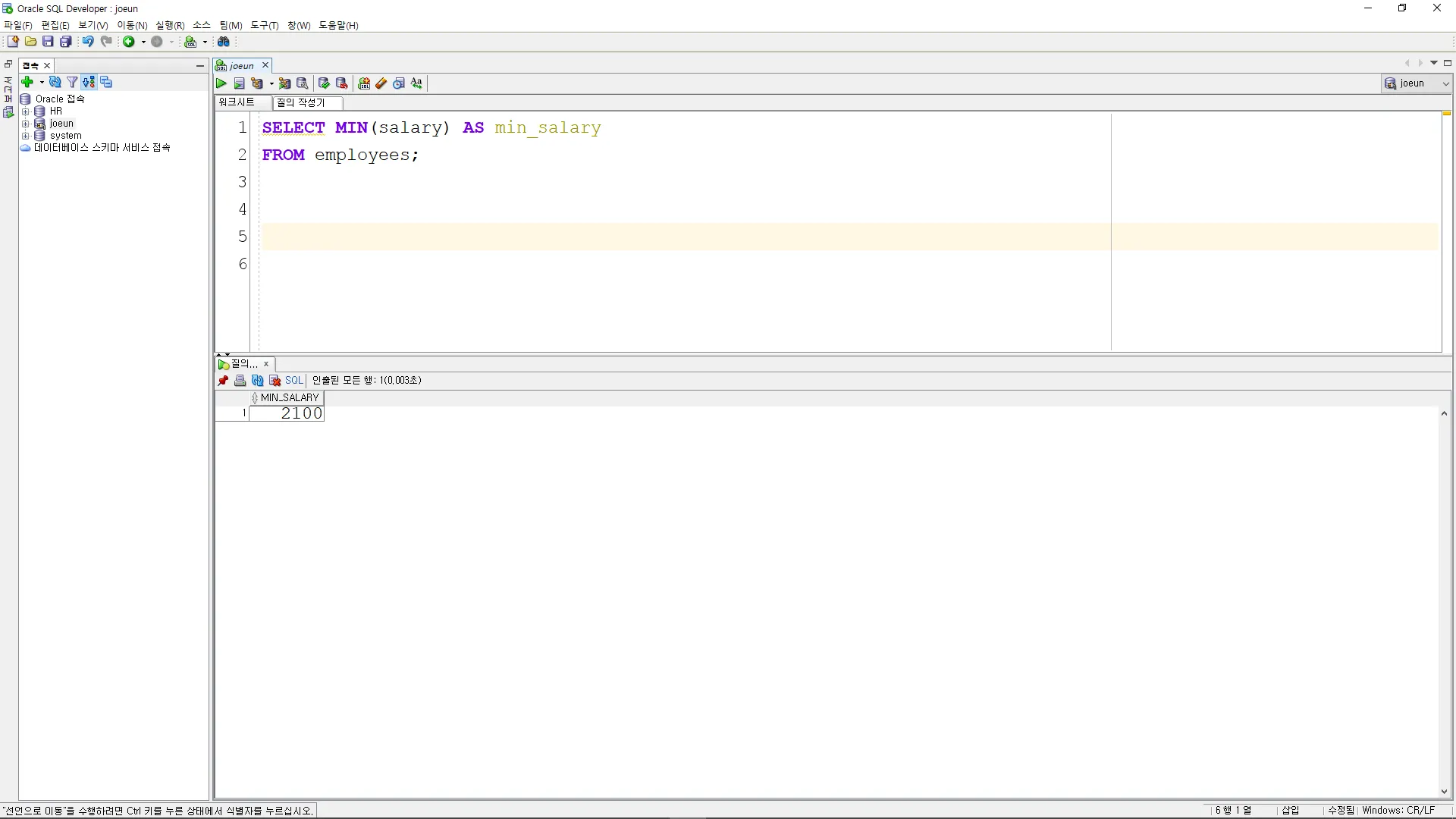
FIRST_VALUE
•
각 부서별로 첫 번째로 입사한 직원의 급여를 조회
SELECT department_id
, employee_id
, salary
,FIRST_VALUE(salary)
OVER (PARTITION BY department_id
ORDER BY hire_date) AS first_salary
FROM employees;
SQL
복사
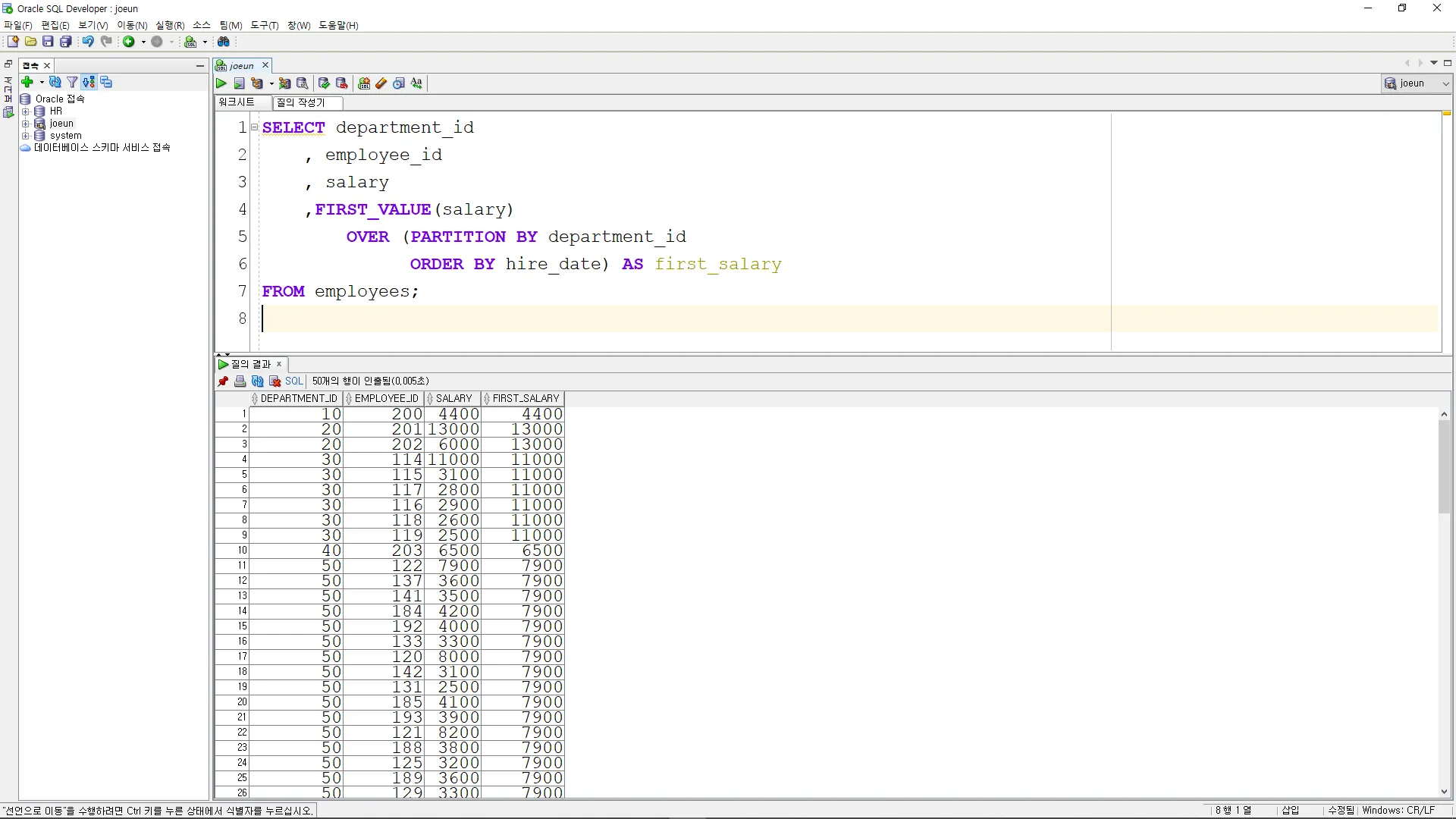
