

SQL 활용

•
•
서브쿼리 (Sub Query)

SQL문 내부에 사용하는 SELECT 문
메인쿼리 : 서브쿼리를 사용하는 최종적인 SELECT 문서브쿼리 분류
•
실행 결과에 따른 분류
◦
단일행 서브쿼리
◦
다중행 서브쿼리
▪
다중 행 연산자 : IN, ANY, ALL, EXISTS•
사용 위치에 따른 분류
◦
스칼라 서브쿼리
◦
인라인 뷰
◦
서브 쿼리
실행 결과에 따른 분류
•
단일행 서브쿼리 : 결과 데이터가 하나인 서브쿼리
•
다중행 서브쿼리 : 결과 데이터가 여러 행인 서브쿼리
연산 | 설명 |
IN | 해당 컬럼과 여러 개의 값이 일치하는 데이터를 구하는 연산 |
ANY | A 비교연산 ANY B: 비교한 결과 중, 하나 만이라도 조건을 만족하는 A를 구하는 연산 |
ALL | A 비교연산 ALL B: 비교한 결과 중, 모든 데이터에 대해 조건을 만족하는 A를 구하는 연산 |
EXISTS | 서브쿼리에 존재하는 데이터만 조회하는 연산 |
사용 위치에 따른 분류
•
스칼라 서브쿼리 : SELECT 절에서 사용하는 서브쿼리
•
인라인 뷰 : FROM 절에서 사용하는 서브쿼리
•
서브 쿼리 : WHERE 절에서 사용하는 서브쿼리
서브쿼리 예시코드
•
단일행 서브쿼리
•
다중행 서브쿼리
◦
IN
◦
ANY
◦
ALL
◦
EXISTS
•
스칼라 서브쿼리
•
인라인 뷰
•
서브쿼리
단일행 서브쿼리
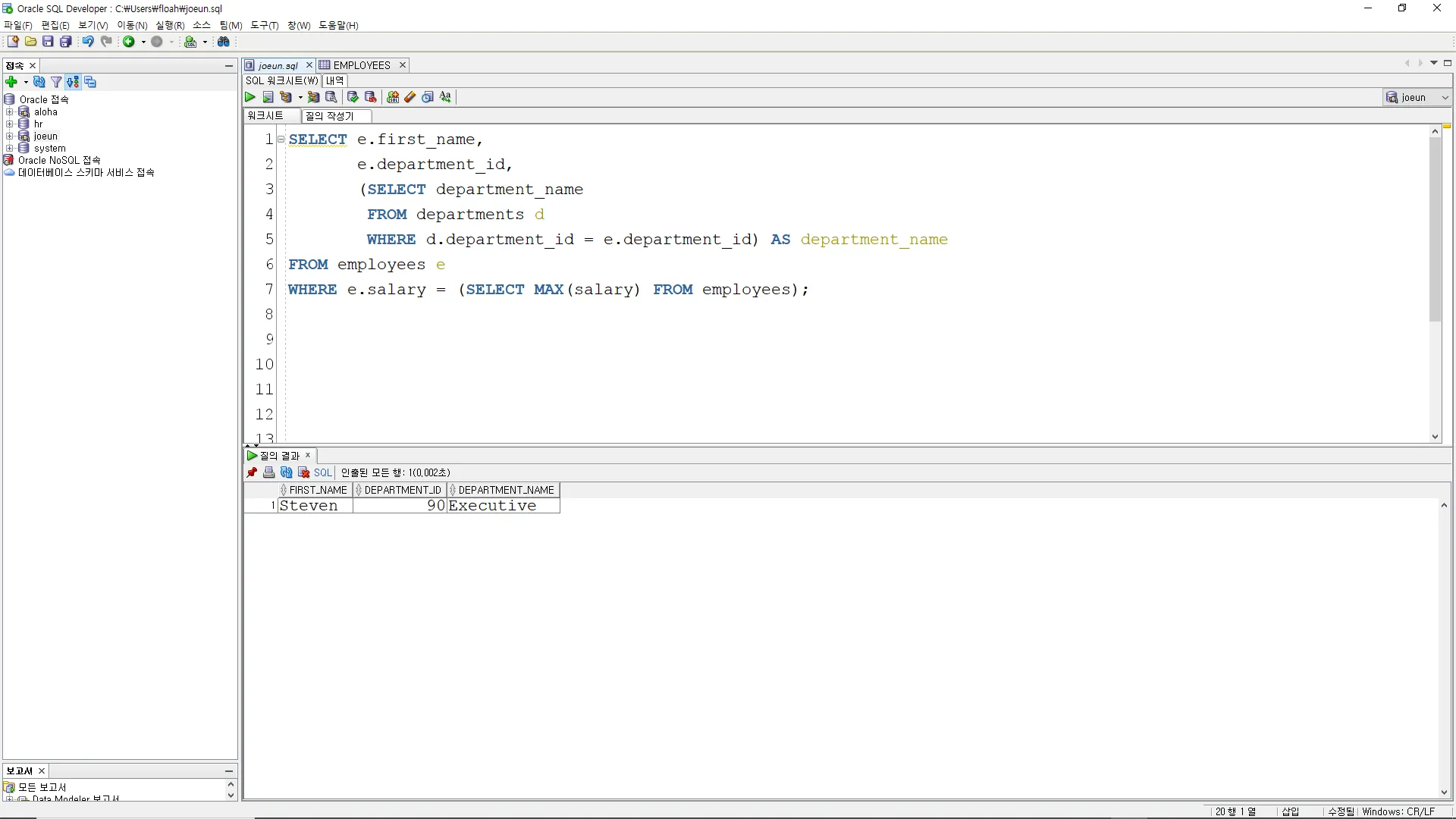
직원 테이블에서 가장 높은 급여를 받는 직원의 이름과 해당 부서 ID를 조회하고, 그 부서의 이름을 함께 출력하십시오.
SELECT e.first_name,
e.department_id,
(SELECT department_name
FROM departments d
WHERE d.department_id = e.department_id) AS department_name
FROM employees e
WHERE e.salary = (SELECT MAX(salary) FROM employees);
SQL
복사
이 예시에서는 먼저 가장 높은 급여를 받는 직원의 급여를 서브쿼리를 사용하여 조회합니다. 그리고 그 급여와 일치하는 직원의 이름과 부서 ID를 메인 쿼리에서 선택하고, 부서 테이블을 서브쿼리로 사용하여 해당 부서의 이름을 찾아 출력합니다.
다중행 서브쿼리
IN
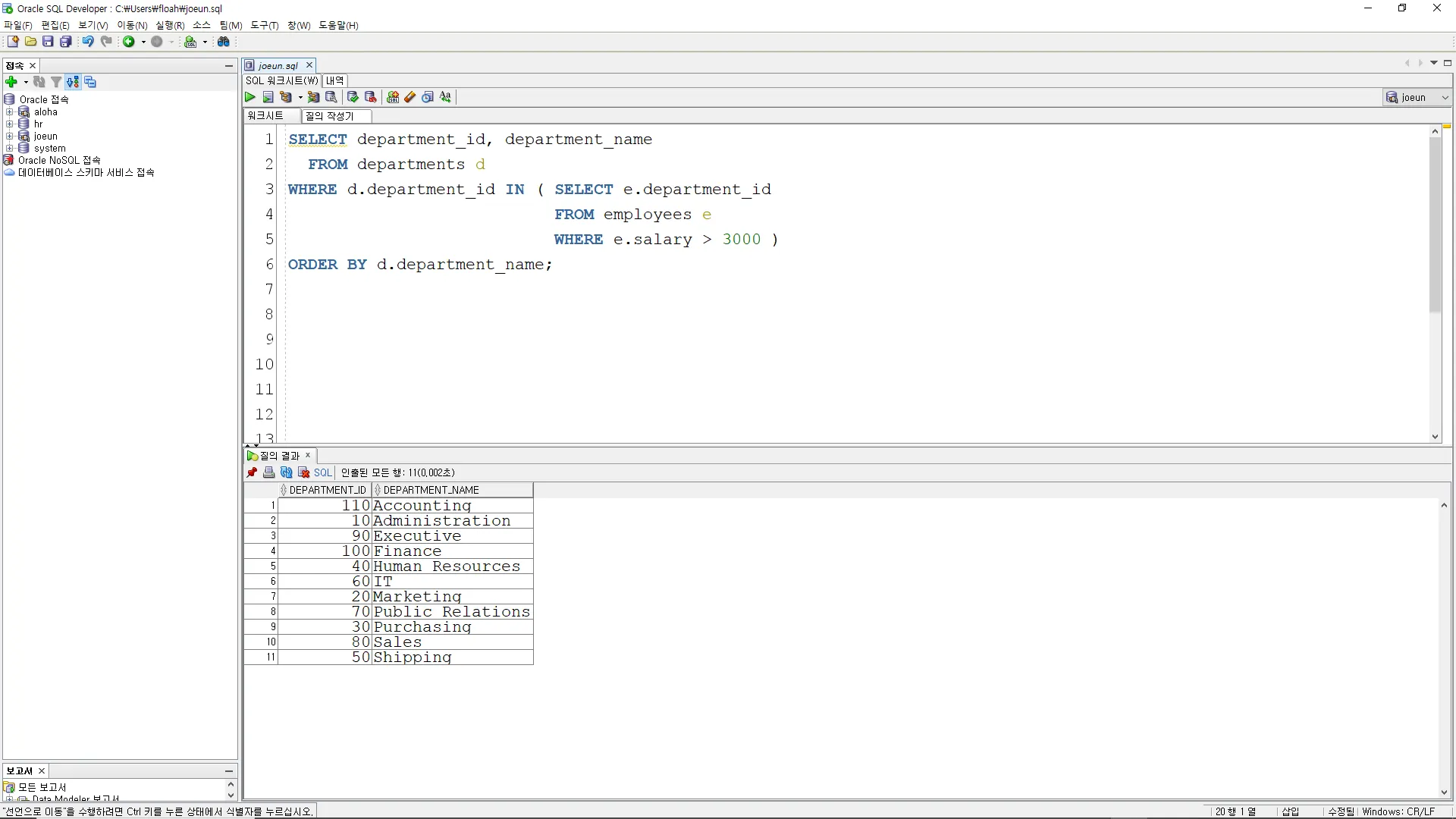
3000보다 높은 급여를 받는 직원이 속한 부서의 부서 ID와 부서 이름을 조회하되, 부서 이름을 기준으로 정렬하십시오.
SELECT department_id, department_name
FROM departments d
WHERE d.department_id IN (SELECT e.department_id
FROM employees e
WHERE e.salary > 3000)
ORDER BY d.department_name;
SQL
복사
1.
departments 테이블에서 department_id와 department_name 열을 선택합니다.
2.
서브쿼리를 사용하여 직원 테이블(employees)에서 급여가 3000보다 높은 직원의 부서 ID를 선택합니다.
3.
메인 쿼리에서는 부서 테이블에서 선택된 부서 ID를 가진 부서만을 필터링합니다.
4.
마지막으로 부서 이름을 기준으로 결과를 정렬합니다.
ANY
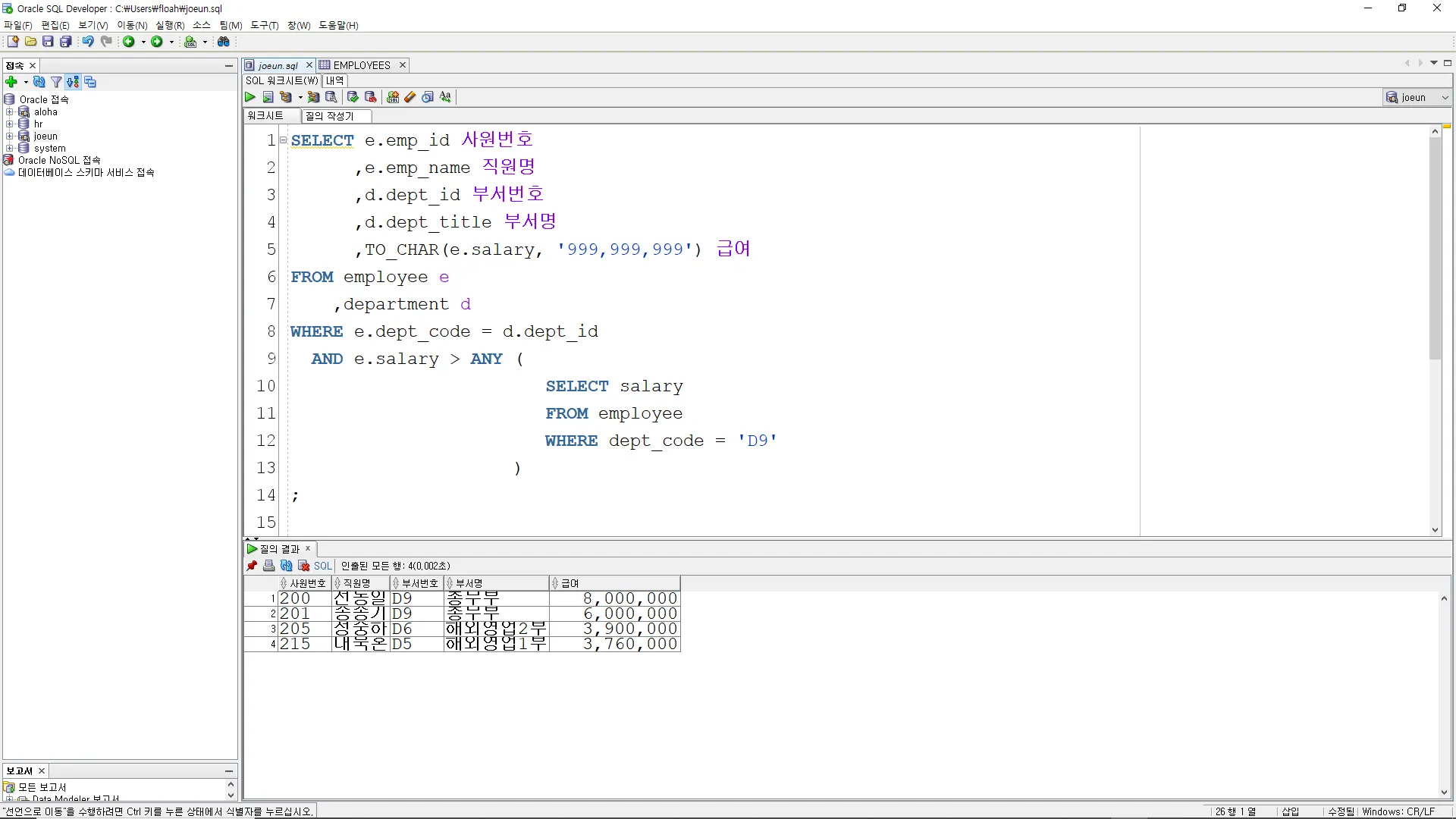
EMPLOYEE 테이블의 DEPT_CODE 가 'D9' 인 부서의 최저급여 보다 더 큰 급여를 받는 사원을 조회하시오.
SELECT e.emp_id 사원번호
,e.emp_name 직원명
,d.dept_id 부서번호
,d.dept_title 부서명
,TO_CHAR(e.salary, '999,999,999') 급여
FROM employee e
,department d
WHERE e.dept_code = d.dept_id
AND e.salary > ANY (
SELECT salary
FROM employee
WHERE dept_code = 'D9'
)
SQL
복사
1.
employee 테이블(e)과 department 테이블(d)을 조인합니다. 이를 통해 직원의 부서 정보를 가져옵니다.
2.
직원의 사원번호(emp_id), 직원명(emp_name), 부서번호(dept_id), 부서명(dept_title), 그리고 급여(salary)를 선택합니다.
3.
WHERE 절에서는 다음을 수행합니다:
•
e 테이블과 d 테이블의 dept_code와 dept_id가 일치하는 행만 선택합니다.
•
e 테이블의 급여가 'D9' 부서의 어떤 직원의 급여보다 높은 경우를 선택합니다.
4.
TO_CHAR 함수를 사용하여 급여를 특정 형식으로 변환합니다. 이 경우, '999,999,999' 형식을 사용하여 금액을 3자리마다 쉼표로 구분된 형식으로 표시합니다.
이 쿼리의 결과는 'D9' 부서의 어떤 직원의 급여보다 높은 급여를 받는 모든 직원의 정보를 포함합니다.
ALL
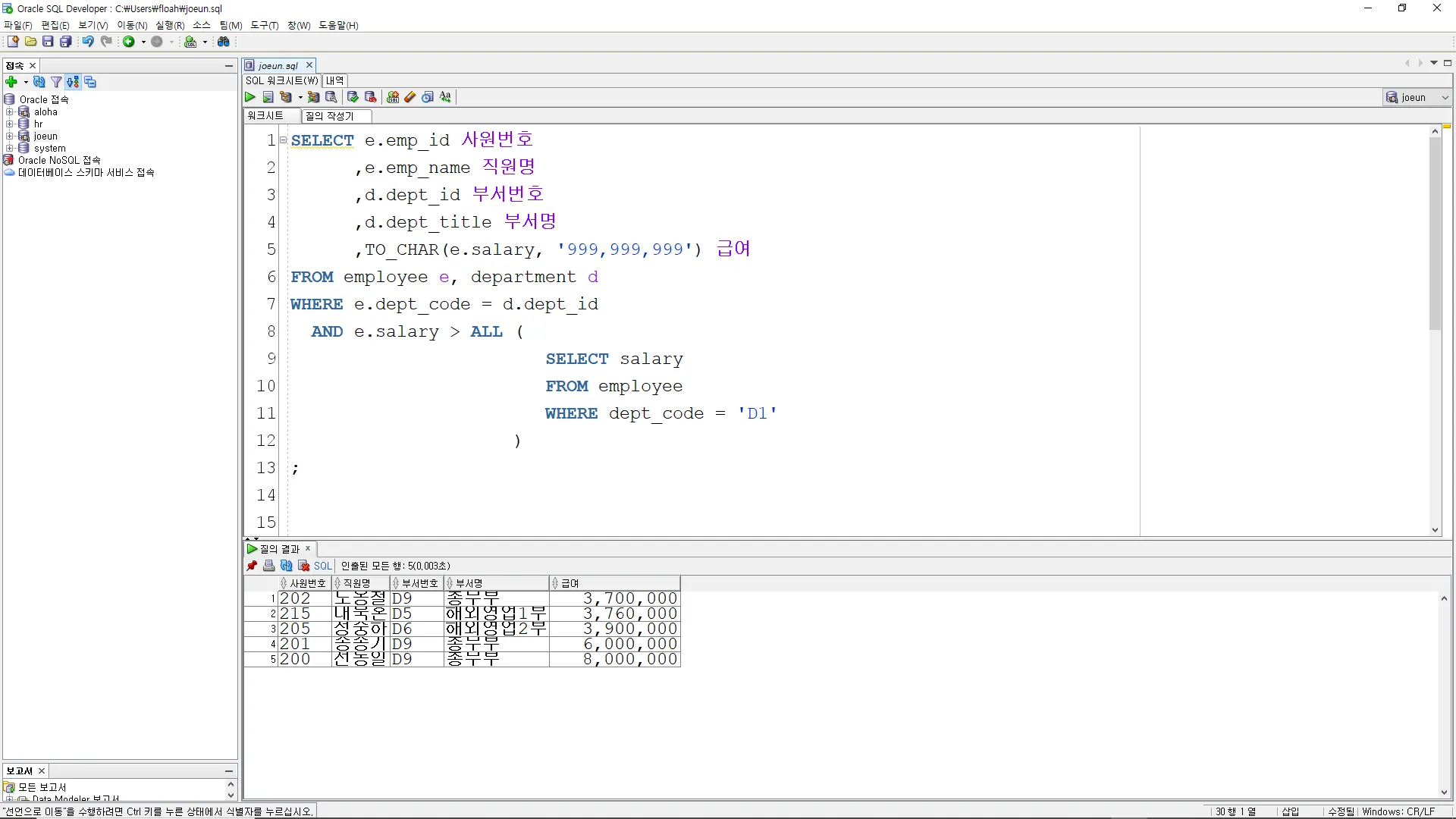
EMPLOYEE 테이블의 DEPT_CODE 가 'D1' 인 부서의 최대급여 보다 더 큰 급여를 받는 사원을 조회하시오.
SELECT e.emp_id 사원번호
,e.emp_name 직원명
,d.dept_id 부서번호
,d.dept_title 부서명
,TO_CHAR(e.salary, '999,999,999') 급여
FROM employee e, department d
WHERE e.dept_code = d.dept_id
AND e.salary > ALL (
SELECT salary
FROM employee
WHERE dept_code = 'D1'
)
;
SQL
복사
1.
employee 테이블(e)과 department 테이블(d)을 조인합니다. 이를 통해 직원의 부서 정보를 가져옵니다.
2.
직원의 사원번호(emp_id), 직원명(emp_name), 부서번호(dept_id), 부서명(dept_title), 그리고 급여(salary)를 선택합니다.
3.
WHERE 절에서는 다음을 수행합니다:
•
e 테이블과 d 테이블의 dept_code와 dept_id가 일치하는 행만 선택합니다.
•
e 테이블의 급여가 'D1' 부서의 모든 직원의 급여보다 높은 경우를 선택합니다.
4.
TO_CHAR 함수를 사용하여 급여를 특정 형식으로 변환합니다. 이 경우, '999,999,999' 형식을 사용하여 금액을 3자리마다 쉼표로 구분된 형식으로 표시합니다.
이 쿼리의 결과는 'D1' 부서의 모든 직원의 급여보다 높은 급여를 받는 모든 직원의 정보를 포함합니다.
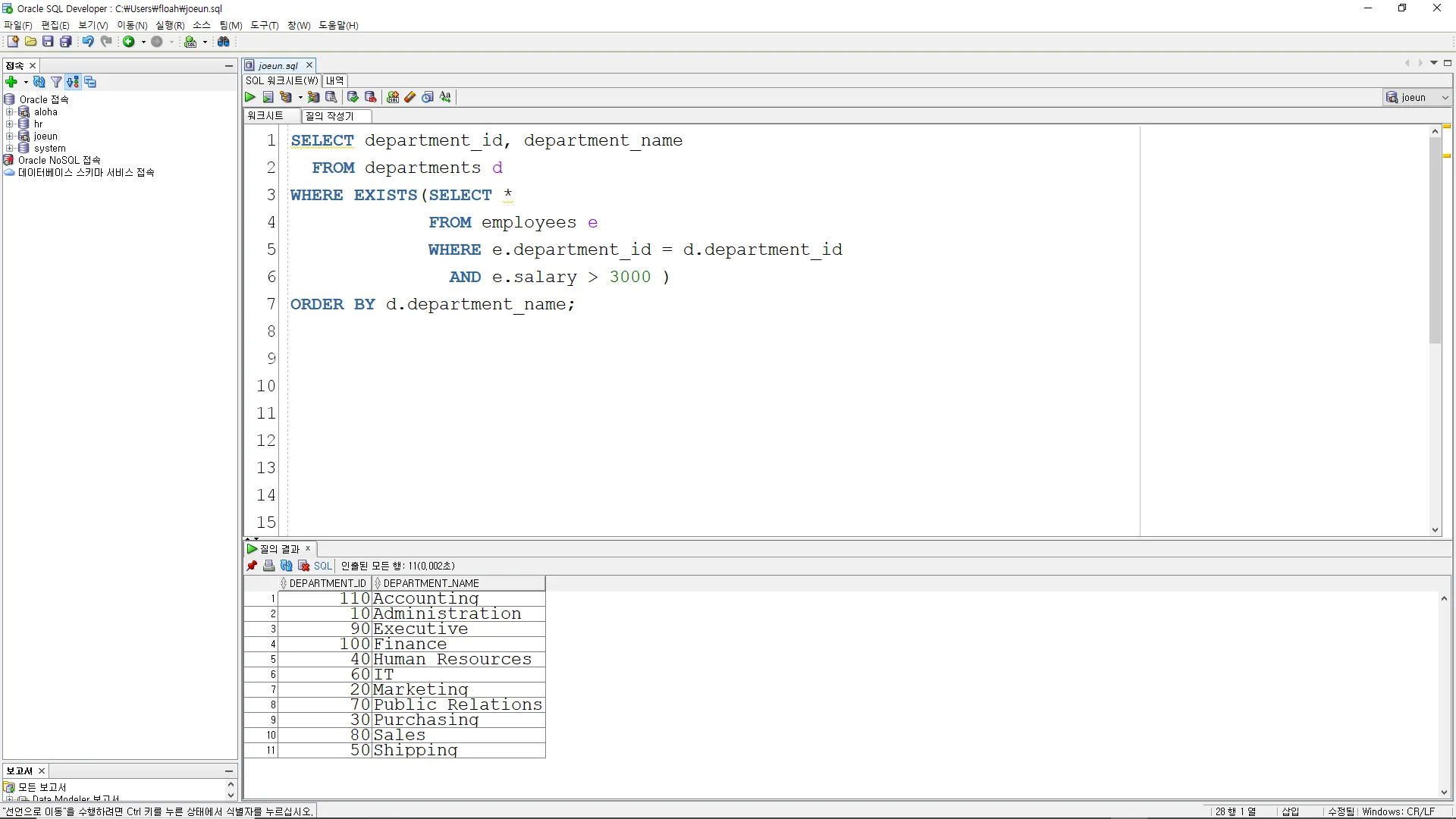
EXISTS
급여가 3000보다 높은 직원이 속한 부서의 부서 ID와 부서 이름을 조회하십시오. 단, 부서 이름을 기준으로 오름차순으로 정렬하십시오. EXISTS를 사용하여 부서 테이블과 직원 테이블의 관계를 고려하십시오.
SELECT department_id, department_name
FROM departments d
WHERE EXISTS(SELECT *
FROM employees e
WHERE e.department_id = d.department_id
AND e.salary > 3000 )
ORDER BY d.department_name;
SQL
복사
1.
부서 테이블(departments)을 기준으로 시작합니다.
2.
EXISTS 서브쿼리를 사용하여 각 부서에 대해 다음을 확인합니다:
•
직원 테이블(employees)에서 해당 부서의 직원이 급여가 3000보다 높은지 여부를 확인합니다.
3.
만약 서브쿼리의 결과가 참(즉, 적어도 한 명의 직원이 급여가 3000보다 높은 경우)이면, 해당 부서를 결과에 포함합니다.
4.
WHERE 절의 조건을 만족하는 모든 부서의 부서 ID와 부서 이름을 선택합니다.
5.
마지막으로 부서 이름을 기준으로 오름차순으로 결과를 정렬합니다.
이 쿼리는 각 부서에 대해 급여가 3000보다 높은 직원이 적어도 한 명 이상 있는 경우 해당 부서의 부서 ID와 부서 이름을 반환합니다.
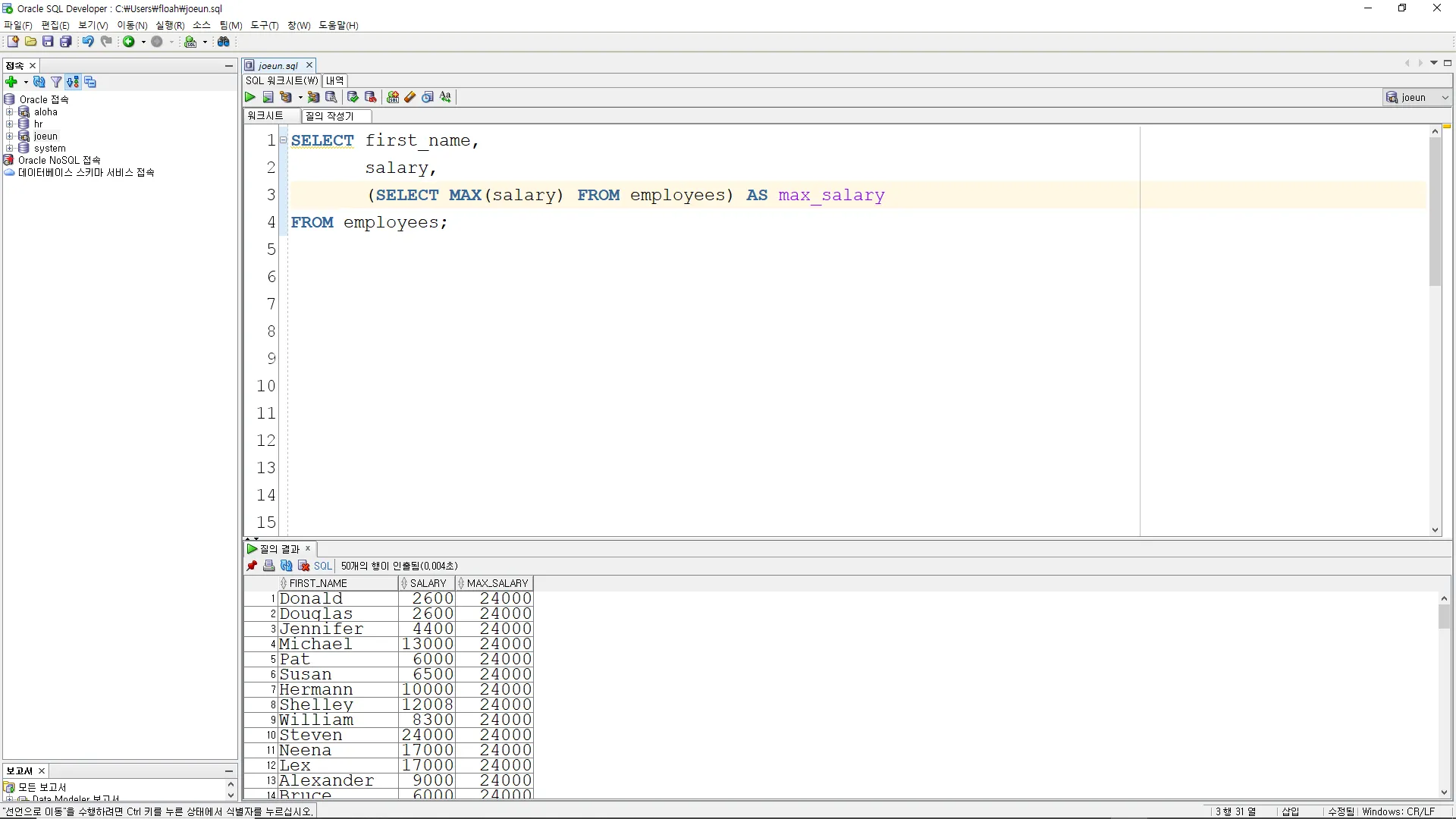
스칼라 서브쿼리
직원 테이블에서 가장 높은 급여를 조회
SELECT employee_name,
salary,
(SELECT MAX(salary) FROM employees) AS max_salary
FROM employees;
SQL
복사
이 예시에서는 스칼라 서브쿼리를 사용하여 직원 테이블에서 가장 높은 급여를 조회합니다. 이 값을 각 직원의 행에 포함시켜 출력합니다.
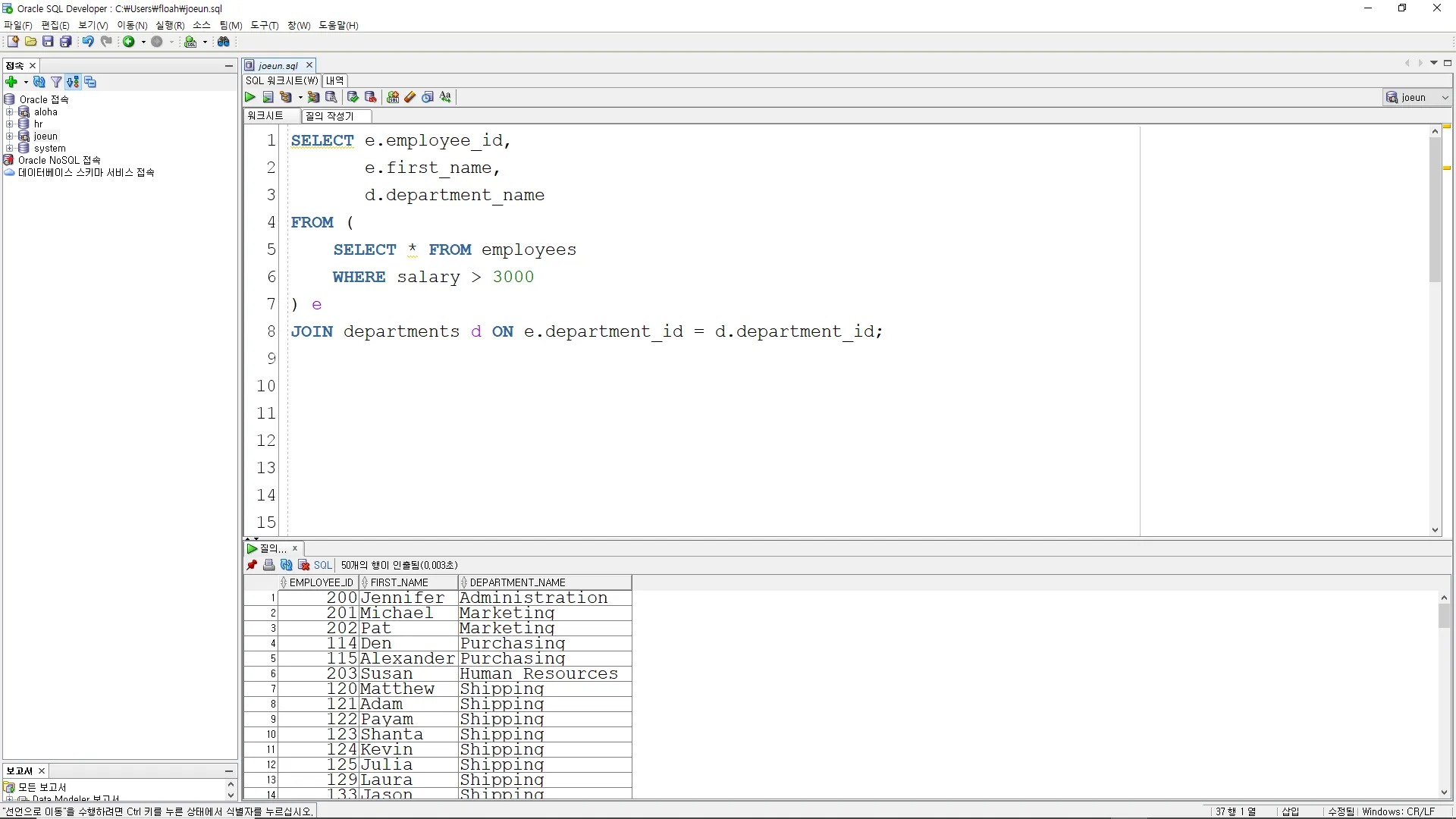
인라인 뷰
인라인 뷰를 사용하여 급여가 3000 이상인 사원의 정보를 조회하되, 부서 테이블과 조인하여 부서의 부서명을 함께 출력하시오.
SELECT e.employee_id,
e.employee_name,
d.department_name
FROM (
SELECT * FROM employees
WHERE salary > 3000
) e
JOIN departments d ON e.department_id = d.department_id;
SQL
복사
1.
내부에서는 급여가 3000 이상인 모든 사원을 선택하는 서브쿼리가 실행됩니다.
2.
이 서브쿼리의 결과는 e라는 별칭으로 사용됩니다.
3.
메인 쿼리에서는 선택된 사원들(e)과 부서 테이블(departments)을 조인합니다.
4.
이때, 사원 테이블(e)의 부서 ID와 부서 테이블(d)의 부서 ID를 기준으로 조인합니다.
5.
조인 결과로는 사원의 사원 번호(employee_id), 사원명(employee_name), 그리고 해당 부서의 부서명(department_name)이 선택됩니다.
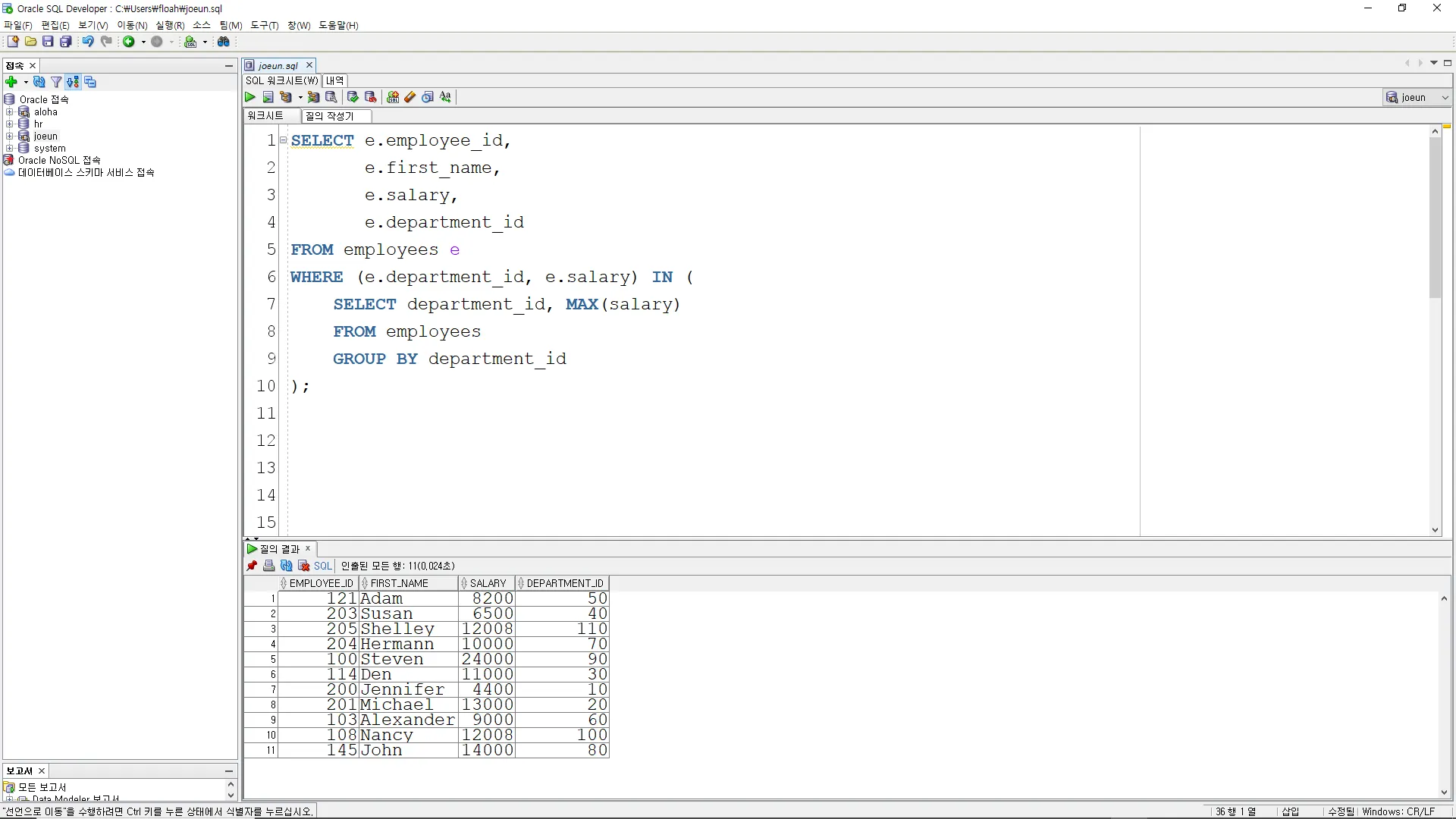
서브쿼리
서브쿼리를 사용하여 각 부서별로 가장 높은 급여를 가진 사원들의 부서 ID와 최대 급여를 조회하시오.
SELECT e.employee_id,
e.employee_name,
e.salary,
e.department_id
FROM employees e
WHERE (e.department_id, e.salary) IN (
SELECT department_id, MAX(salary)
FROM employees
GROUP BY department_id
);
SQL
복사
1.
메인 쿼리에서는 직원 테이블(employees)을 기준으로 시작합니다.
2.
WHERE 절에서는 다음을 수행합니다:
•
서브쿼리를 사용하여 각 부서별로 가장 높은 급여를 조회합니다. 이를 위해 직원 테이블을 부서별로 그룹화하고 각 그룹에서 최대 급여를 찾습니다.
•
메인 쿼리에서는 부서별로 가장 높은 급여를 받는 직원들의 부서 ID와 급여를 선택합니다.
•
이를 위해 메인 쿼리의 직원 테이블에서 (부서 ID, 급여) 쌍이 서브쿼리의 결과와 일치하는 행을 선택합니다.
3.
선택된 행에는 사원 번호(employee_id), 사원명(employee_name), 급여(salary), 그리고 부서 ID(department_id)가 포함됩니다.
이 쿼리의 결과로는 각 부서별로 가장 높은 급여를 받는 직원들의 정보만이 선택됩니다.