LAST_VALUE
•
각 부서별로 마지막으로 입사한 직원의 급여를 조회
SELECT department_id
, employee_id
, salary
, LAST_VALUE(salary)
OVER (PARTITION BY department_id
ORDER BY hire_date
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS last_salary
FROM employees;
SQL
복사
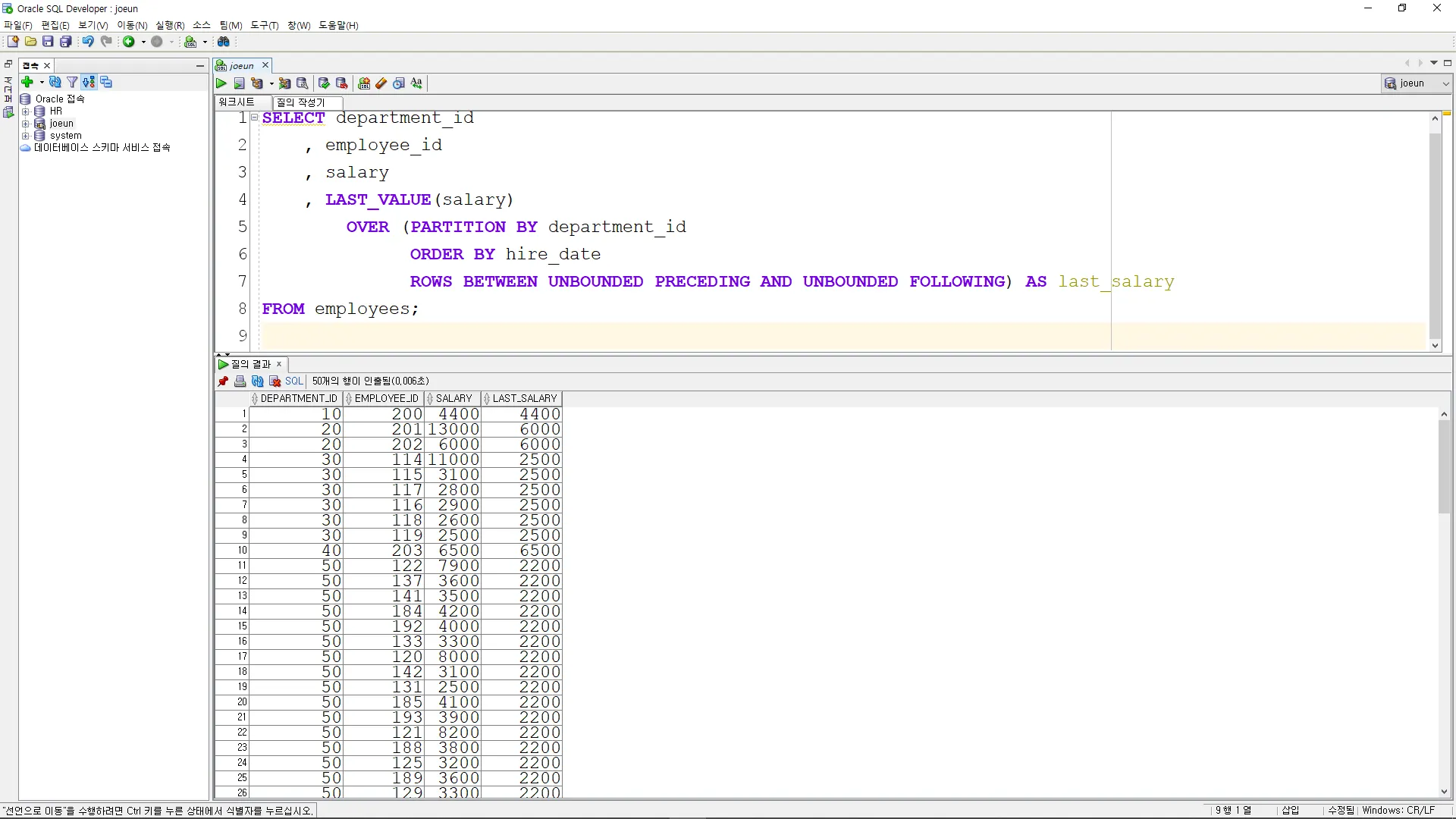
LAG
•
이전 직원의 정보를 조회
SELECT employee_id, first_name, hire_date,
LAG(first_name) OVER (ORDER BY hire_date) AS previous_name,
LAG(hire_date) OVER (ORDER BY hire_date) AS previous_hire_date
FROM employees;
SQL
복사
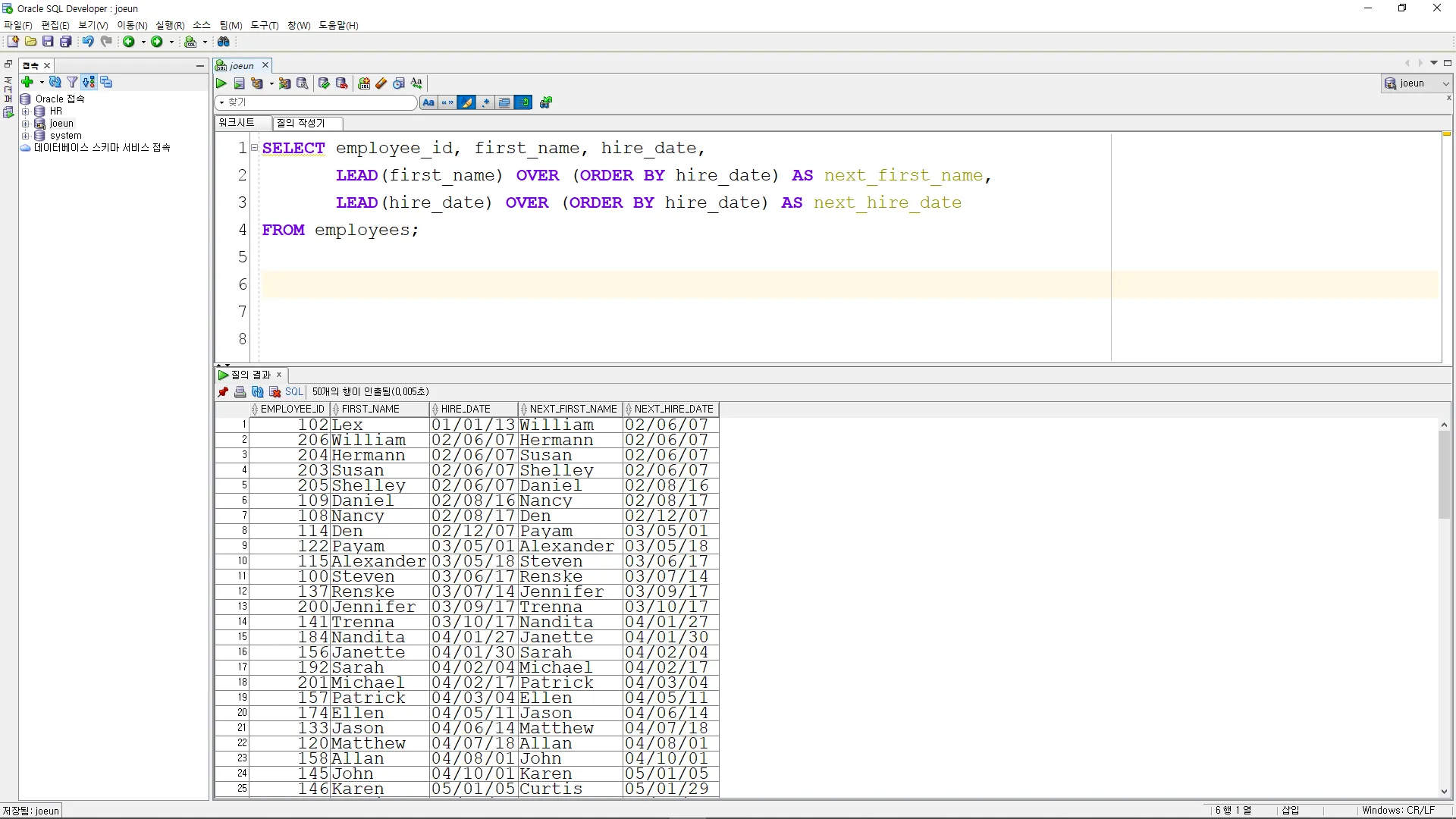