조인 (JOIN)
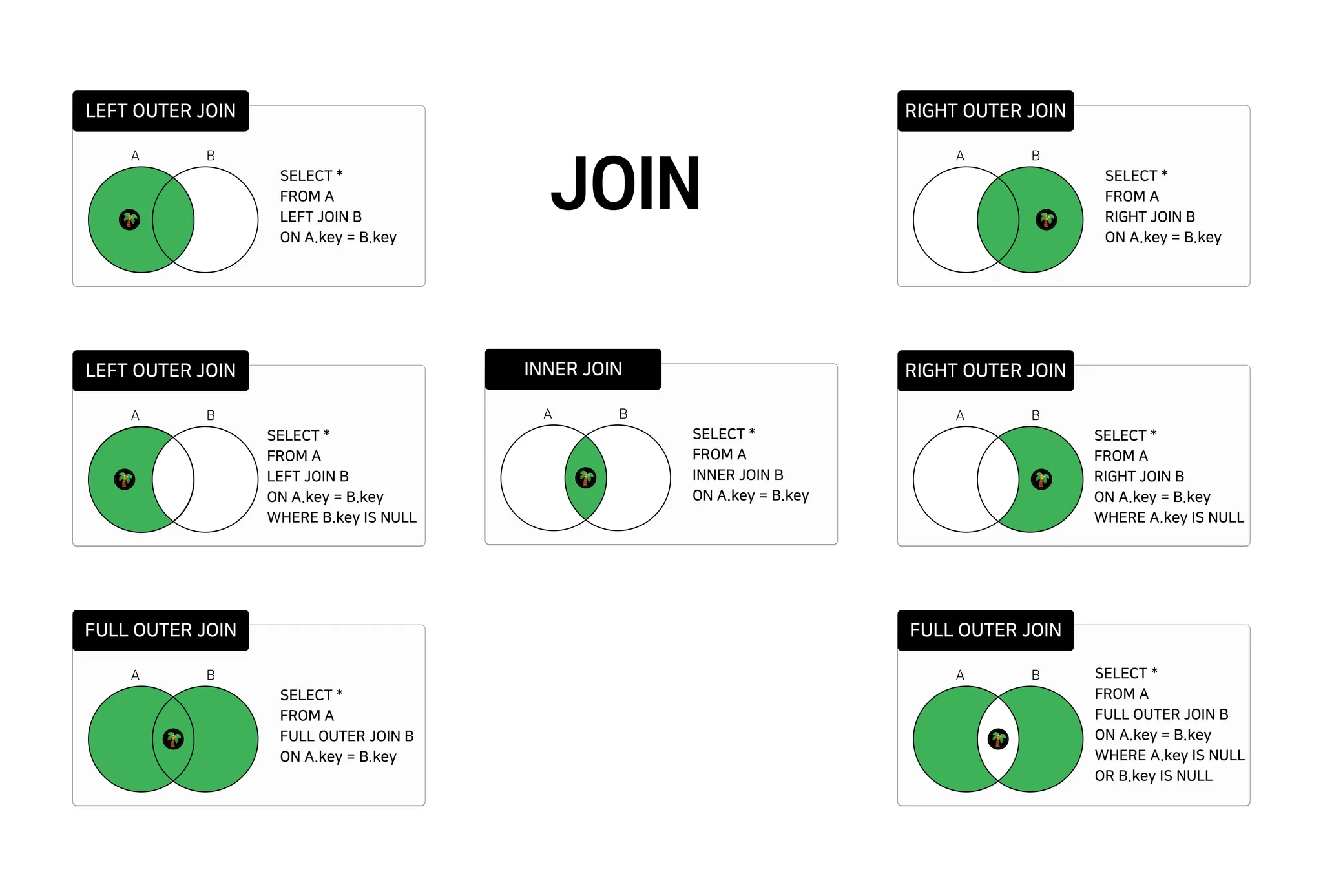
여러 테이블을 조합하여 조회하는 방식
조인 종류
•
내부조인
◦
동등 조인
◦
세미 조인
◦
안티 조인
◦
셀프 조인
•
외부조인
◦
(+)
◦
ANSI 조인
▪
LEFT OUTER JOIN
▪
RIGTH OUTER JOIN
▪
FULL OUTER JOIN
▪
CROSS JOIN (카타시안 조인)
내부 조인 (INNER JOIN)
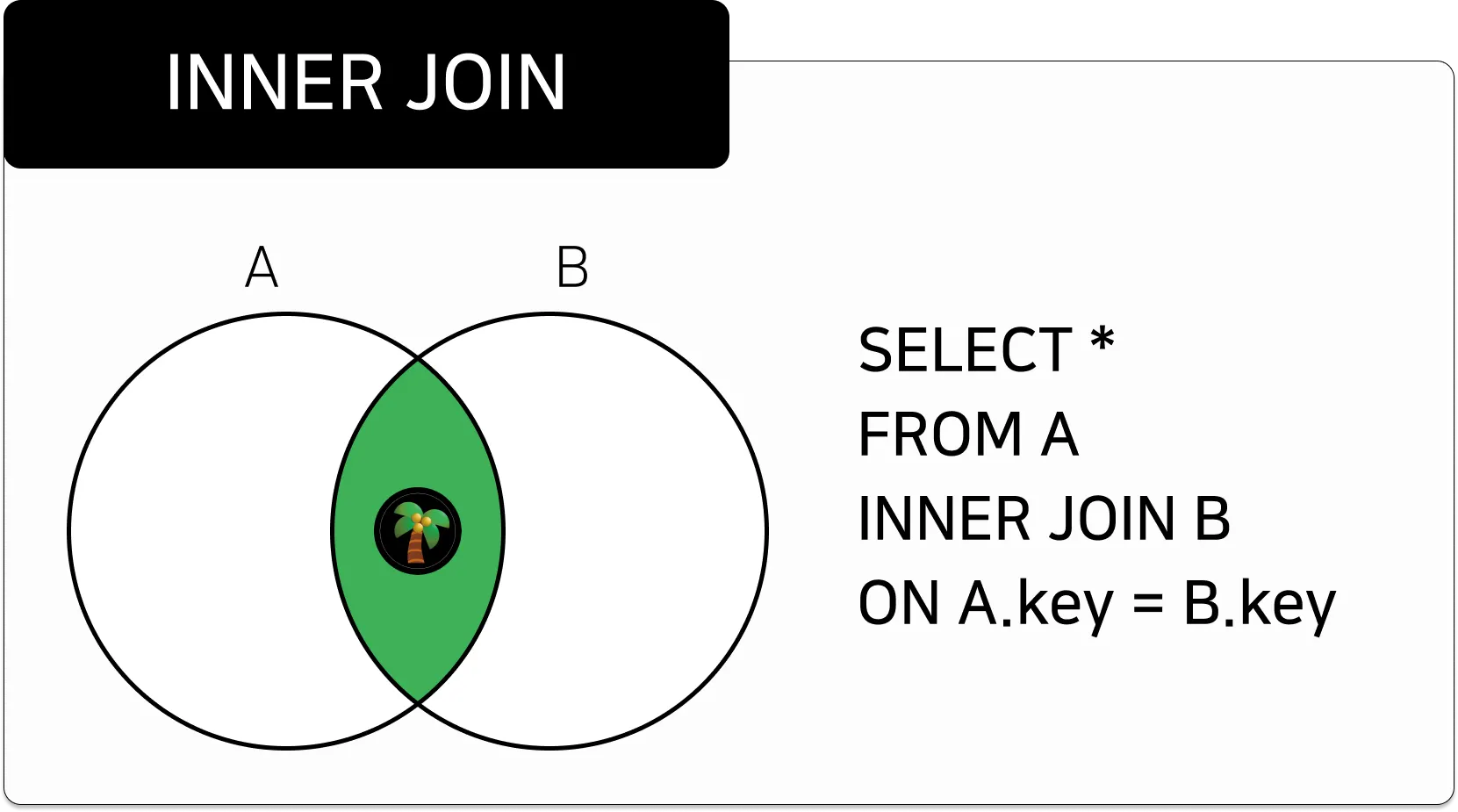
•
동등 조인
•
세미 조인
•
안티 조인
•
셀프 조인
동등 조인 (EQUI JOIN)
등호(=) 연산자를 사용하여, 2개 이상의 테이블을 연결지어 출력하는 방식
ex)
SELECT *
FROM A, B
WHERE A.x = B.y;
SQL
복사
INNER JOIN
왼쪽 테이블과 오른쪽 테이블의 조인 조건에 만족하는 교집합이 되는 데이터를 조회하는 방식
ex)
SELECT *
FROM A INNER JOIN B
ON (A.x = B.y);
SQL
복사
세미 조인 (SEMI JOIN)
서브 쿼리에 존재하는 데이터만 메인 쿼리에서 추출하여 출력하는 방식
IN 또는 EXISTS 연산자를 사용한 조인안티 조인 (ANTI JOIN)
서브 쿼리에 존재하는 데이터만 제외하고 메인 쿼리에서 추출하여 출력하는 방식
셀프 조인 (SELF JOIN)
동일한 하나의 테이블을 2번이상 조합하여 출력하는 방식
외부 조인 (OUTER JOIN)
•
LEFT OUTER JOIN
•
RIGTH OUTER JOIN
•
FULL OUTER JOIN
•
CROSS JOIN (카타시안 조인)
LEFT OUTER JOIN
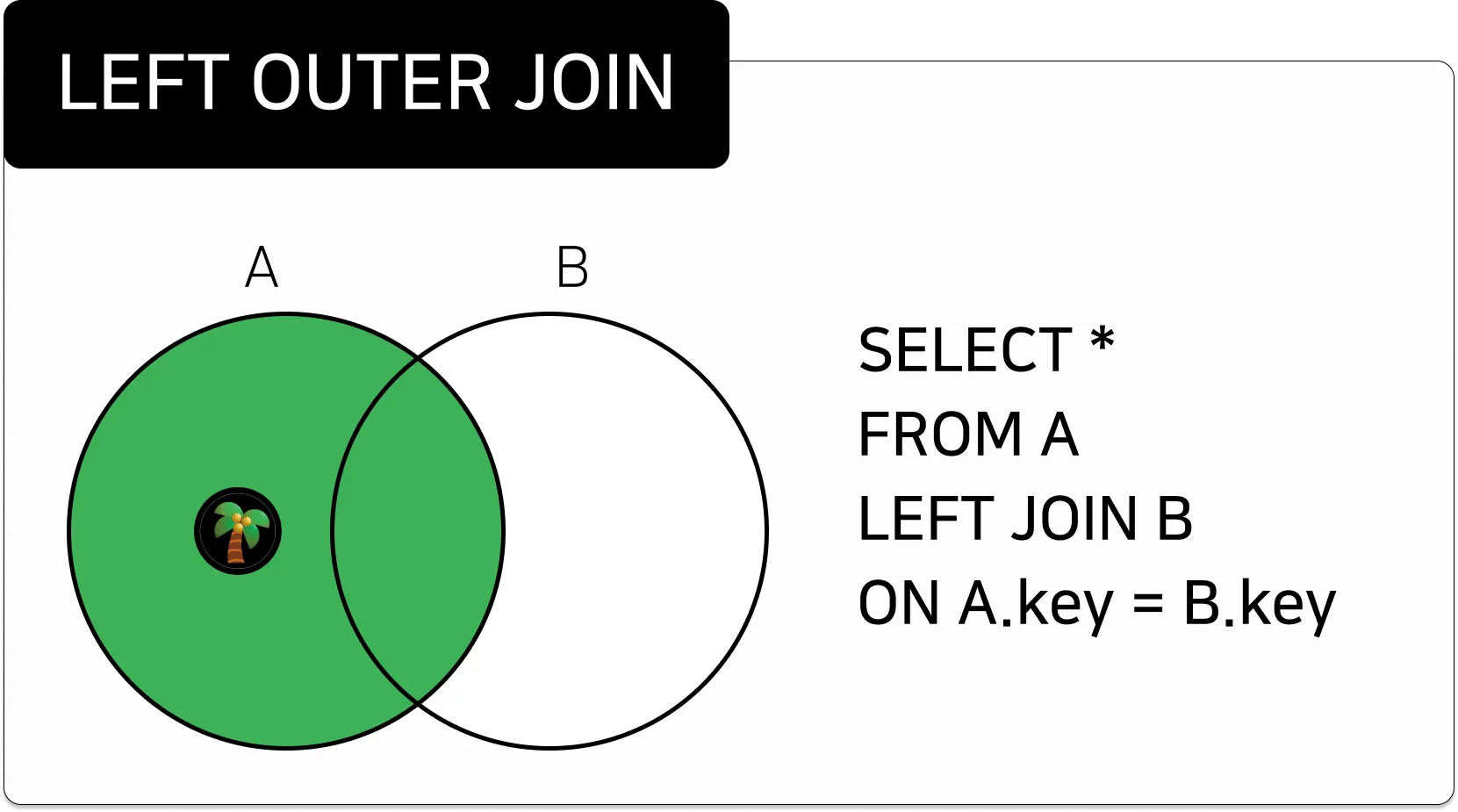
왼쪽 테이블을 먼저 읽어드린 후,
조인 조건에 일치하는 오른쪽 테이블을 함께 조회하는 것
조건에 만족하지 않는, 오른쪽 테이블의 데이터는 NULL 로 조회된다.1.
ANSI
테이블1 A LEFT [OUTER] JOIN 테이블2 B ON 조인조건;
SQL
복사
2.
(+)
WHERE A.공통컬럼 = B.공통컬럼(+)
SQL
복사
RIGHT OUTER JOIN
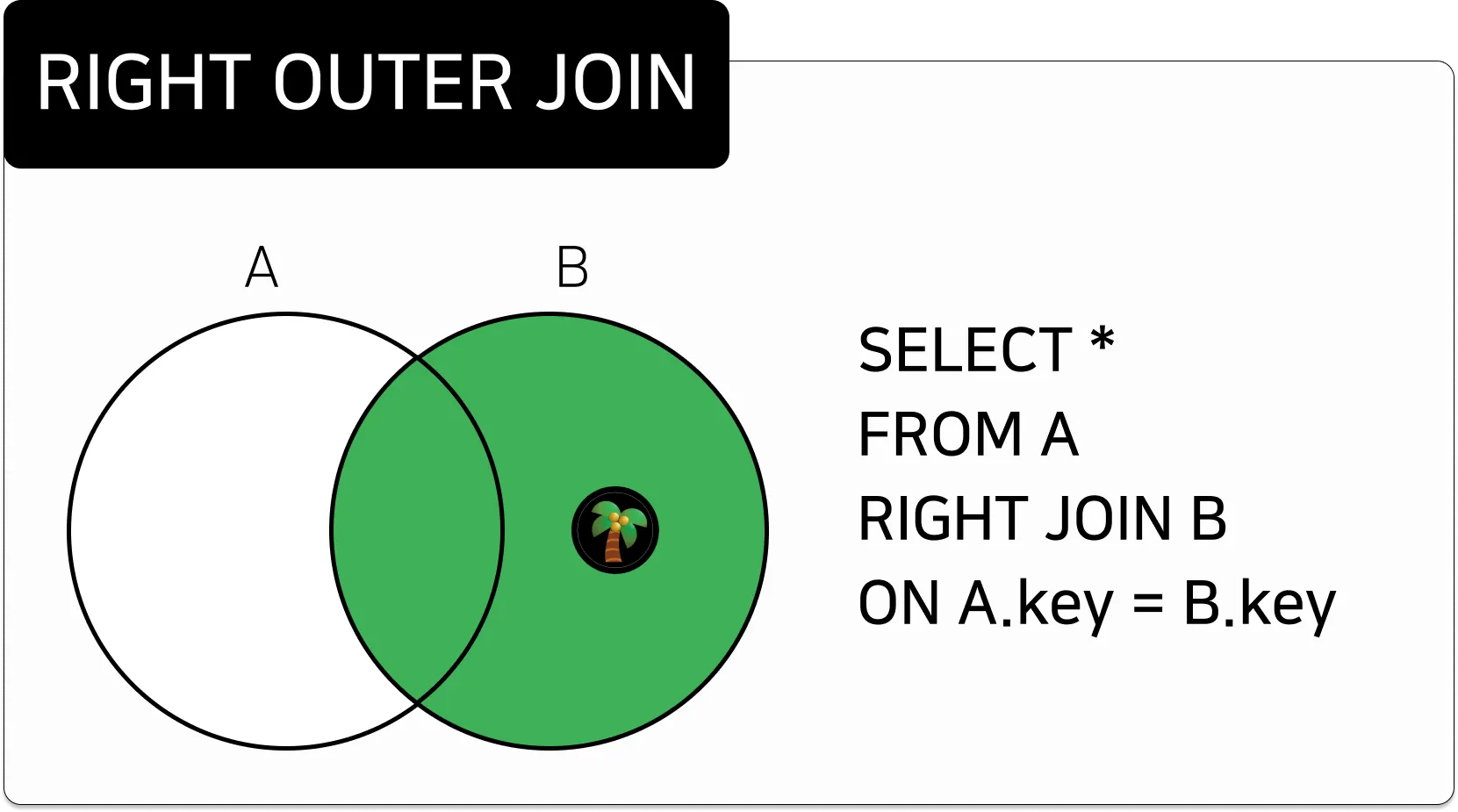
오른쪽 테이블을 먼저 읽어드린 후,
조인 조건에 일치하는 왼쪽 테이블을 함께 조회하는 것
조건에 만족하지 않는, 왼쪽 테이블의 데이터는 NULL 로 조회된다.1.
ANSI
테이블1 A RIGHT [OUTER] JOIN 테이블2 B ON 조인조건;
SQL
복사
2.
(+)
WHERE A.공통컬럼(+) = B.공통컬럼
SQL
복사
FULL OUTER JOIN
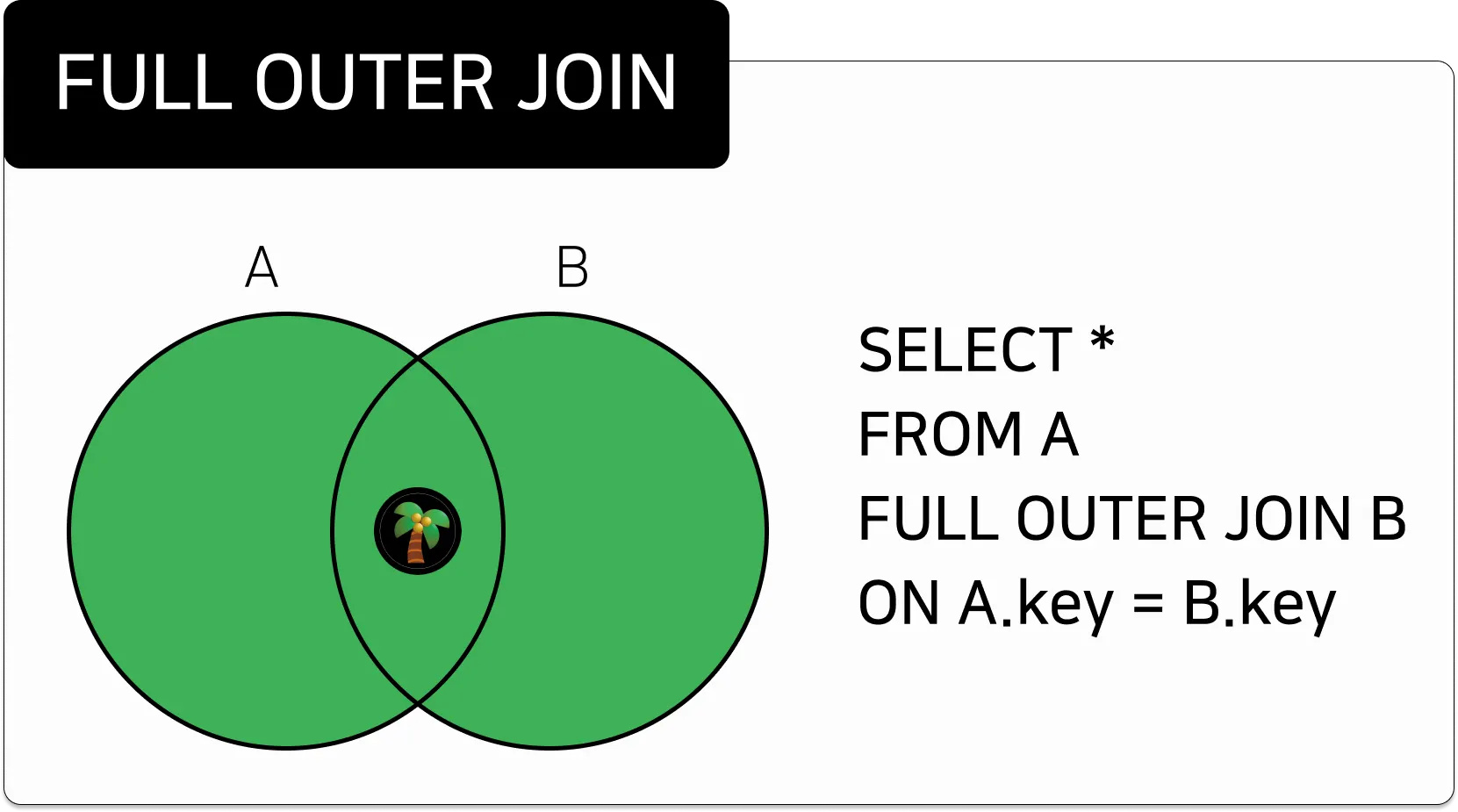
조인 조건에 일치하는 양쪽 테이블의 데이터를 조합하여 조회하는 것
조건에 만족하지 않는, 양쪽에 데이터는 NULL 로 조회된다.테이블1 A FULL [OUTER] JOIN 테이블2 B ON 조인조건;
SQL
복사
카타시안 조인 (Cartesian; CATASIAN PRODUCT) : CROSS 조인
WHERE 절에 조인 조건이 없는 조인
•
A 테이블의 데이터 건수 : X
•
B 테이블의 데이터 건수 : Y
•
결과 건수 : X * Y (두 테이블의 곱)
ex) SELECT *
FROM employees e
,departments d;
SQL
복사
•
카타시안 조인을 ANSI 문법에서는 CROSS 조인이라고 한다
ex) SELECT *
FROM employees e
CROSS JOIN departments d;
SQL
복사
집합 연산자
둘 이상의 집합을 결합하거나 비교하는 데 사용되는 연산자
집합 연산자 | 설명 |
UNION | A와 B의 결과를 합집합으로 묶어줍니다. 중복 데이터는 제거됩니다. |
UNION ALL | A와 B의 결과를 합집합으로 묶어줍니다. 중복 데이터가 포함됩니다. |
MINUS | A와 B의 결과를 차집합으로 출력합니다. A에는 있지만 B에는 없는 데이터만 출력됩니다. |
INTERSECT | A와 B의 결과를 교집합으로 출력합니다. A와 B에 모두 존재하는 데이터만 출력됩니다. |
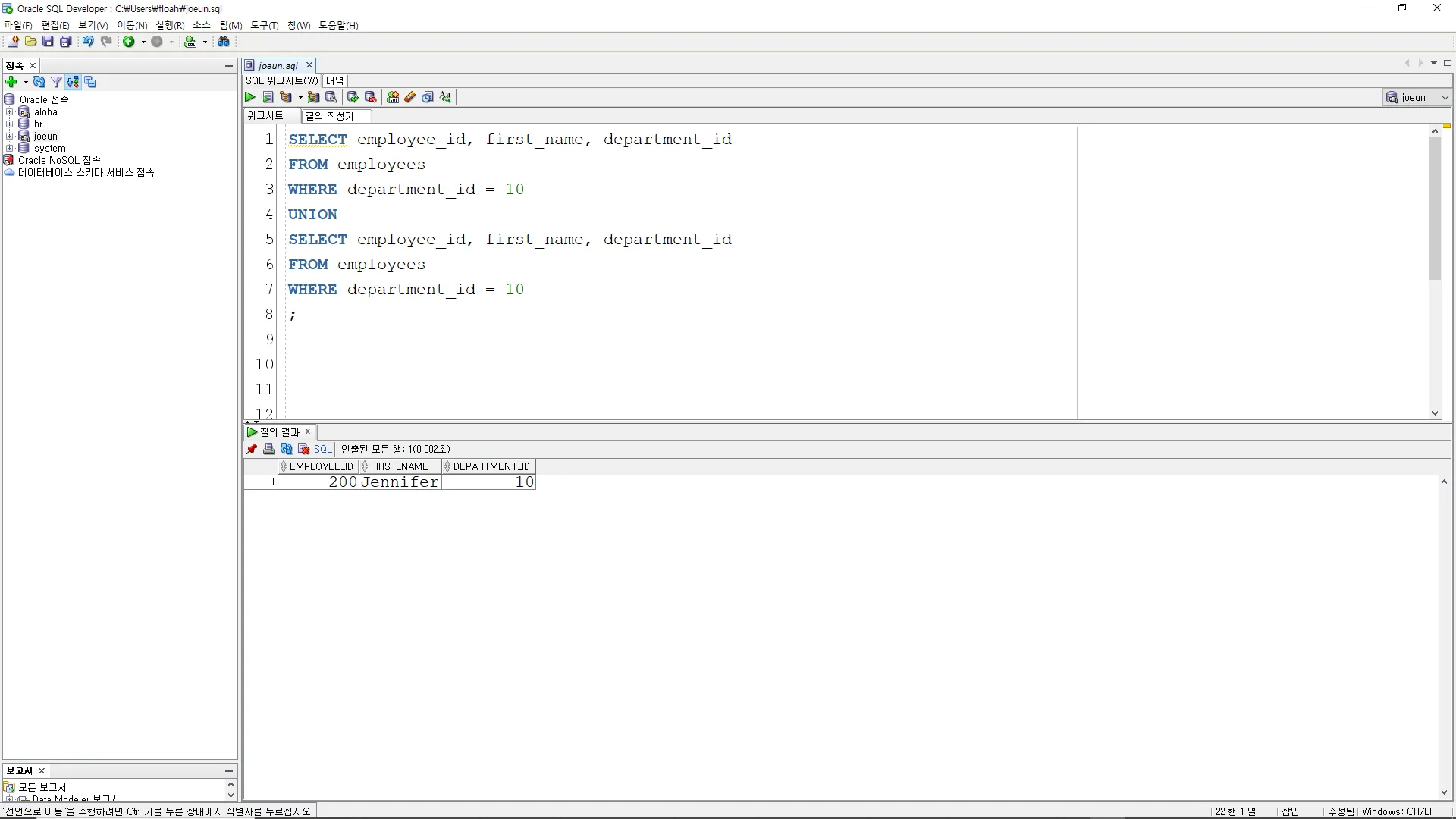
UNION
A UNION B, A와 B의 결과를 합집합을 묶는다. 중복 데이터는 제거
SELECT employee_id, first_name, department_id
FROM employees
WHERE department_id = 10
UNION
SELECT employee_id, first_name, department_id
FROM employees
WHERE department_id = 10
;
SQL
복사
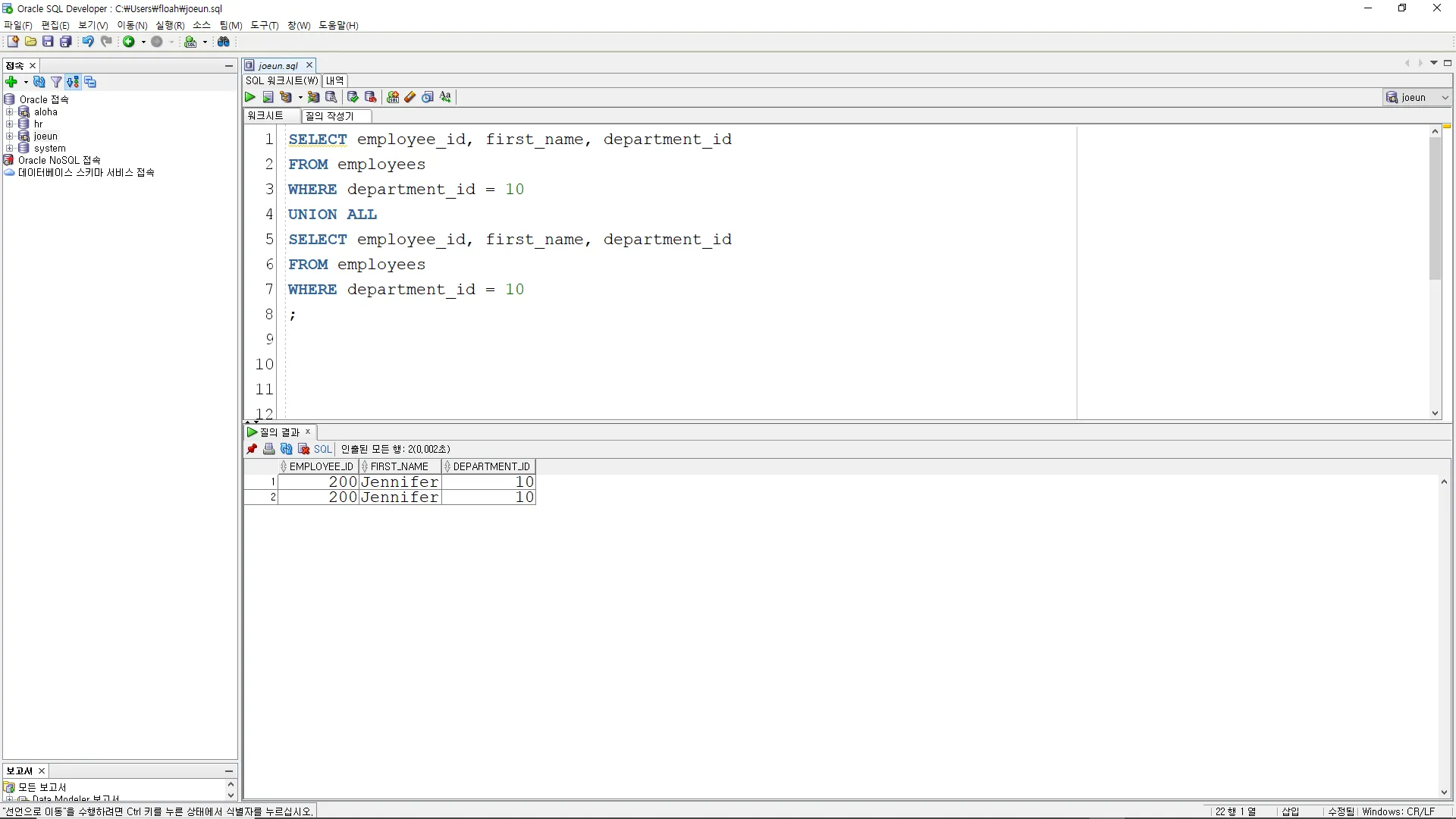
UNION ALL
A UNION ALL B, A와 B의 결과를 합집합을 묶는다. 중복 데이터 포함
SELECT employee_id, first_name, department_id
FROM employees
WHERE department_id = 10
UNION ALL
SELECT employee_id, first_name, department_id
FROM employees
WHERE department_id = 10
;
SQL
복사
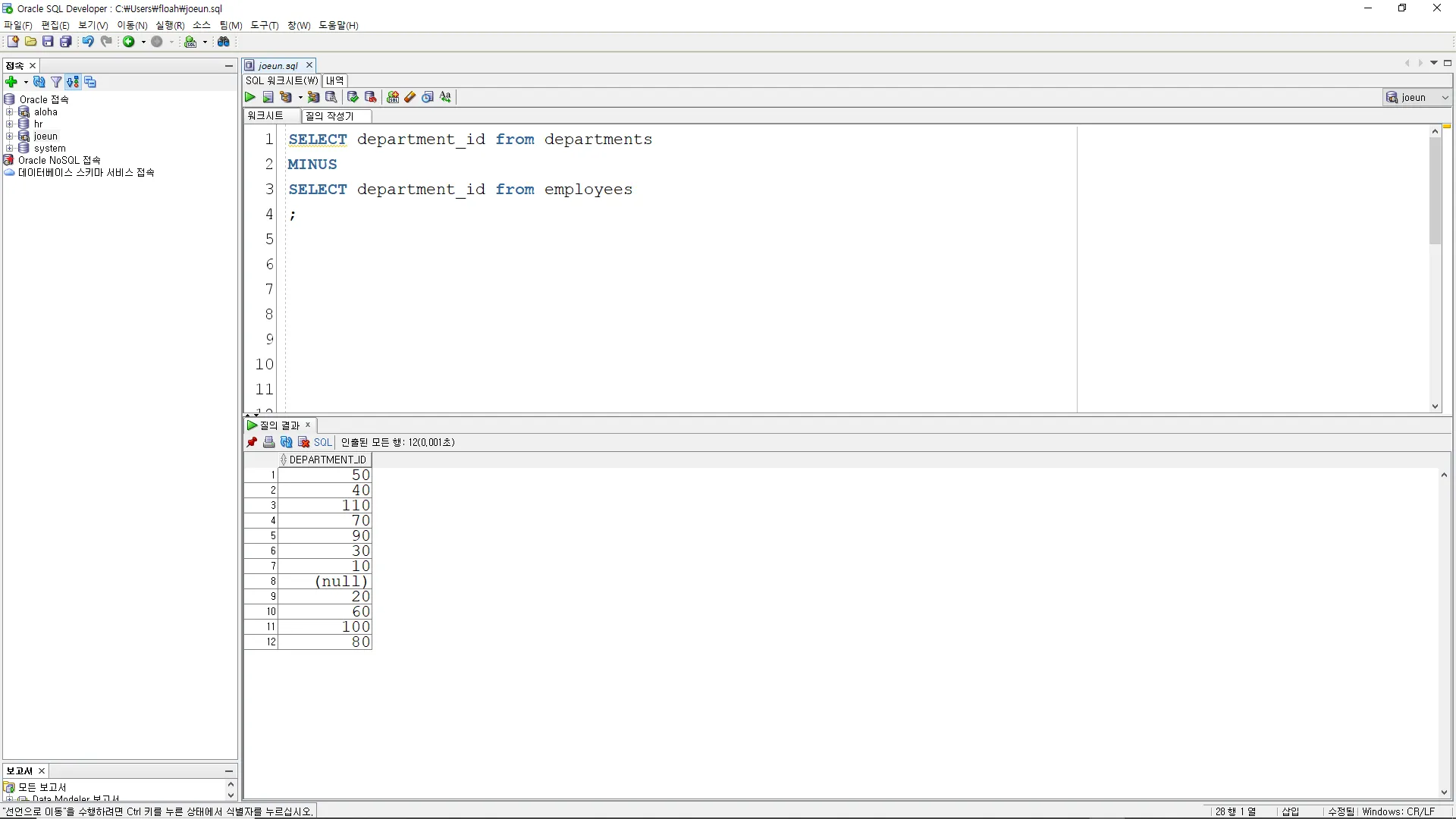
MINUS
A MINUS B, A와 B의 결과를 차집합으로 출력
사원이 없는 부서를 조회하시오.
SELECT department_id from departments
MINUS
SELECT department_id from employees
;
SQL
복사
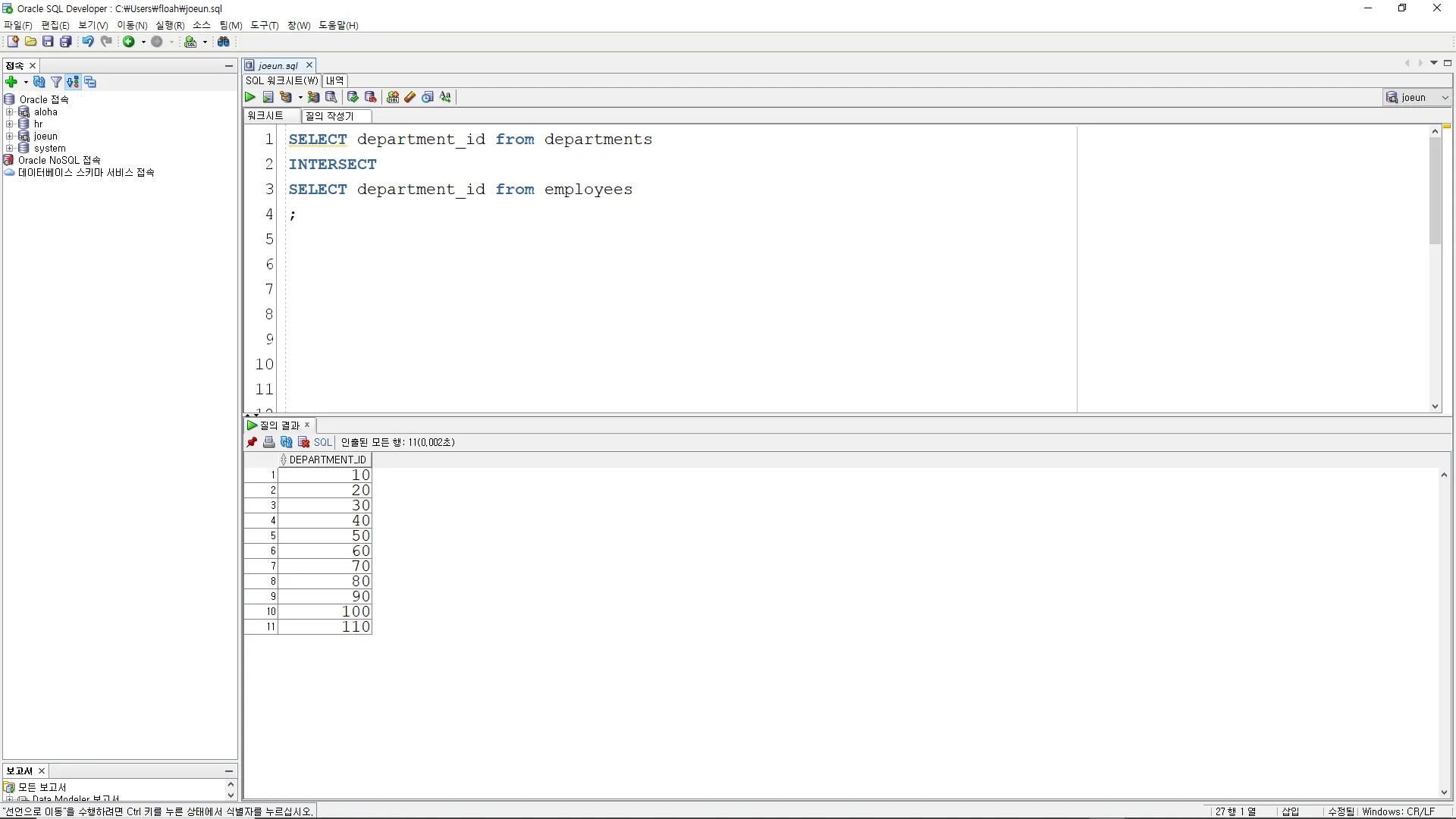
INTERSECT
A INTERSECT B, A와 B의 결과를 교집합으로 출력
사원이 있는 부서를 조회하시오.
SELECT department_id from departments
INTERSECT
SELECT department_id from employees
;
SQL
복사
그룹 함수
여러 행을 그룹화하고 각 그룹에 대해 계산을 수행하는 함수
그룹 함수 종류
•
그룹 함수
•
그룹 관련 함수
그룹 함수
함수 | 설명 |
SUM(인자) | 숫자형 컬럼인 인자 합계를 구하는 함수 |
AVG(인자) | 숫자형 컬럼인 인자 평균을 구하는 함수 |
COUNT(인자) | 조회 결과인 행의 개수를 반환하는 함수
- COUNT(*) : NULL 포함하여 개수 구함
- COUNT(컬럼) : NULL 제외하고 개수 구함 |
MAX(인자) | 숫자형/날짜형 인자의 최댓값을 구하는 함수 |
- MAX(날짜): 가장 최근의 날짜 | |
- MAX(숫자): 가장 큰 숫자 | |
MIN(인자) | 숫자형/날짜형 인자의 최솟값을 구하는 함수 |
- MIN(날짜): 가장 과거의 날짜 | |
- MIN(숫자): 가장 작은 숫자 | |
STDDEV(인자) | 숫자형 인자의 표준편차를 구하는 함수 |
VARIANCE(인자) | 숫자형 인자의 분산를 구하는 함수 |
그룹 관련 함수
함수 | 설명 |
ROLLUP(인자1, 인자2, ...) | 그룹 기준으로 집계한 정보를 레벨별로 출력하는 함수 |
CUBE(인자1, 인자2, ...) | 그룹 기준으로 집계한 정보를 가능한 모든 조합별로 출력하는 함수 |
GROUPING SETS(인자1, ...) | 그룹컬럼이 여러 개 일 때, 집계한 정보를 컬럼별로 출력하는 함수 |
GROUPING() | 그룹화한 컬럼들에 대해 그룹화된 여부를 출력하는 함수 |
LISTAGG(나열할 컬럼, [구분자]) | 그룹화된 데이터를 하나의 열에 목록으로 나열하여 출력하는 함수 |
WITHIN GROUP (ORDER BY 정렬기준 컬럼)를 사용하여 정렬 순서를 지정할 수 있습니다. | |
PIVOT() | 그룹화한 행 데이터를 열로 바꾸어서 출력하는 함수 |
UNPIVOT() | 그룹화된 결과인 열을 행 데이터로 바꾸어서 출력하는 함수 |
윈도우 함수
행과 행 간의 관계를 정의하는 함수
순위, 합계, 평균 행 위치 등 계산 결과를 사용할 수 있다.종류
•
순위 함수
•
집계 함수
•
행 순서 함수
•
비율 함수
문법 구조
SELECT 윈도우함수( 인수 )
OVER (
[PARTITION BY 컬럼1, 컬럼2, ...]
[ORDER BY 컬럼1 [ASC | DESC], 컬럼2 [ASC | DESC], ...]
[WINDOWING 절]
)
FROM 테이블;
SQL
복사
•
기본 구성 요소
구성 요소 | 설명 |
함수 | 윈도우 함수의 종류를 나타냅니다. 예를 들어, SUM(), AVG(), ROW_NUMBER() 등이 있습니다. |
OVER | 윈도우 함수를 사용하기 위한 키워드입니다. |
PARTITION BY | 선택적으로 사용됩니다.