LEAD
•
다음 직원의 정보를 조회
SELECT employee_id, first_name, hire_date,
LEAD(first_name) OVER (ORDER BY hire_date) AS next_first_name,
LEAD(hire_date) OVER (ORDER BY hire_date) AS next_hire_date
FROM employees;
SQL
복사
비율 함수
결과 집합 내에서 특정 값의 비율이나 백분율을 계산하는 함수
함수명 | 설명 |
CUME_DIST | 결과 집합에서 현재 행의 누적 분포 값을 계산합니다. |
PERCENT_RANK | 결과 집합에서 현재 행의 백분위 순위를 계산합니다. |
NTILE | 결과 집합을 지정된 개수의 동일한 크기의 그룹으로 나누고,
각 행에 그룹 번호를 할당합니다. |
RATIO_TO_REPORT | 결과 집합의 각 그룹에서 현재 행의 비율을 계산합니다. |
비율 함수 예시 코드
•
CUME_DIST
•
PERCENT_RANK
•
NTILE
•
RATIO_TO_REPORT
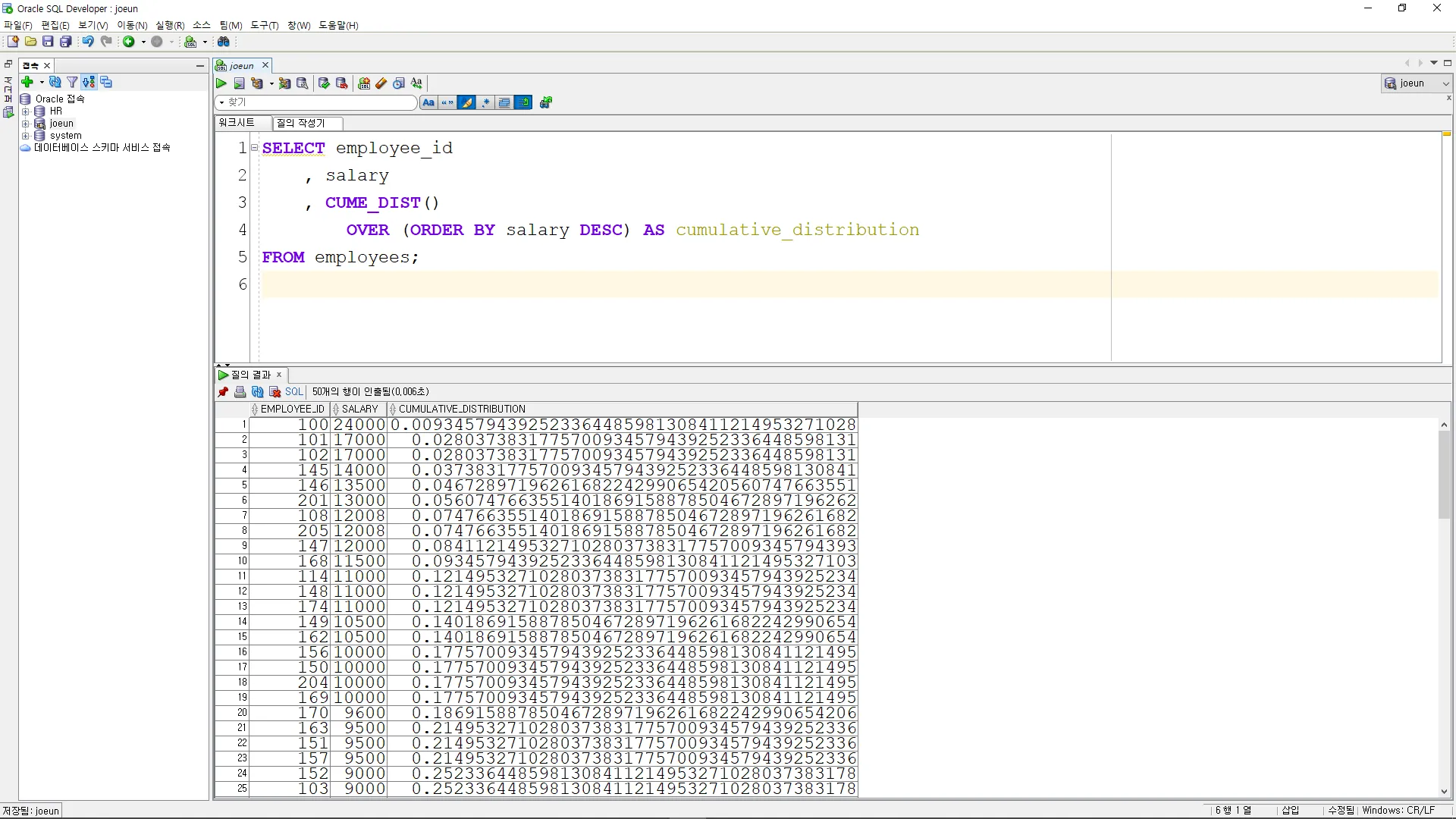
CUME_DIST
이 함수는 결과 집합에서 현재 행의 누적 분포 값을 계산
SELECT employee_id
, salary
, CUME_DIST()
OVER (ORDER BY salary DESC) AS cumulative_distribution
FROM employees;
SQL
복사
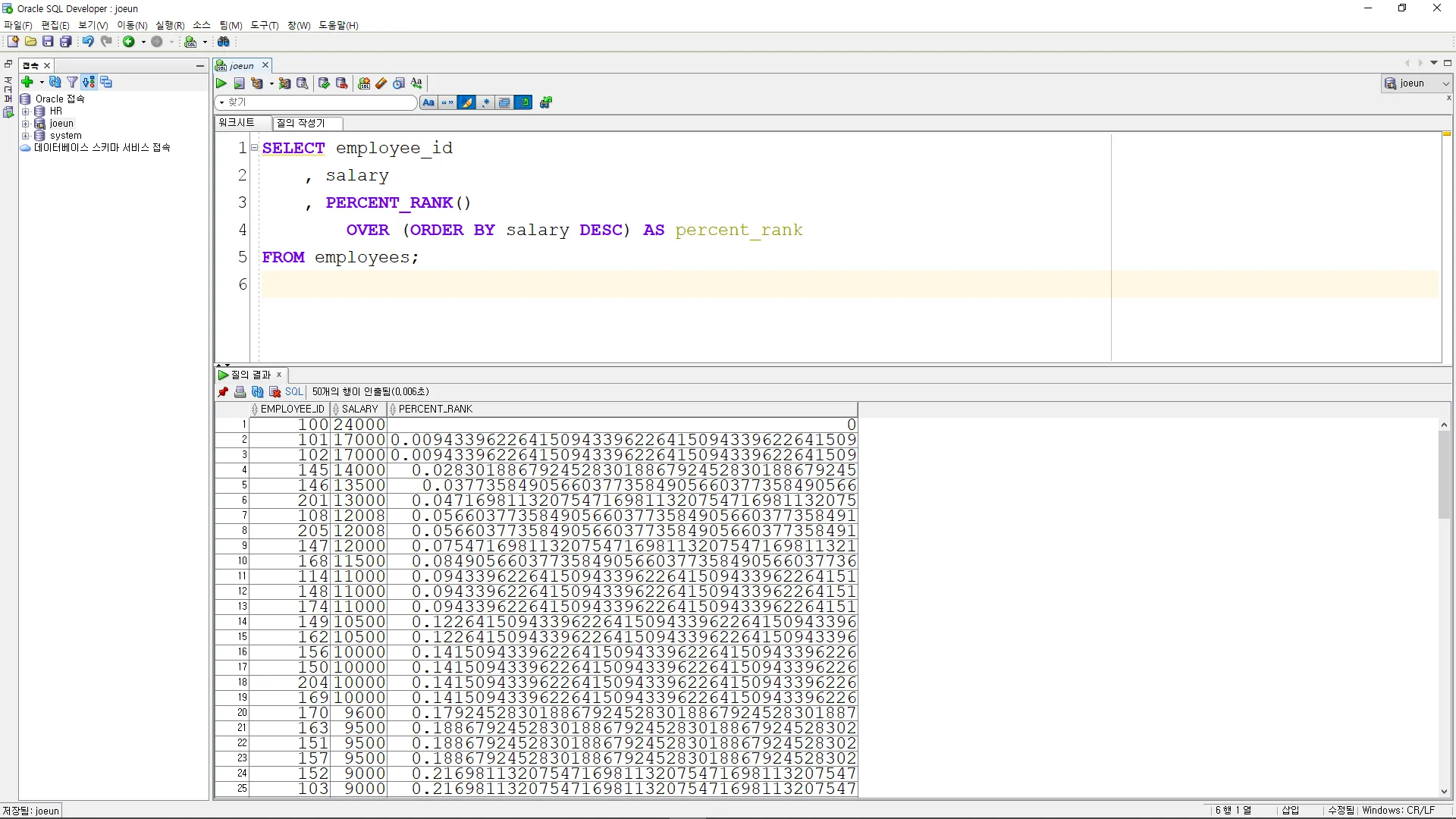
PERCENT_RANK
이 함수는 결과 집합에서 현재 행의 백분위 순위를 계산