데이터를 파티션으로 나누는 데 사용됩니다. |
ORDER BY | 선택적으로 사용됩니다. 윈도우 함수를 적용할 때 정렬 순서를 지정합니다. 기본적으로 정렬 순서는 현재 행을 중심으로 적용됩니다. |
•
WINDOWING 절
용어 | 설명 |
ROWS | ROWS 키워드는 윈도우에서 ROWS를 기준으로 범위를 지정합니다. 예를 들어, ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING은 현재 행을 중심으로 앞의 1개의 행과 뒤의 1개의 행을 포함하는 윈도우 범위를 정의합니다. |
RANGE | RANGE 키워드는 윈도우에서 값의 범위를 기준으로 범위를 지정합니다. 주로 숫자나 날짜와 같은 순서형 데이터 유형의 컬럼에 대해 사용됩니다. |
BETWEEN~AND | BETWEEN~AND 키워드는 윈도우의 범위를 지정할 때 사용됩니다. 예를 들어, ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING과 같이 사용됩니다. |
UNBOUNDED PRECEDING | UNBOUNDED PRECEDING은 윈도우의 시작을 나타내며, 현재 행보다 앞의 모든 행을 포함합니다. |
UNBOUNDED FOLLOWING | UNBOUNDED FOLLOWING은 윈도우의 끝을 나타내며, 현재 행보다 뒤의 모든 행을 포함합니다. |
CURRENT ROW | CURRENT ROW는 윈도우에서 현재 행을 나타냅니다. |
PRECEDING | 현재 행 이전에 위치한 행들 가리킵니다. |
FOLLOWING | 현재 행 이후에 위치한 행들을 가리킵니다. |
순위 함수
결과 집합 내에서 행의 순위를 결정하는 함수
함수명 | 설명 |
RANK | 동일한 값에 대한 순위를 부여하고 같은 순위에 동일한 값이 있다면 다음 순위는 건너뛰고 그 다음 순위를 부여한다. |
DENSE_RANK | 동일한 값에 대한 순위를 부여하고 같은 순위에 동일한 값이 있다면 다음 순위도 그 다음 순위와 동일한 값을 가진다. |
ROW_NUMBER | 순서대로 숫자를 부여하여 각 행에 대한 유일한 순위를 부여한다. |
순위 함수 예시 코드
•
RANK
•
DENSE_RANK
•
ROW_NUMBER
RANK
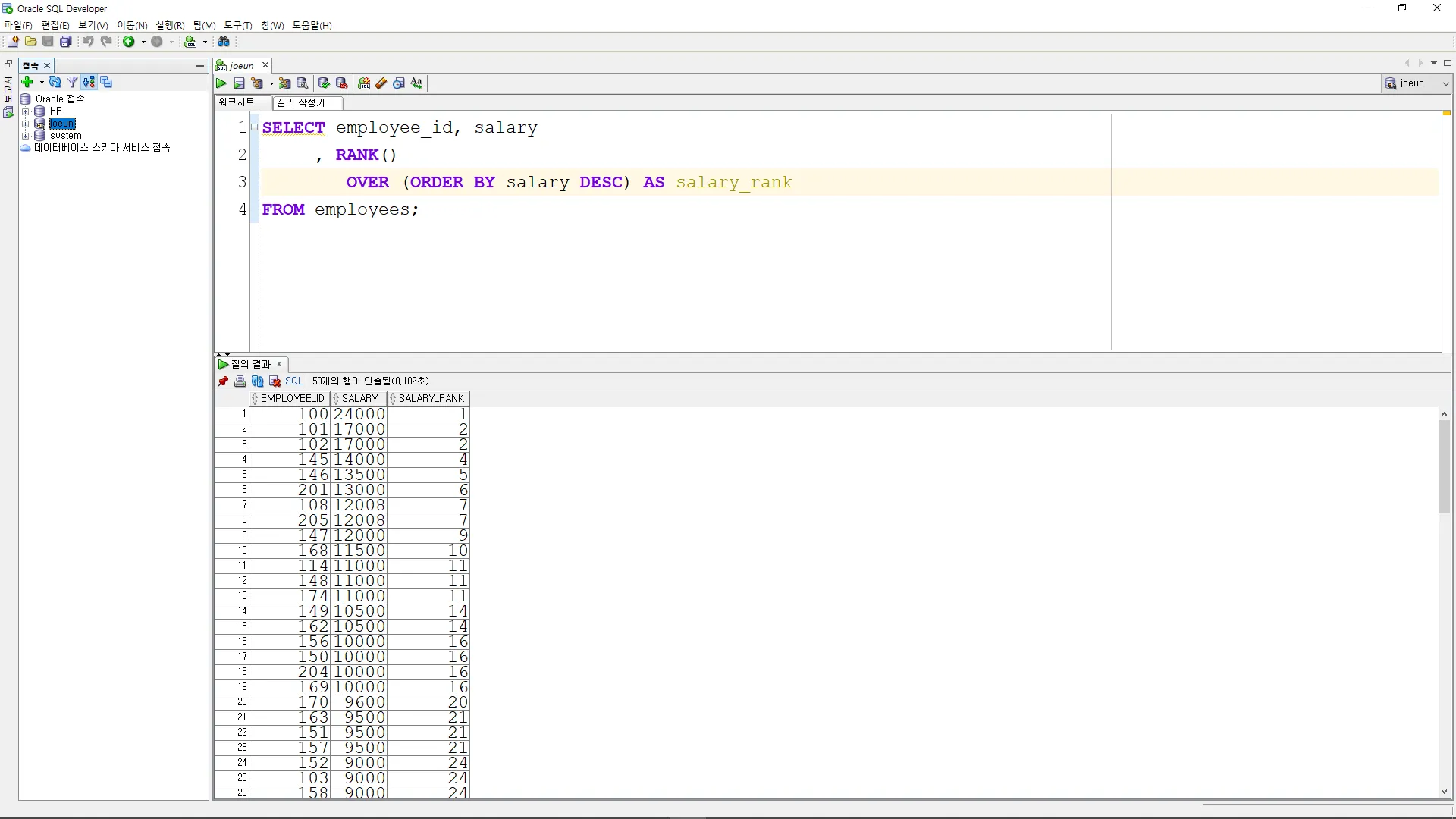
•
급여 내림차순으로 순위를 구하시오. (공동 순위면 다음 순위 없앰)
SELECT employee_id, salary
, RANK()
OVER (ORDER BY salary DESC) AS salary_rank
FROM employees;
SQL
복사
DENSE_RANK
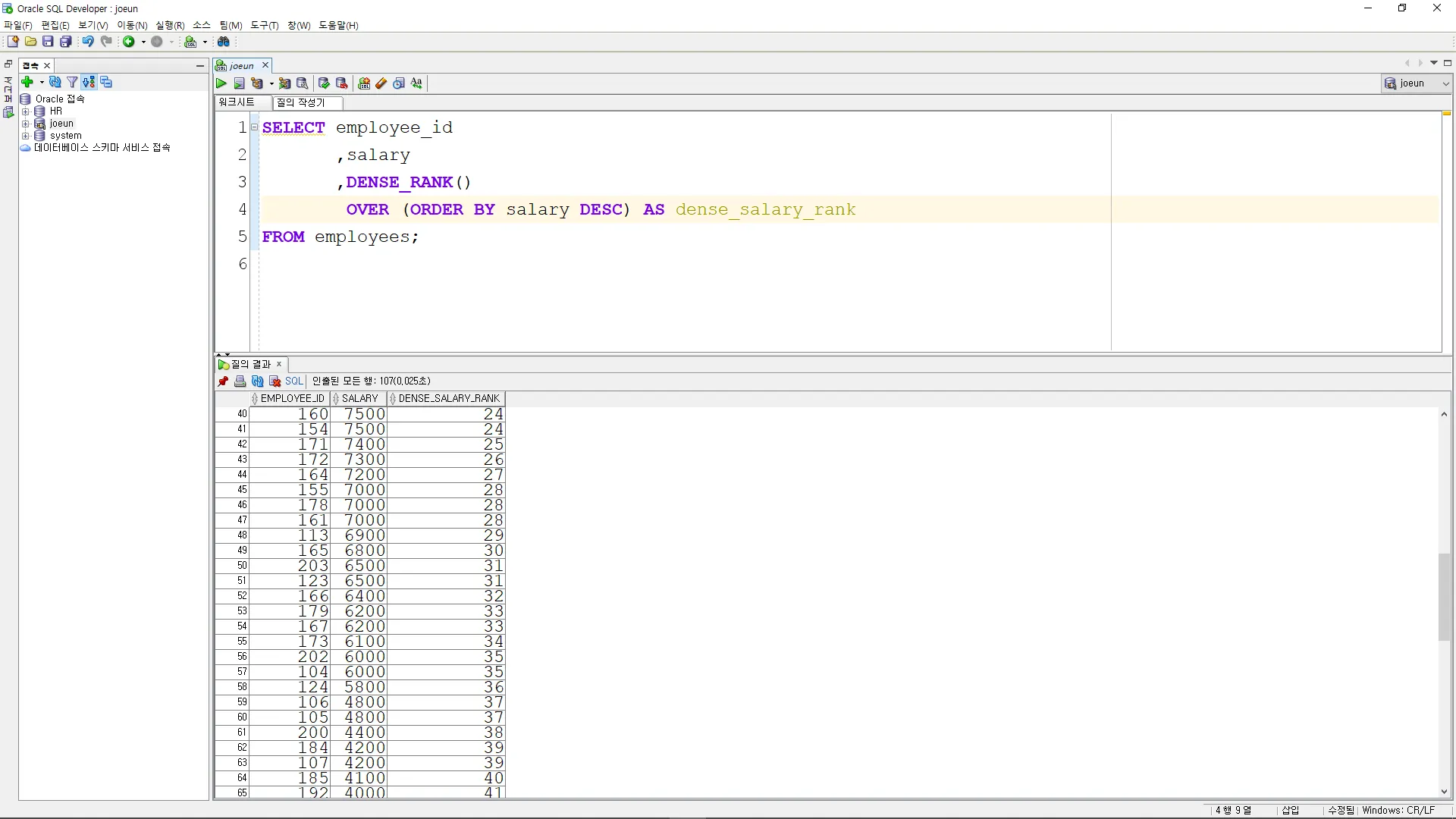
•
급여 내림차순으로 순위를 구하시오. (공동 순위가 있어도 다음 순위 살림)
SELECT employee_id
,salary
,DENSE_RANK()
OVER (ORDER BY salary DESC) AS dense_salary_rank
FROM employees;
SQL
복사
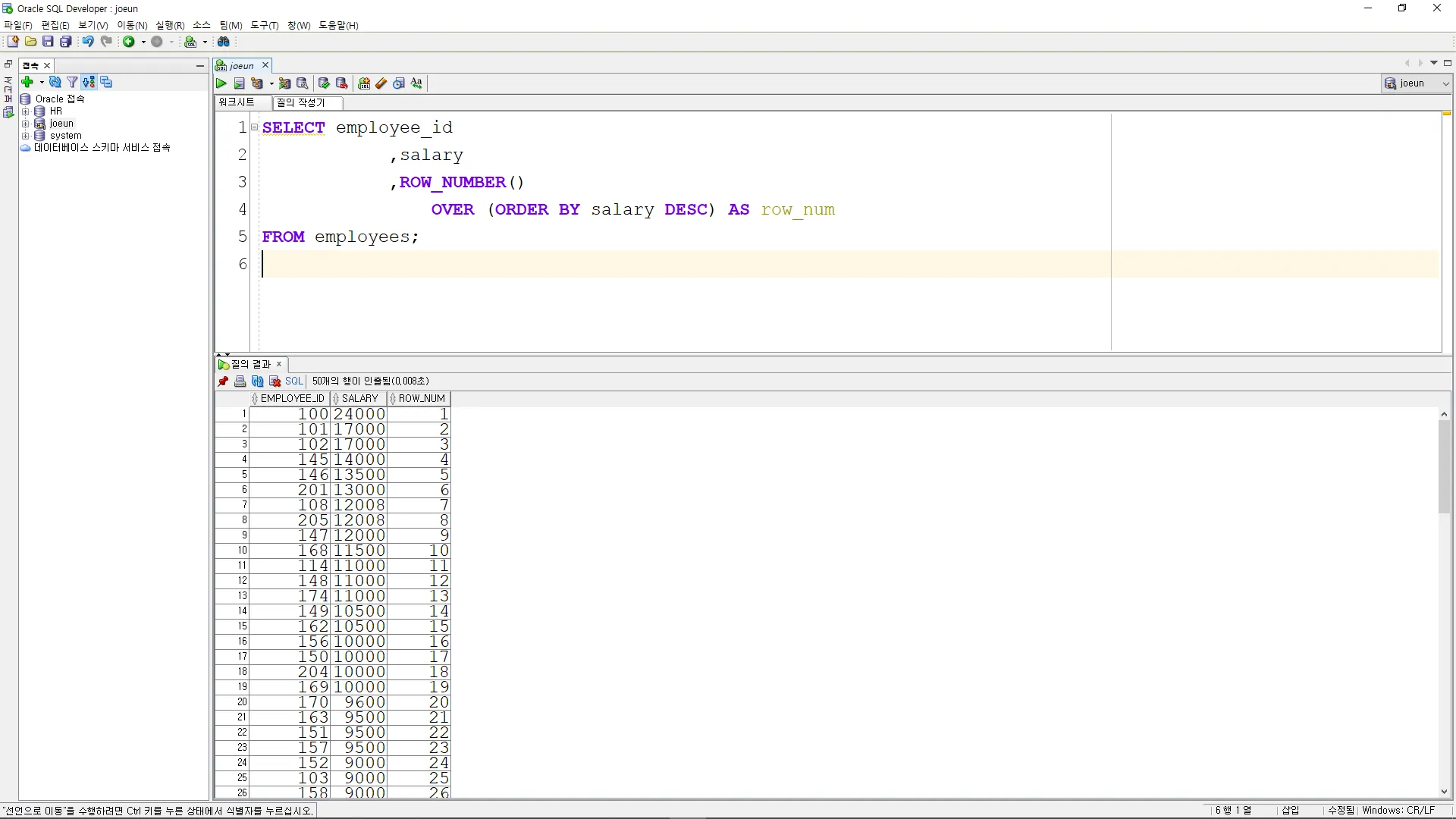
ROW_NUMBER
•
중복 순위 상관없이, 유일한 순서 번호 말 그대로 행번호를 출력
SELECT employee_id
,salary
,ROW_NUMBER()
OVER (ORDER BY salary DESC) AS row_num
FROM employees;
SQL
복사
집계 함수
여러 행의 값을 그룹화하고 집계하여 단일 결과 값을 반환하는 함수
함수명 | 설명 |
SUM | 숫자형 데이터의 합을 계산합니다. |
AVG | 숫자형 데이터의 평균을 계산합니다. |
COUNT | 결과 집합이나 그룹의 행 수를 계산합니다. |
MAX | 숫자나 날짜 데이터의 최댓값을 찾습니다. |
MIN | 숫자나 날짜 데이터의 최솟값을 찾습니다. |
집계 함수 예시 코드
•
SUM
•
AVG
•
COUNT
•
MAX
•
MIN
SUM
SELECT SUM(salary) AS total_salary
FROM employees;
SQL
복사
AVG
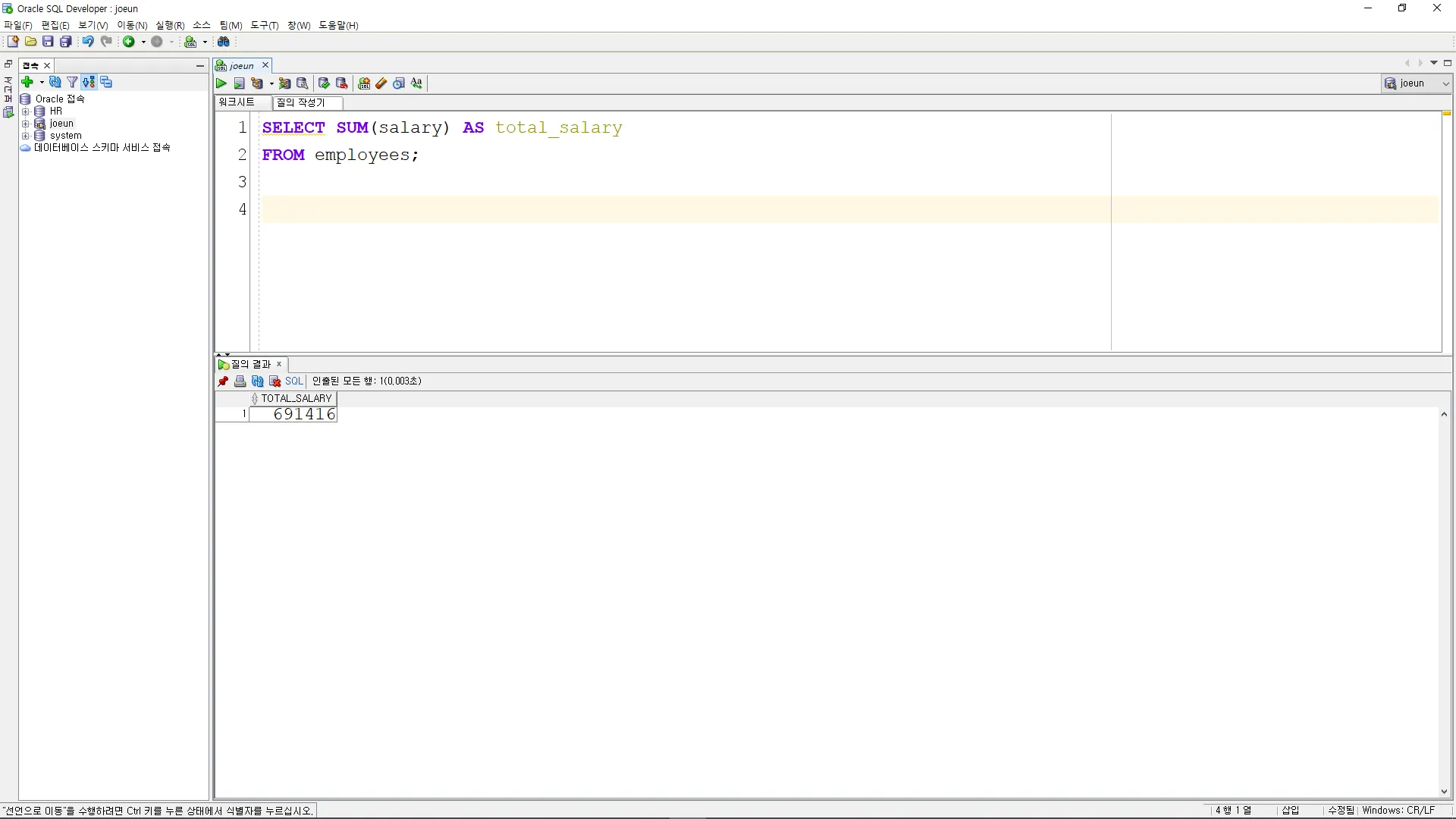
SELECT AVG(salary) AS average_salary
FROM employees;
SQL
복사
COUNT
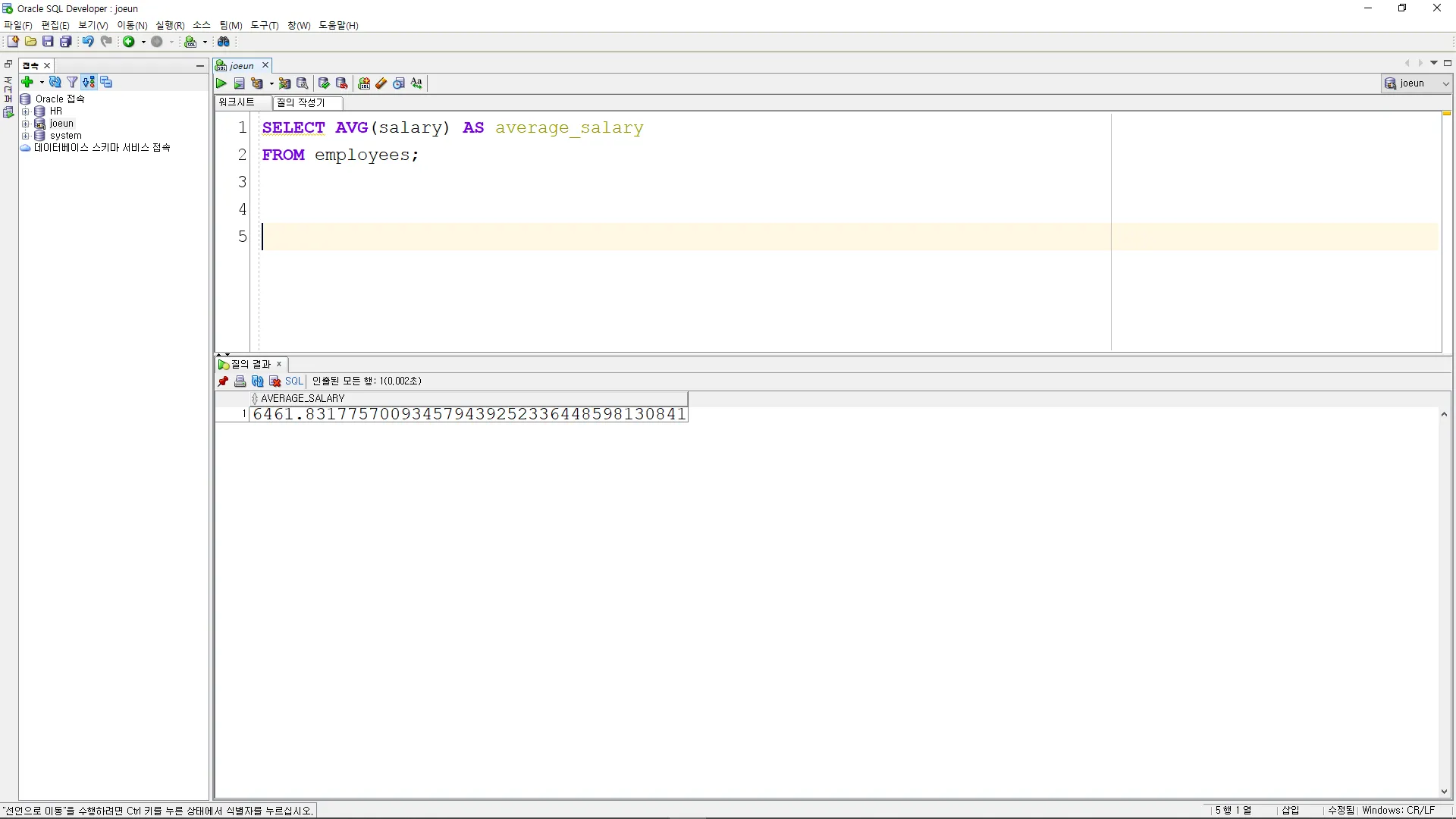
SELECT COUNT(*) AS total_employees
FROM employees;
SQL
복사
MAX
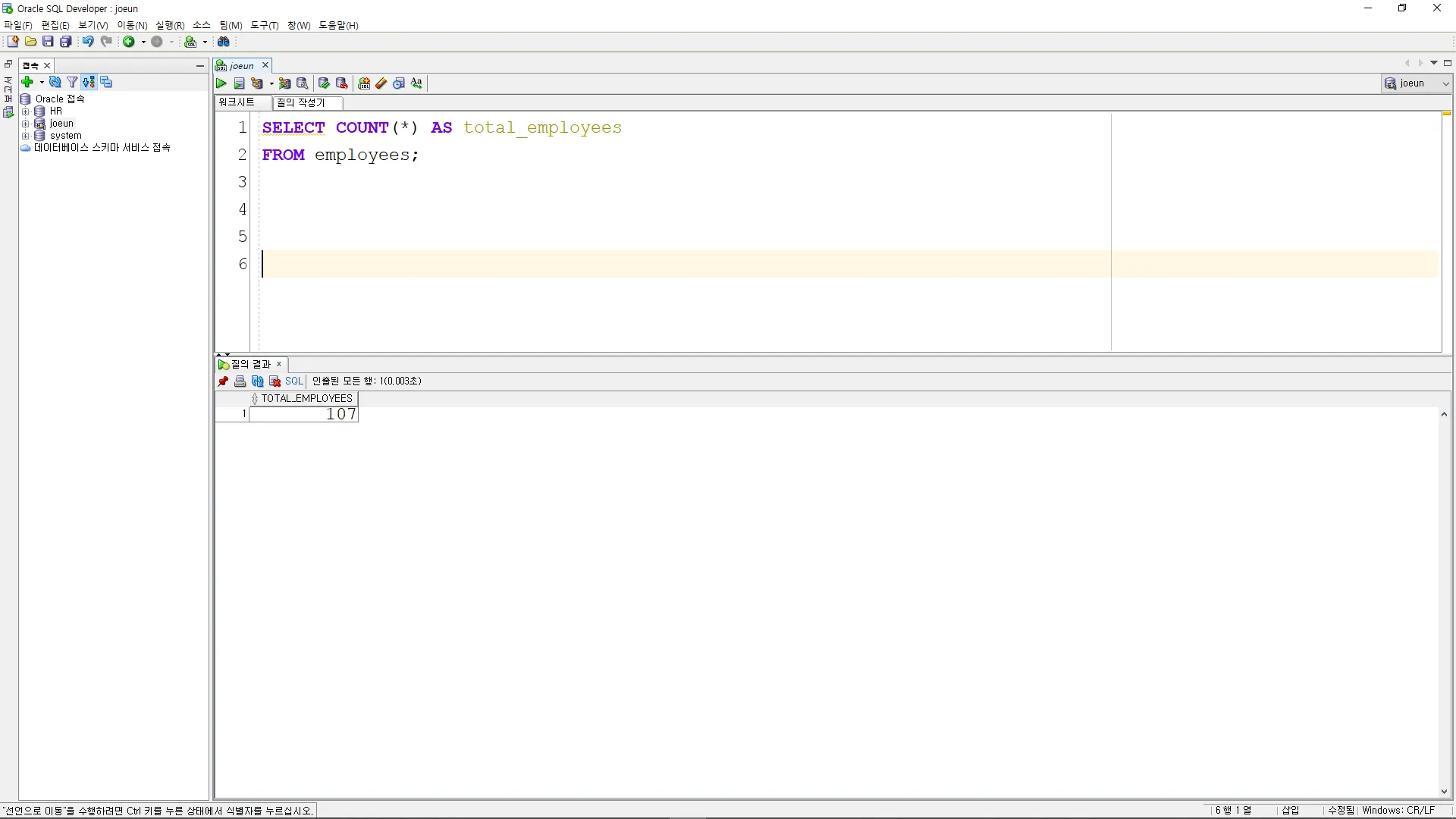
SELECT MAX(salary) AS max_salary
FROM employees;
SQL
복사
MIN
SELECT MIN(salary) AS min_salary
FROM employees;
SQL
복사
행 순서 함수
결과 집합 내에서 특정 행의 위치나 순서를 결정하는 함수
함수명 | 설명 |
FIRST_VALUE | 그룹 내에서 첫 번째 행의 값을 반환합니다. |
LAST_VALUE | 그룹 내에서 마지막 행의 값을 반환합니다. |
LAG | 현재 행 이전의 값을 가져옵니다. |
LEAD | 현재 행 다음의 값을 가져옵니다. |
행 순서 함수 예시 코드
•
FIRST_VALUE
•
LAST_VALUE
•
LAG
•
LEAD
FIRST_VALUE
•
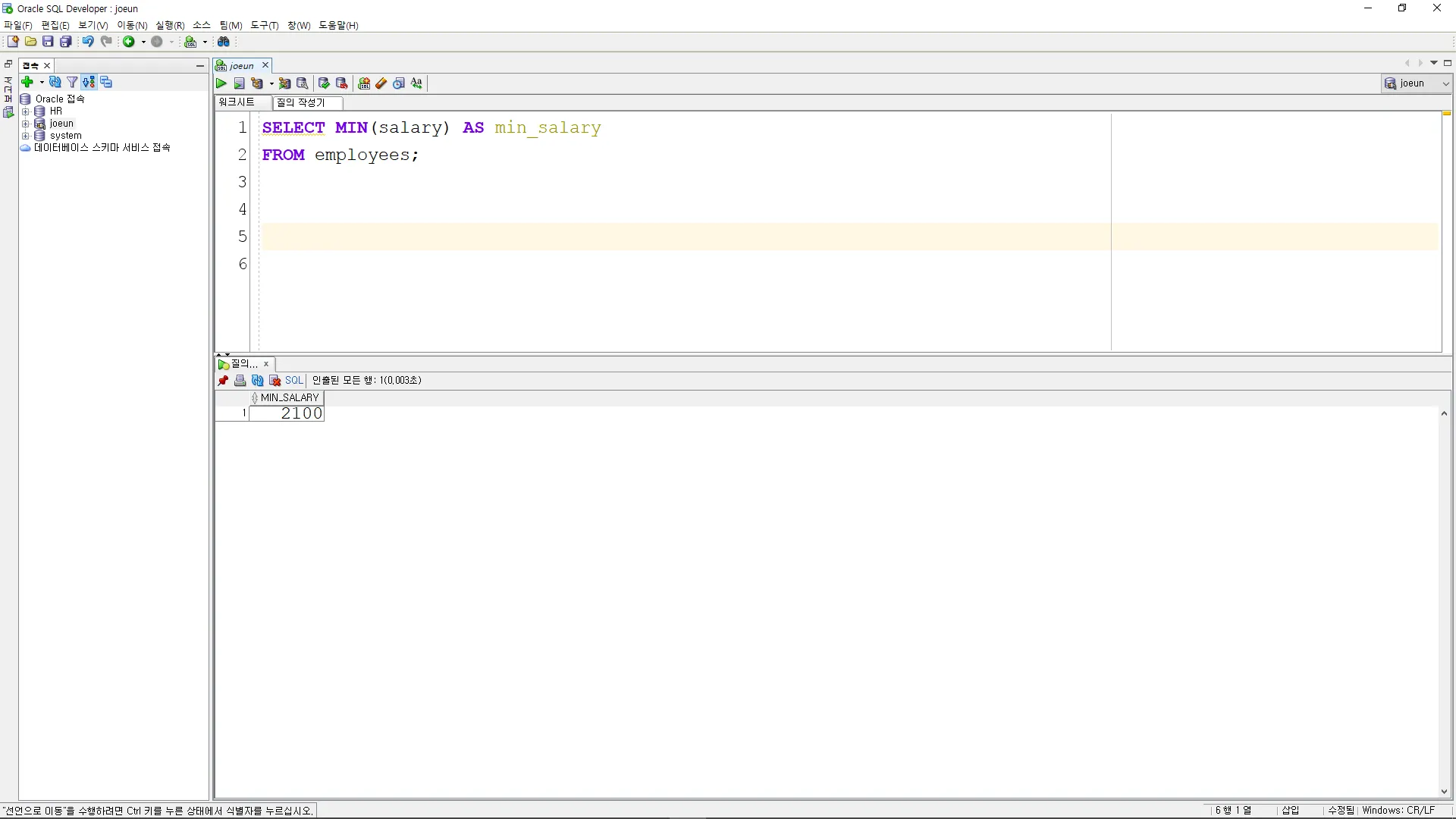
각 부서별로 첫 번째로 입사한 직원의 급여를 조회
SELECT department_id
, employee_id
, salary
,FIRST_VALUE(salary)
OVER (PARTITION BY department_id
ORDER BY hire_date) AS first_salary
FROM employees;
SQL
복사
LAST_VALUE
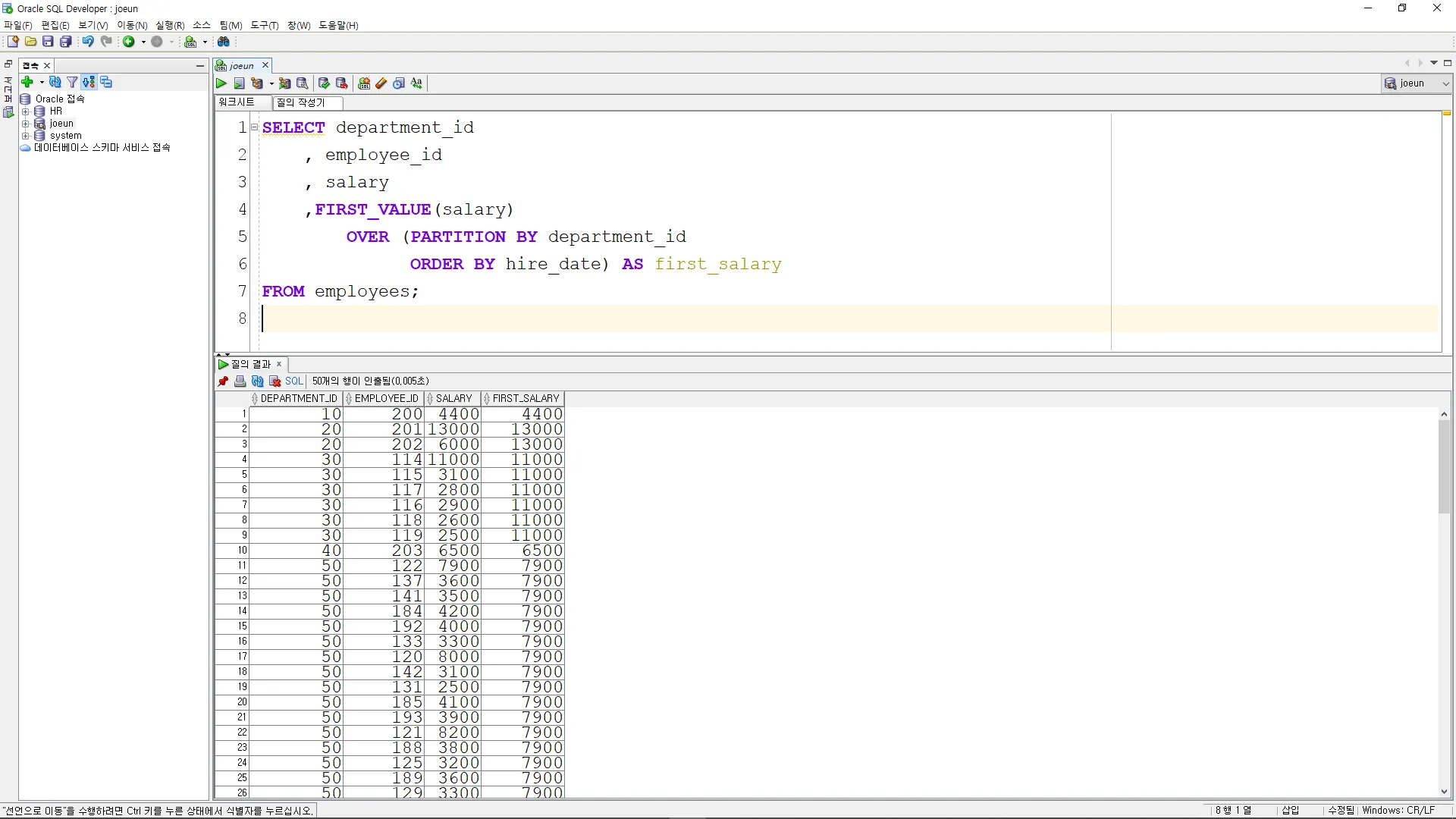
•
각 부서별로 마지막으로 입사한 직원의 급여를 조회
SELECT department_id
, employee_id
, salary
, LAST_VALUE(salary)
OVER (PARTITION BY department_id
ORDER BY hire_date
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS last_salary
FROM employees;
SQL
복사
LAG
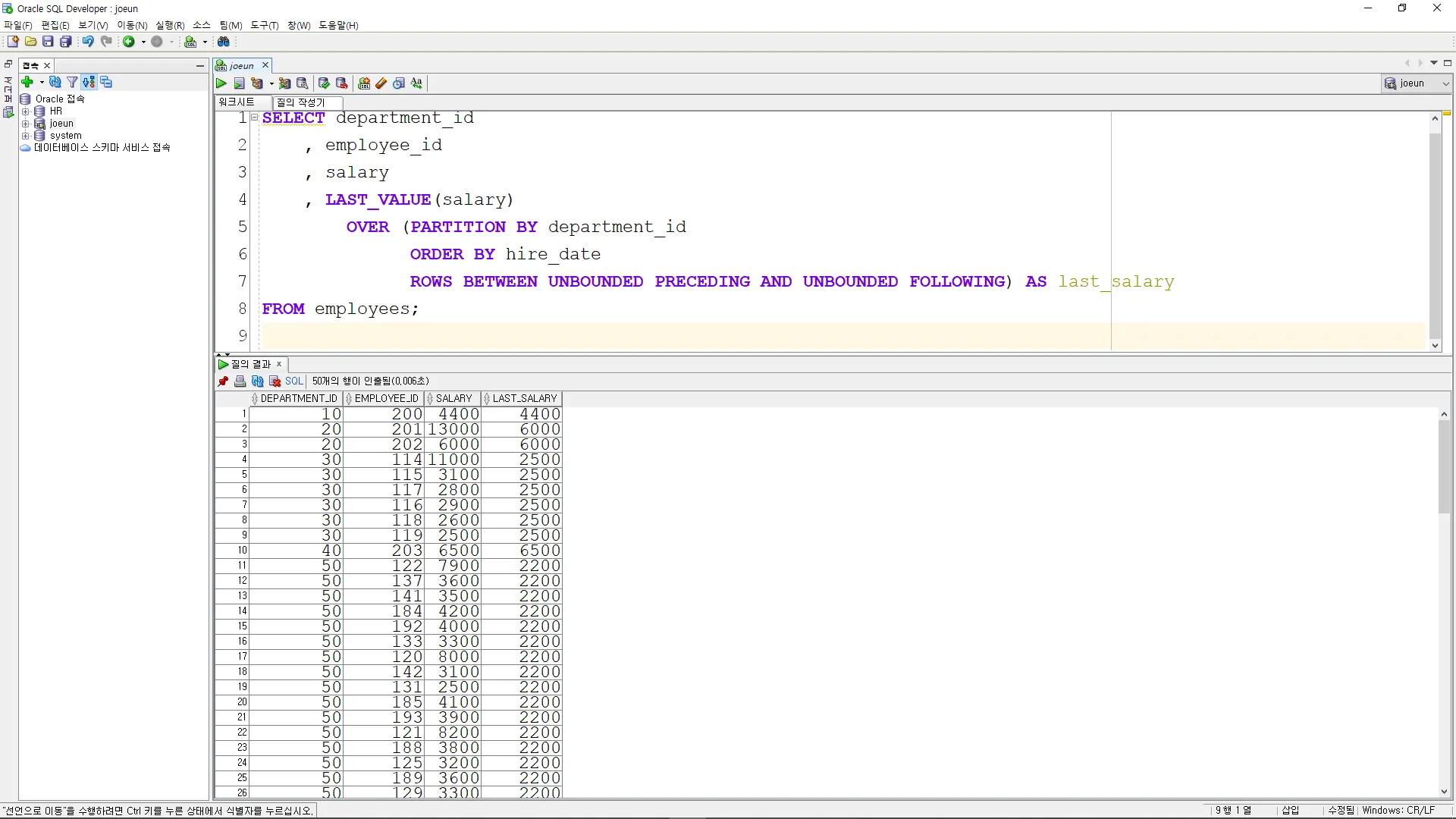
•
이전 직원의 정보를 조회
SELECT employee_id, first_name, hire_date,
LAG(first_name) OVER (ORDER BY hire_date) AS previous_name,
LAG(hire_date) OVER (ORDER BY hire_date) AS previous_hire_date
FROM employees;
SQL
복사
LEAD
•
다음 직원의 정보를 조회
SELECT employee_id, first_name, hire_date,
LEAD(first_name) OVER (ORDER BY hire_date) AS next_first_name,
LEAD(hire_date) OVER (ORDER BY hire_date) AS next_hire_date
FROM employees;
SQL
복사
비율 함수
결과 집합 내에서 특정 값의 비율이나 백분율을 계산하는 함수
함수명 | 설명 |
CUME_DIST | 결과 집합에서 현재 행의 누적 분포 값을 계산합니다. |
PERCENT_RANK | 결과 집합에서 현재 행의 백분위 순위를 계산합니다. |
NTILE | 결과 집합을 지정된 개수의 동일한 크기의 그룹으로 나누고, 각 행에 그룹 번호를 할당합니다. |
RATIO_TO_REPORT | 결과 집합의 각 그룹에서 현재 행의 비율을 계산합니다. |
비율 함수 예시 코드
•
CUME_DIST
•
PERCENT_RANK
•
NTILE
•
RATIO_TO_REPORT
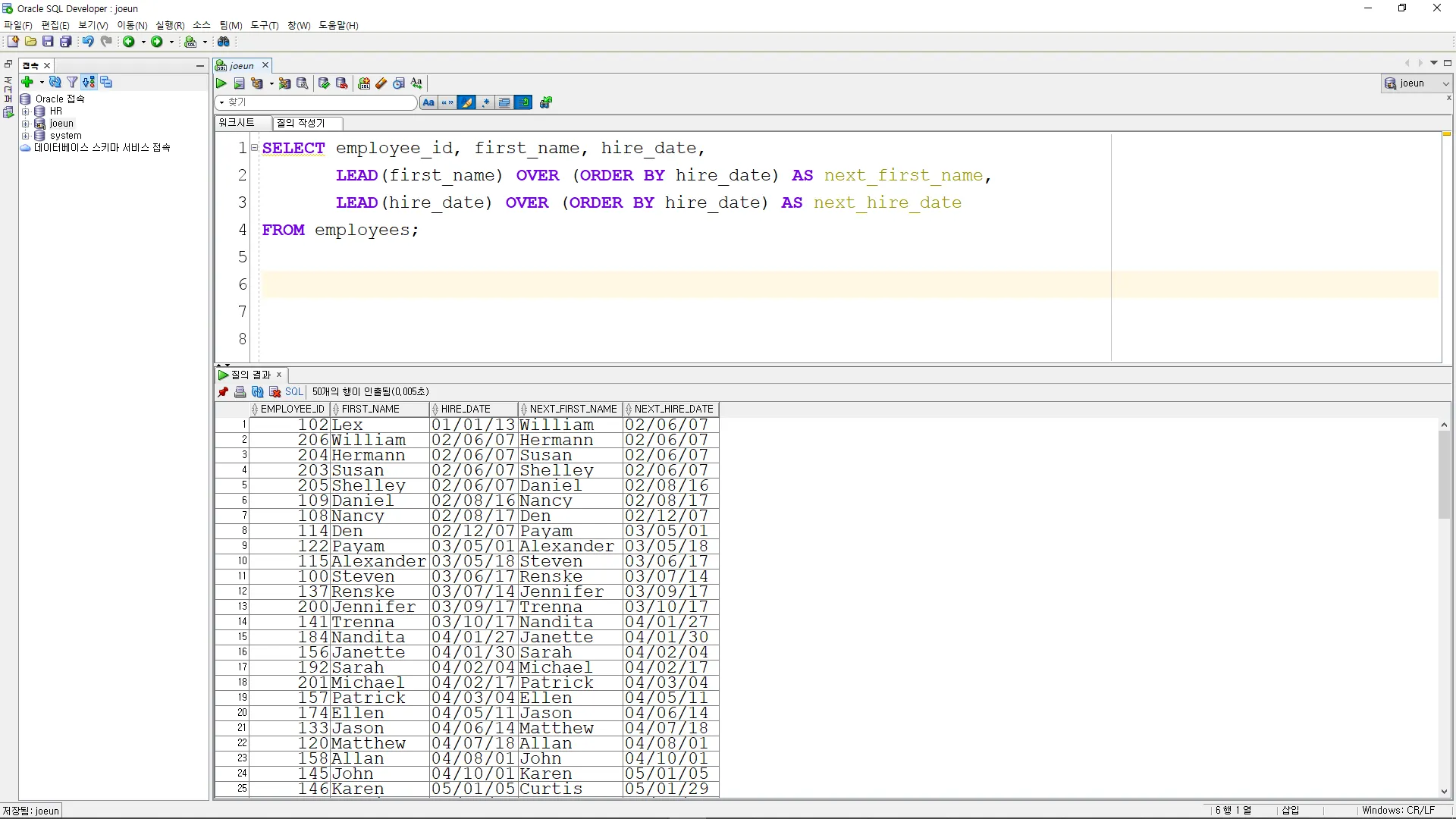
CUME_DIST
•
이 함수는 결과 집합에서 현재 행의 누적 분포 값을 계산