SELECT employee_id
, salary
, PERCENT_RANK()
OVER (ORDER BY salary DESC) AS percent_rank
FROM employees;
SQL
복사
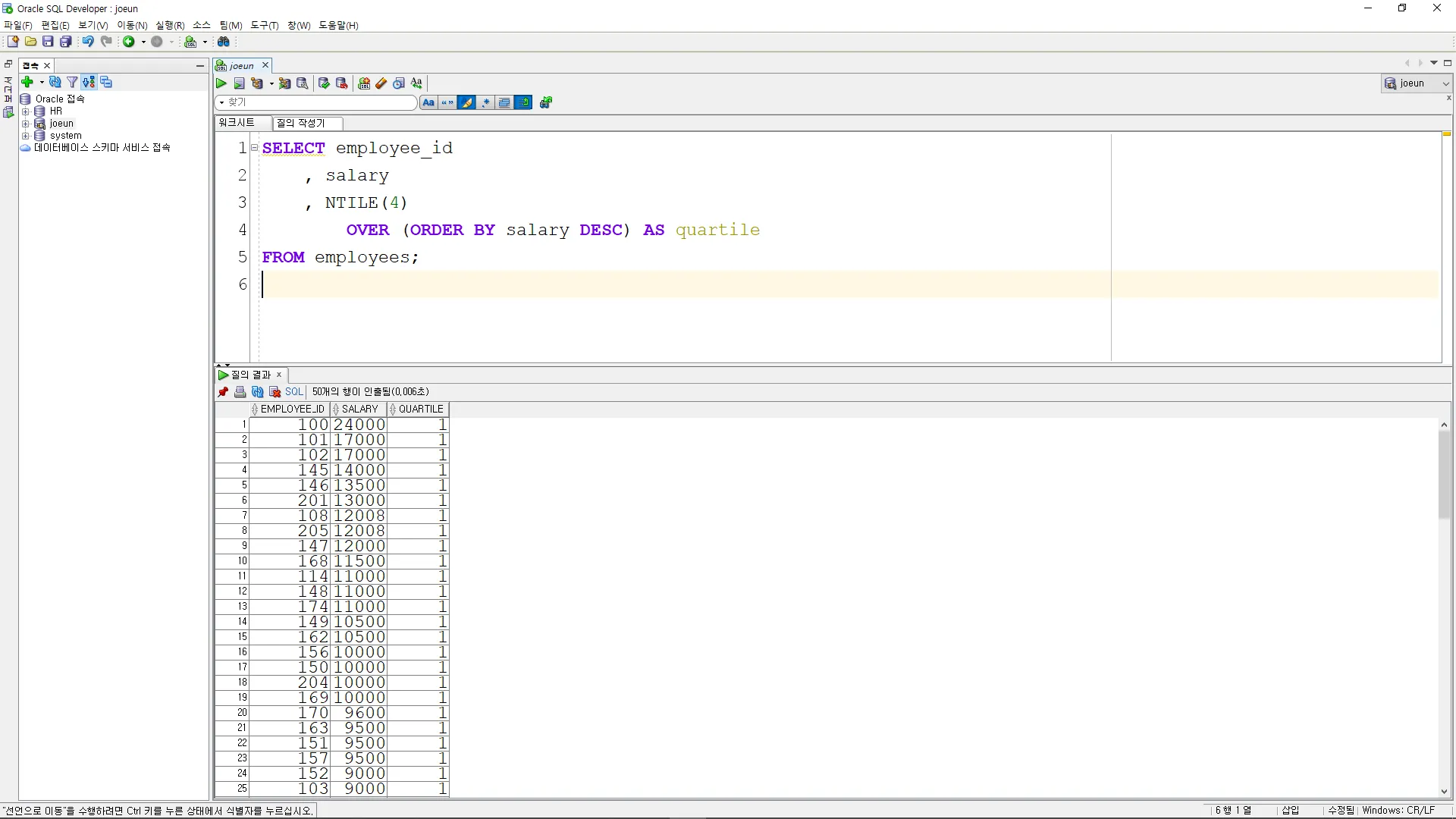
NTILE
결과 집합을 지정된 개수의 동일한 크기의 그룹으로 나누고, 각 행에 그룹 번호를 할당
SELECT employee_id
, salary
, NTILE(4)
OVER (ORDER BY salary DESC) AS quartile
FROM employees;
SQL
복사
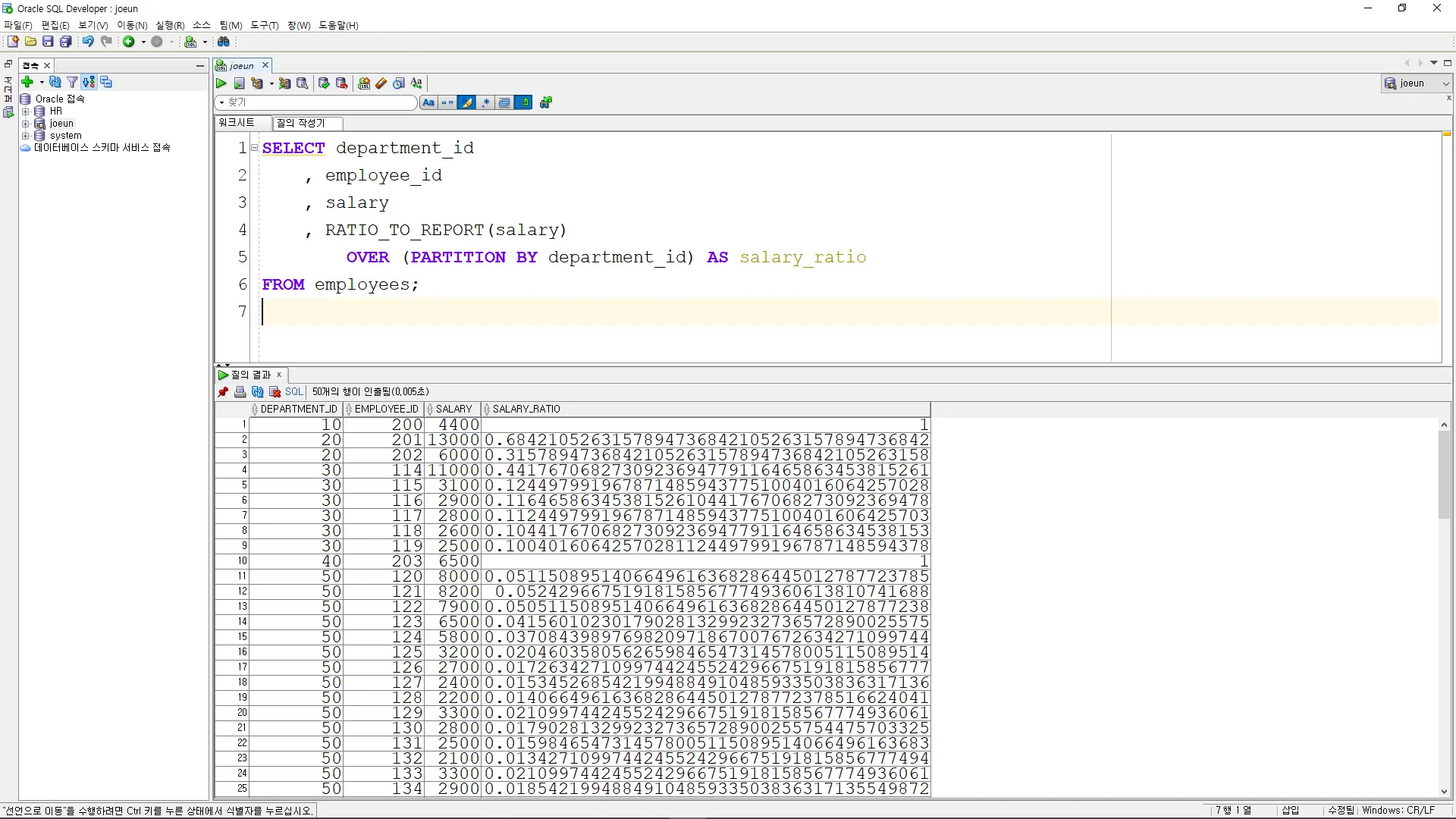
RATIO_TO_REPORT
이 함수는 결과 집합의 각 그룹에서 현재 행의 비율을 계산
SELECT department_id
, employee_id
, salary
, RATIO_TO_REPORT(salary)
OVER (PARTITION BY department_id) AS salary_ratio
FROM employees;
SQL
복사