SELECT employee_id
, salary
, CUME_DIST()
OVER (ORDER BY salary DESC) AS cumulative_distribution
FROM employees;
SQL
복사
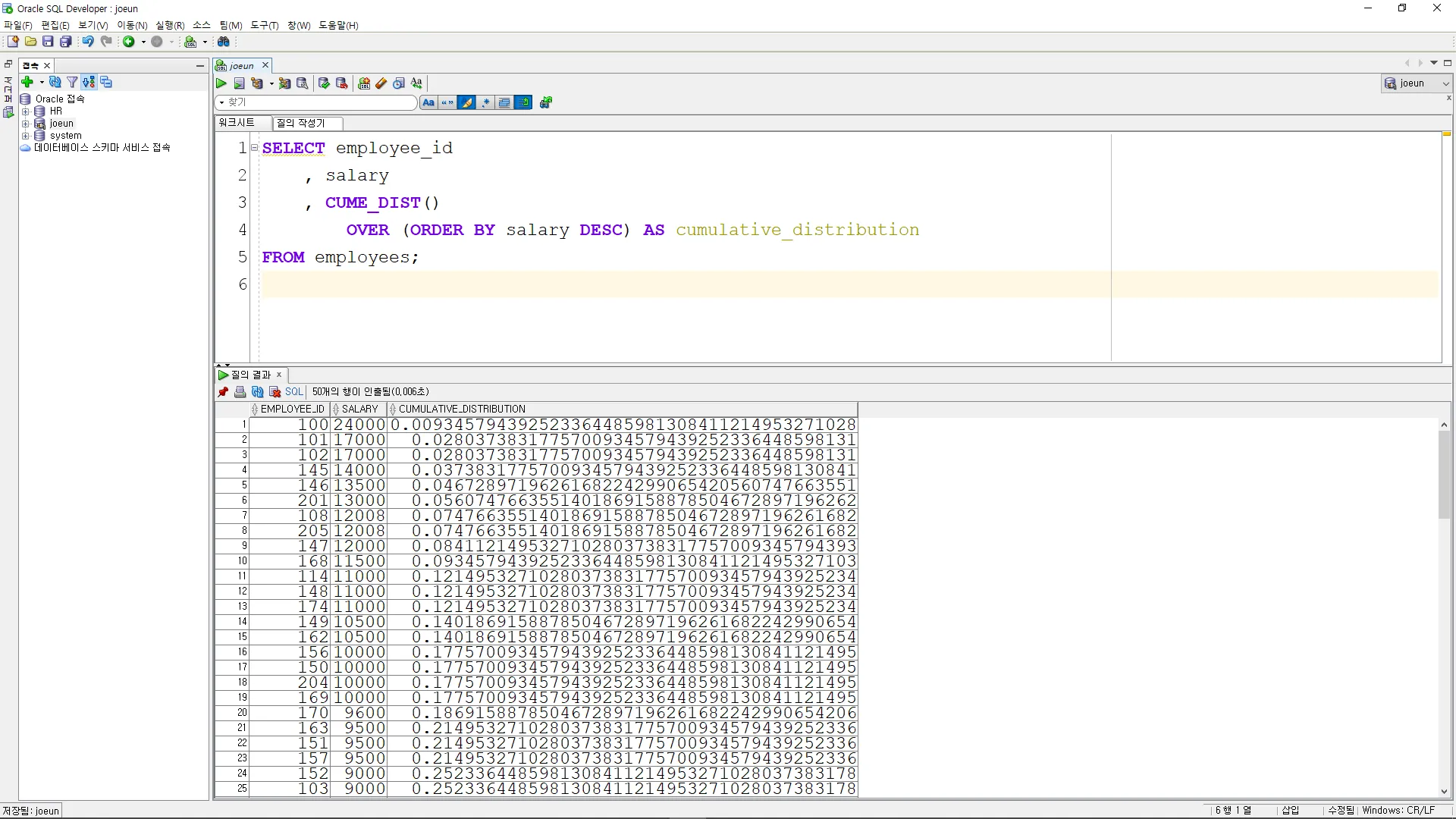
PERCENT_RANK
•
이 함수는 결과 집합에서 현재 행의 백분위 순위를 계산
SELECT employee_id
, salary
, PERCENT_RANK()
OVER (ORDER BY salary DESC) AS percent_rank
FROM employees;
SQL
복사
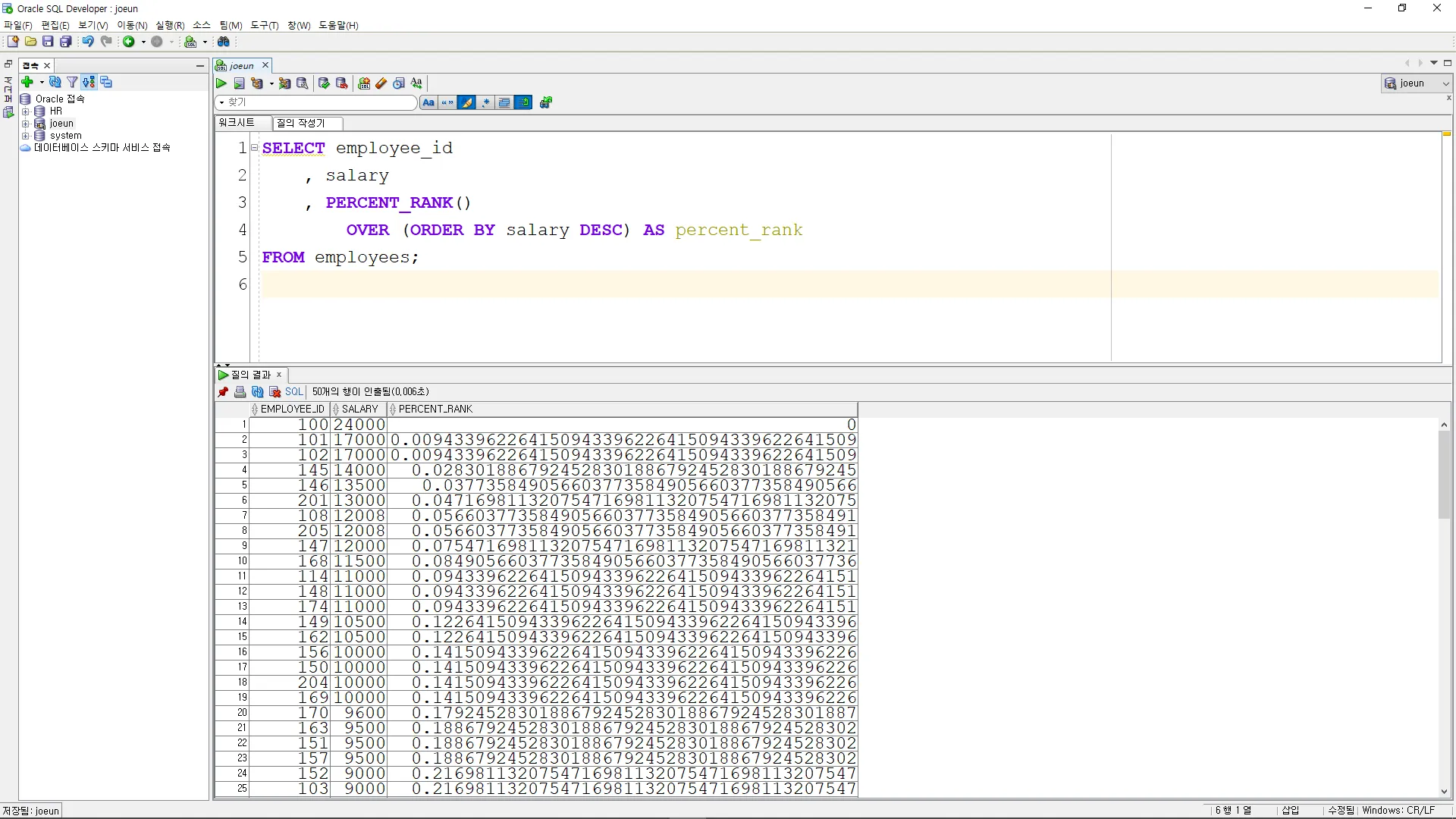
NTILE
•
이 함수는 결과 집합을 지정된 개수의 동일한 크기의 그룹으로 나누고, 각 행에 그룹 번호를 할당
SELECT employee_id
, salary
, NTILE(4)
OVER (ORDER BY salary DESC) AS quartile
FROM employees;
SQL
복사
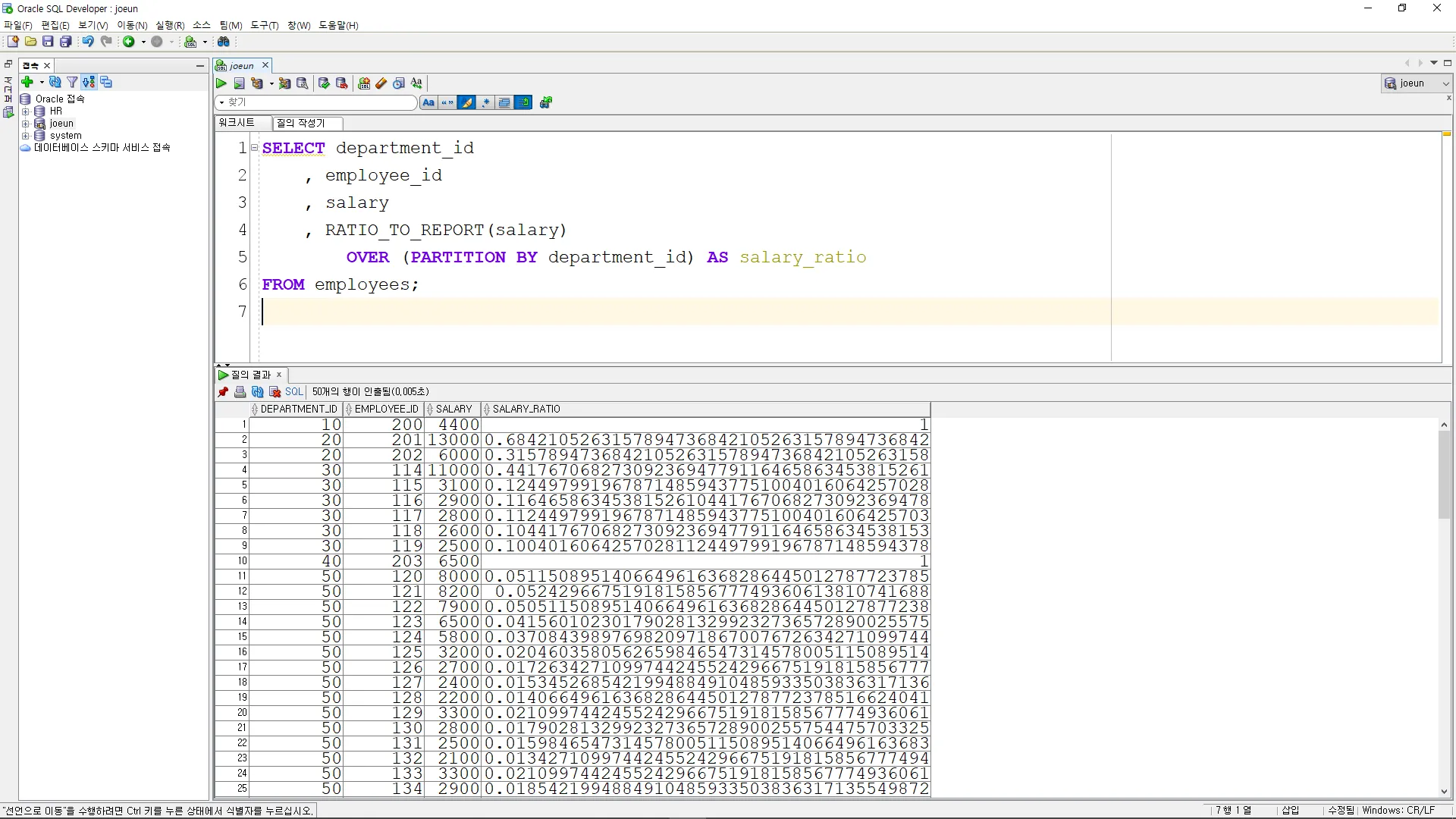
RATIO_TO_REPORT
•
이 함수는 결과 집합의 각 그룹에서 현재 행의 비율을 계산
SELECT department_id
, employee_id
, salary
, RATIO_TO_REPORT(salary)
OVER (PARTITION BY department_id) AS salary_ratio
FROM employees;
SQL
복사
Top N 쿼리
결과 집합에서 상위 N개의 행을 반환하는 쿼리
종류
•
ROWNUM
•
ROWID
ROWNUM
SELECT 문의 논리적인 순번을 나타내는 가상의 컬럼
ORACLE DB 데이터를 출력할 때 부여되는 논리적인 순서 번호이기 때문에,
ROWNUM 을 사용하여 페이징 처리를 하기 위해서는 인라인 뷰를 써야한다. ROWNUM 를 활용한 페이징 처리 SELECT *
FROM (
SELECT ROWNUM AS row_num, board_id, title, content
FROM board
WHERE ROWNUM <= 10 -- 원하는 페이지 크기를 여기에 지정합니다.
)
WHERE row_num >= 1; -- 원하는 페이지 번호에 맞게 시작하는 행 번호를 여기에 지정합니다.
SQL
복사
ROWID
각 행을 고유하게 식별하는데 사용되는 식별자
구성 요소 | 설명 |
오브젝트 번호 | ROWID가 속한 객체(테이블 또는 클러스터)의 고유한 번호를 나타냅니다. |
상대 파일 번호 | 행이 저장된 상대적인 데이터 파일 번호를 나타냅니다. |
블록 번호 | 행이 저장된 데이터 블록의 번호를 나타냅니다. |
데이터 번호 | 블록 내에서의 행의 상대적인 위치를 나타냅니다. |
•
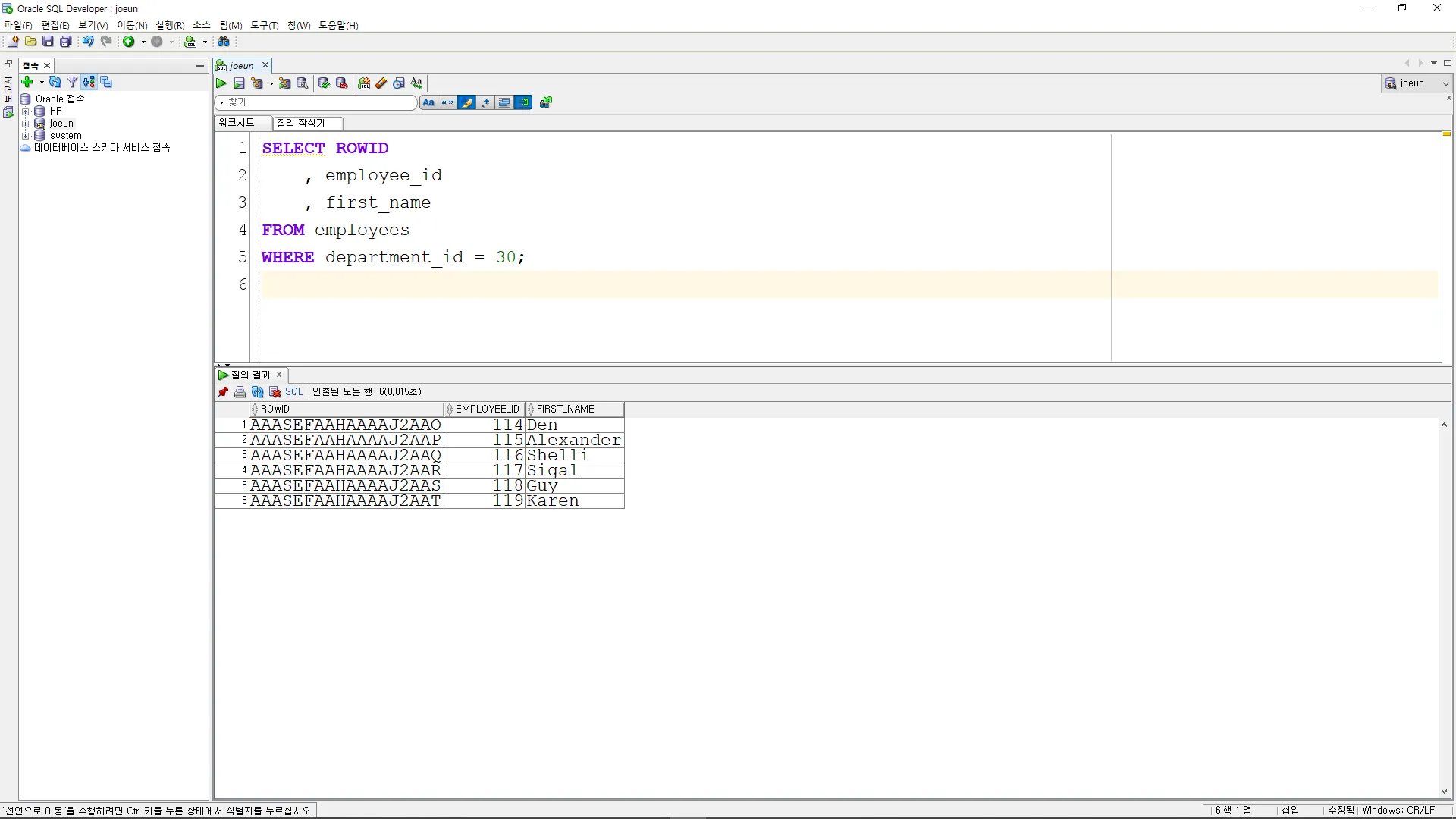
ROWID 예시코드
SELECT ROWID
, employee_id
, first_name
FROM employees
WHERE department_id = 30;
SQL
복사
계층형 쿼리
계층적인 데이터 구조에서 부모-자식 관계를 가진 데이터를 검색하거나 조작하는 쿼리
주로 조직도, 트리 구조 데이터 등을 처리할 때 사용됩니다. 문법
SELECT [표현식들]
FROM [테이블명]
START WITH [시작 조건]
CONNECT BY [재귀 조건];
SQL
복사
•
기본 구성 요소
구문 | 설명 |
SELECT [표현식들] | 조회할 열을 지정합니다. 계층 구조를 표현하기 위한 열과 추가적인 열이 포함될 수 있습니다. |
FROM [테이블명] | 계층형 쿼리를 수행할 대상 테이블을 지정합니다. |
START WITH [시작 조건] | 계층 구조의 시작점을 정의합니다. 지정된 조건을 만족하는 행이 시작점이 됩니다. |
CONNECT BY [재귀 조건] | 재귀적인 관계를 정의합니다. 지정된 조건을 만족하는 행이 이전 행과 연결되어 계층 구조를 형성합니다. |
PRIOR | CONNECT BY 절과 함께 사용되며, 이전 행을 의미하는 키워드이다.
PRIOR 자식 = 부모 (정방향) : 부모 자식
PRIOR 부모 = 자식 (역방향) : 자식 부모 |
•
CONNECT BY 키워드
키워드 및 함수 | 설명 |
CONNECT BY | 계층적 쿼리를 정의하기 위한 키워드로, 부모-자식 간의 관계를 지정합니다. |
LEVEL | 현재 행의 계층 레벨을 나타내는 의사 열입니다. |
CONNECT_BY_ROOT | 계층 구조에서 최상위 부모를 나타내는 의사 열입니다. |
CONNECT_BY_ISLEAF | 현재 행이 리프(말단) 노드인지 여부를 판별하는 의사 열입니다. |
SYS_CONNECT_BY_PATH | 계층적 쿼리에서 행의 경로를 나타내는 함수입니다. |
NOCYCLE | 순환(cycle)을 방지하기 위한 옵션입니다. |
CONNECT_BY_ISCYCLE | 현재 행이 순환 구조에 있는지 여부를 판별하는 의사 열입니다. |
ORDER BY SIBLINGS BY 컬럼 | 같은 LEVEL 노드 사이에서 정렬을 수행합니다. |
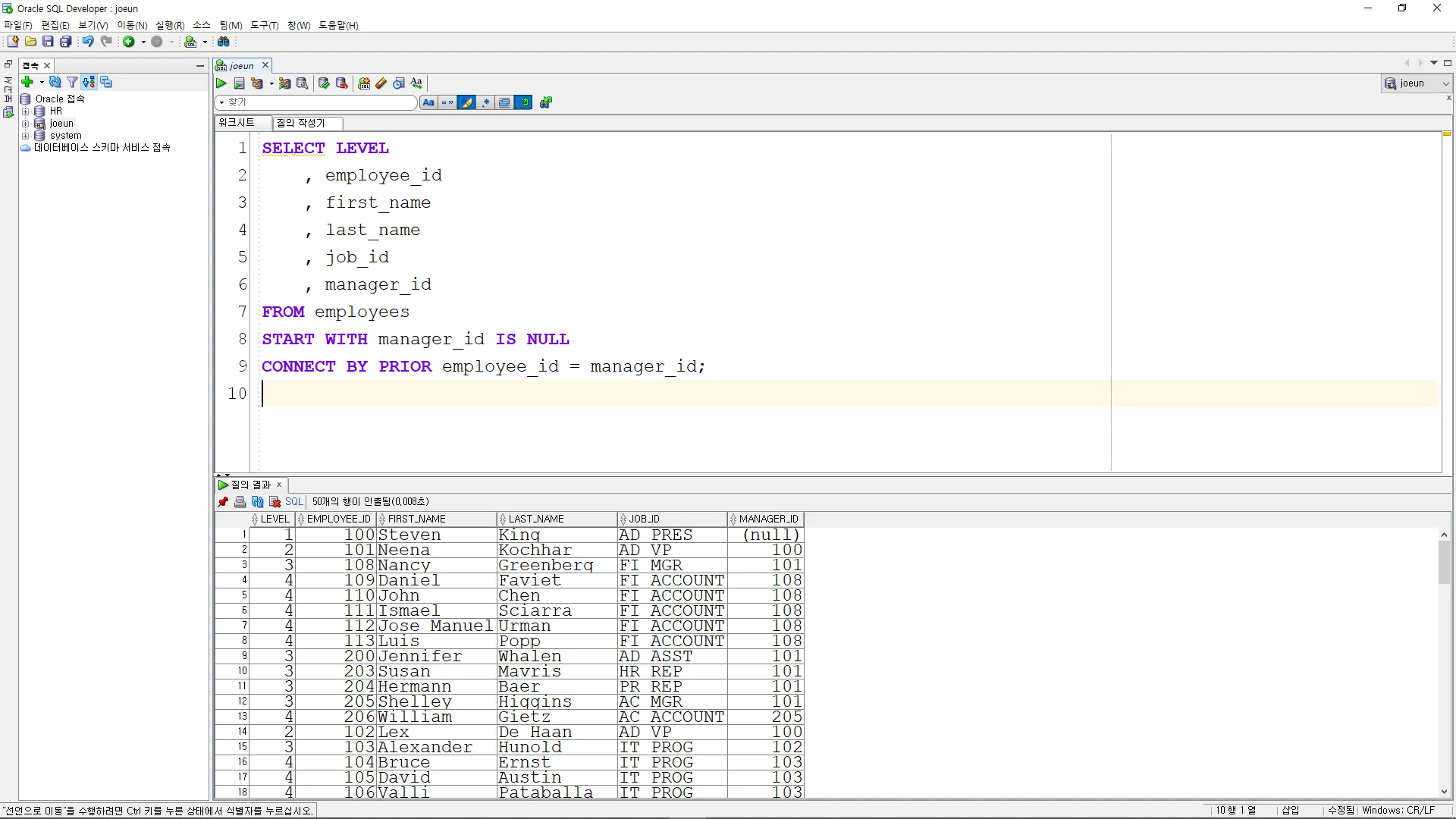
계층형 쿼리로 조직도를 출력하는 예시 코드
SELECT LEVEL
, employee_id
, first_name
, last_name
, job_id
, manager_id
FROM employees
START WITH manager_id IS NULL
CONNECT BY PRIOR employee_id = manager_id;
SQL
복사
•
START WITH manager_id IS NULL: 최상위 부서의 직원들을 선택합니다. 여기서는 최상위 직원이 매니저가 없는 직원들입니다.
•
CONNECT BY PRIOR employee_id = manager_id: 각 행을 이전 행과 연결합니다. 이전 행(PRIOR)의 employee_id가 현재 행의 manager_id와 같은 경우, 계층적으로 연결됩니다.
•
LEVEL: 각 행의 계층 레벨을 나타냅니다.
◦
1 : 대표
◦
2 : 부서장 (상사)
◦
3 : 직원 (부하)
PIVOT, UNPIVOT
PIVOT
그룹화한 행 데이터를 열로 바꾸어서 출력하는 함수
문법
(
SELECT 컬럼1, 컬럼2, 컬럼3
FROM 테이블명
)
PIVOT (
그룹함수( 컬럴명 )
FOR 피벗할 컬럼 IN ( 값1, 값2, 값3, ... )
)
SQL
복사
•
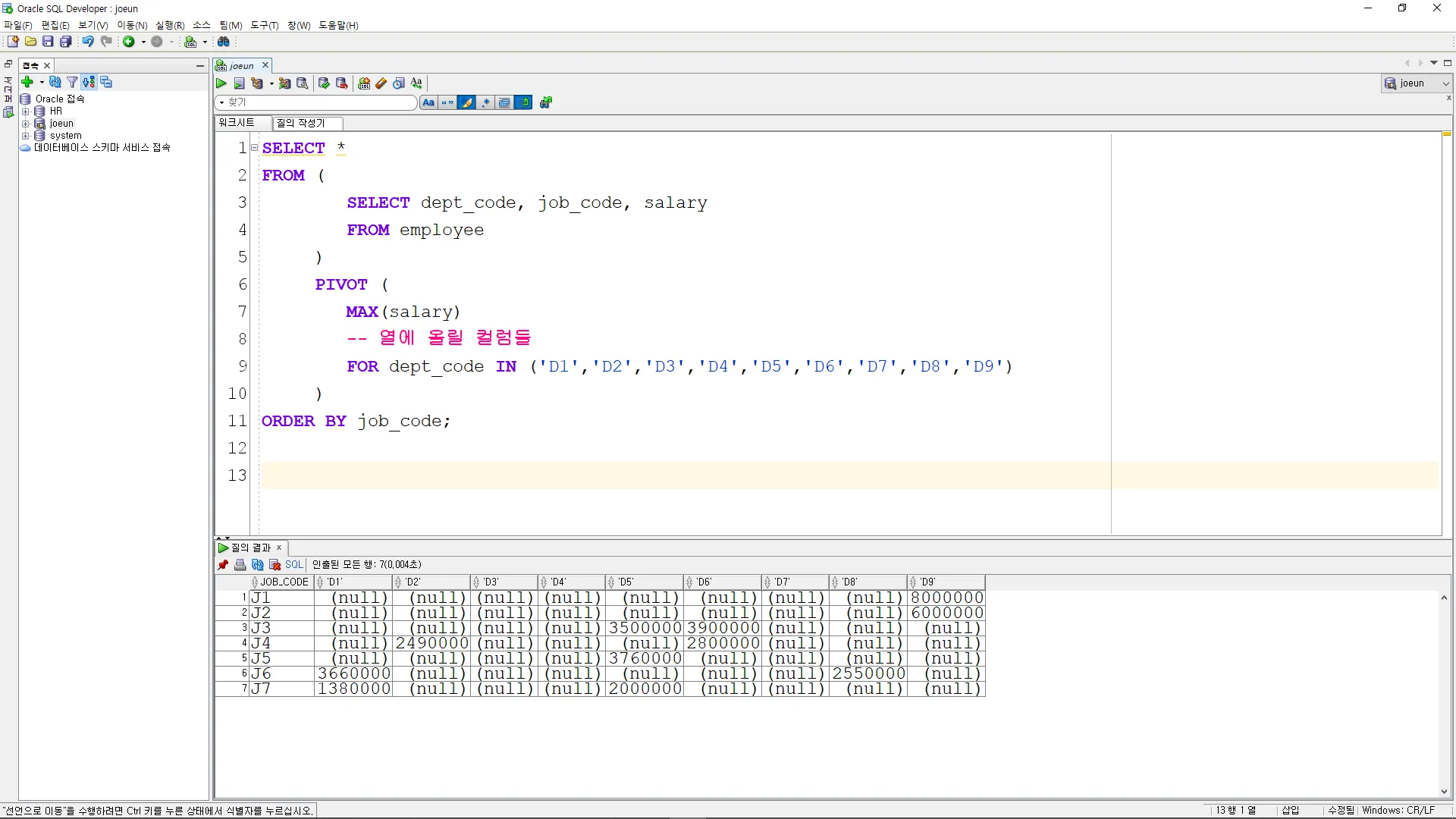
직급을 행에 표시, 부서는 열에 그룹화하여 최고급여를 출력하시오.
SELECT *
FROM (
SELECT dept_code, job_code, salary
FROM employee
)
PIVOT (
MAX(salary)
-- 열에 올릴 컬럼들
FOR dept_code IN ('D1','D2','D3','D4','D5','D6','D7','D8','D9')
)
ORDER BY job_code;
SQL
복사
UNPIVOT
그룹화된 결과인 열을 행 데이터로 바꾸어서 출력하는 함수
문법
(
SELECT 컬럼1, 컬럼2, 컬럼3
FROM 테이블명
)
UNPIVOT (
기준컬럼
FOR 피벗할 컬럼 IN (열1, 열2, 열3, ... )
)
SQL
복사
•
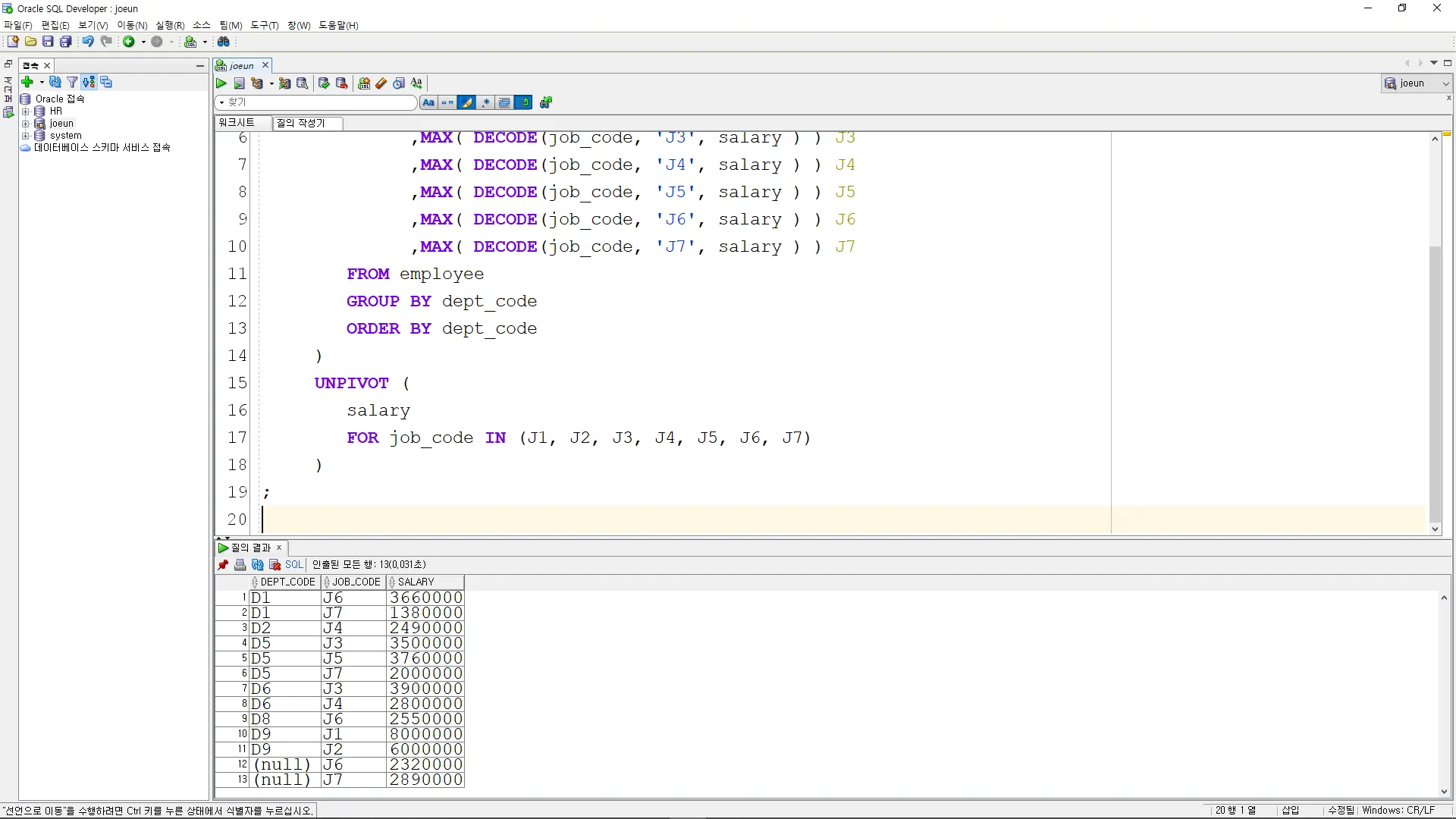
직급코드를 열에서 행으로 변환하여, 각 부서(dept_code)별로 직무별 최대 급여를 조회하시오.
SELECT *
FROM (
SELECT dept_code
,MAX( DECODE(job_code, 'J1', salary ) ) J1
,MAX( DECODE(job_code, 'J2', salary ) ) J2
,MAX( DECODE(job_code, 'J3', salary ) ) J3
,MAX( DECODE(job_code, 'J4', salary ) ) J4
,MAX( DECODE(job_code, 'J5', salary ) ) J5
,MAX( DECODE(job_code, 'J6', salary ) ) J6
,MAX( DECODE(job_code, 'J7', salary ) ) J7
FROM employee
GROUP BY dept_code
ORDER BY dept_code
)
UNPIVOT (
salary
FOR job_code IN (J1, J2, J3, J4, J5, J6, J7)
)
;
SQL
복사
테이블 파티션
대용량 테이블을 여러 데이터 파일로 분리하여 저장하는 기법
특징
•
CRUD 성능 향상
•
파티션별로 독립적으로 백업 및 복구 가능
•
조회 성능 향상
종류
파티션 종류 | 설명 |
Range Partition | 지정된 열의 값 범위에 따라 테이블을 여러 파티션으로 분할합니다. 주로 날짜 또는 숫자형 열에 사용됩니다. |
List Partition | 열의 목록 값에 따라 테이블을 여러 파티션으로 분할합니다. 주로 명시적인 값 리스트에 사용됩니다. |
Hash Partition | 해시 함수에 따라 행의 해시 값에 기초하여 테이블을 여러 파티션으로 분할합니다. 균일하게 분산되어있는 경우에 적합합니다. |
파티션 인덱스
데이터베이스에서 파티셔닝된 테이블에 대한 인덱스
•
특정한 파티션 키에 기반하여 여러 개의 파티션으로 분할된 데이터에 대한 빠른 액세스를 제공합니다.
•
파티션 인덱스는 파티션된 테이블과 관련된 데이터에 대해 인덱스의 일부를 각각의 파티션에 저장하므로, 대량의 데이터를 보다 효과적으로 관리하고 검색할 수 있습니다.
구분 | 설명 |
Global Index | 하나의 인덱스가 테이블의 모든 파티션에 대해 생성됩니다. 파티션 키를 포함하지 않습니다. |
Local Index | 각 파티션에 대해 별도의 인덱스가 생성됩니다. 각 인덱스는 해당 파티션의 데이터만을 포함합니다. 테이블 파티션의 수와 동일한 수의 인덱스가 생성됩니다. |
Prefixed Index | 파티션 키를 인덱스의 첫 번째 열로 사용하는 인덱스입니다. 이는 파티션 키의 일부가 인덱스 키의 일부로 사용되는 경우를 의미합니다. |
Non Prefixed Index | 파티션 키를 인덱스의 첫 번째 열로 사용하지 않는 인덱스입니다. 인덱스 키와 파티션 키가 동일하지 않습니다. 이 경우 인덱스는 테이블 파티션과 무관하게 작동합니다. |
정규 표현식
문자열 패턴을 표현하는 데 사용되는 형식 언어
함수
함수명 | 설명 |
REGEXP_LIKE | 문자열이 정규 표현식과 일치하는지 여부를 확인합니다. |
REGEXP_REPLACE | 문자열에서 정규 표현식과 일치하는 부분을 다른 문자열로 대체합니다. |
REGEXP_INSTR | 문자열에서 정규 표현식과 일치하는 부분의 위치를 반환합니다. |
REGEXP_SUBSTR | 문자열에서 정규 표현식과 일치하는 부분을 추출합니다. |
REGEXP_COUNT | 문자열에서 정규 표현식과 일치하는 부분의 수를 반환합니다. |
메타문자
정규 표현식의 구문을 정의하고 패턴 매칭을 수행하는 데 사용되는 기호
메타 문자 | 설명 |
^ | 문자열의 시작을 나타냅니다. |
$ | 문자열의 끝을 나타냅니다. |
. | 임의의 한 문자와 일치합니다. |
* | 바로 앞에 있는 문자나 그룹이 0번 이상 반복됨을 나타냅니다. |
+ | 바로 앞에 있는 문자나 그룹이 1번 이상 반복됨을 나타냅니다. |
? | 바로 앞에 있는 문자나 그룹이 0 또는 1번 나타날 수 있음을 나타냅니다. |
{n} | 바로 앞에 있는 문자나 그룹이 n번 반복됨을 나타냅니다. |
{n,} | 바로 앞에 있는 문자나 그룹이 n번 이상 반복됨을 나타냅니다. |
{n,m} | 바로 앞에 있는 문자나 그룹이 최소 n번 이상 최대 m번까지 반복됨을 나타냅니다. |
[abc] | 대괄호 안에 있는 문자 중 하나와 일치합니다. |
[^abc] | 대괄호 안에 있는 문자들을 제외한 문자와 일치합니다. |
[a-z] | 대괄호 안에 있는 범위의 문자 중 하나와 일치합니다. |
| | "or"를 나타내며, 패턴의 여러 부분 중 하나와 일치합니다. |
() | 그룹을 나타내며, 그룹화된 부분을 나중에 참조하거나 반복 수량을 지정할 때 사용됩니다. |
\ | 특수 문자의 의미를 제거하고 문자 그 자체를 나타냅니다. |
예시 코드
•
숫자 검사
•
문자 검사
•
이메일 형식 검사
숫자 검사
SELECT column_name
FROM table_name
WHERE REGEXP_LIKE(column_name, '^[0-9]+$');
SQL
복사
문자 검사
SELECT column_name
FROM table_name
WHERE REGEXP_LIKE(column_name, '^[A-Za-z]+$');
SQL
복사
이메일 형식 검사
SELECT email
FROM users
WHERE REGEXP_LIKE(email, '^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$');
SQL
복사