


그룹 관련 함수
ROLLUP(인자1, 인자2, ...) | 그룹 기준으로 집계한 정보를 레벨별로 출력하는 함수 |
CUBE(인자1, 인자2, ...) | 그룹 기준으로 집계한 정보를 가능한 모든 조합별로 출력하는 함수 |
GROUPING SETS(인자1, 인자2, ...) | 그룹 컬럼이 여러 개 일 때, 집계한 정보를 컬럼별로 출력하는 함수 |
GROUPING() | 그룹화한 컬럼들에 대해 그룹화된 여부를 출력하는 함수
- 그룹화 O : 출력 결과 0
- 그룹화 X : 출력 결과 1 |
LISTAGG( 나열할 컬럼, [구분자] ) | ( LIST + Aggregate : 목록 + 결합 )
그룹화된 데이터를 하나의 열에 목록으로 나열하여 출력하는 함수 |
PIVOT() | 그룹화한 행 데이터를 열로 바꾸어서 출력하는 함수 |
UNPIVOT() | 그룹화된 결과인 열을 행 데이터로 바꾸어서 출력하는 함수 |
그룹관련 함수 구조
SELECT ...
FROM ...
WHERE ...
GROUP BY 그룹관련함수[ ROLLUP | CUBE | ... ]
SQL
복사
PIVOT()
(
SELECT 컬럼1, 컬럼2, 컬럼3
FROM 테이블명
)
PIVOT (
그룹함수( 컬럴명 )
FOR 피벗할 컬럼 IN ( 값1, 값2, 값3, ... )
)
SQL
복사
UNPIVOT()
UNPIVOT (
기준컬럼
FOR 피벗할 컬럼 IN (열1, 열2, 열3, ... )
)
SQL
복사
HR 스키마 실습코드
ROLLUP

그룹 기준으로 집계한 정보를 레벨별로 출력하는 함수
ROLLUP(인자1, 인자2, ...)
SQL
복사
•
부서별, 직급별 급여 최댓값, 합계, 평균
•
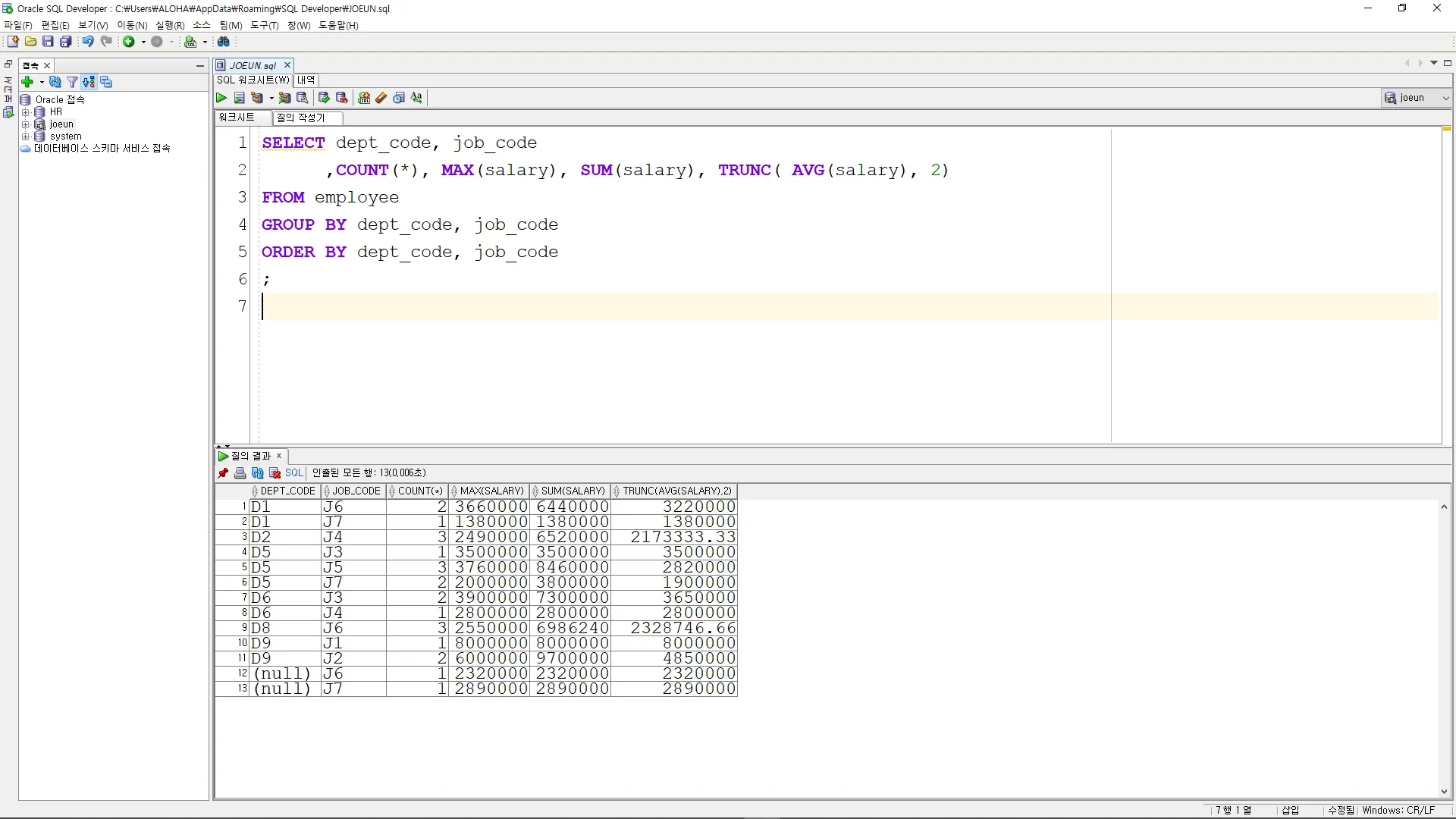
ROLLUP 미사용
SELECT dept_code, job_code
,COUNT(*), MAX(salary), SUM(salary), TRUNC( AVG(salary), 2)
FROM employee
GROUP BY dept_code, job_code
ORDER BY dept_code, job_code
;
SQL
복사
•
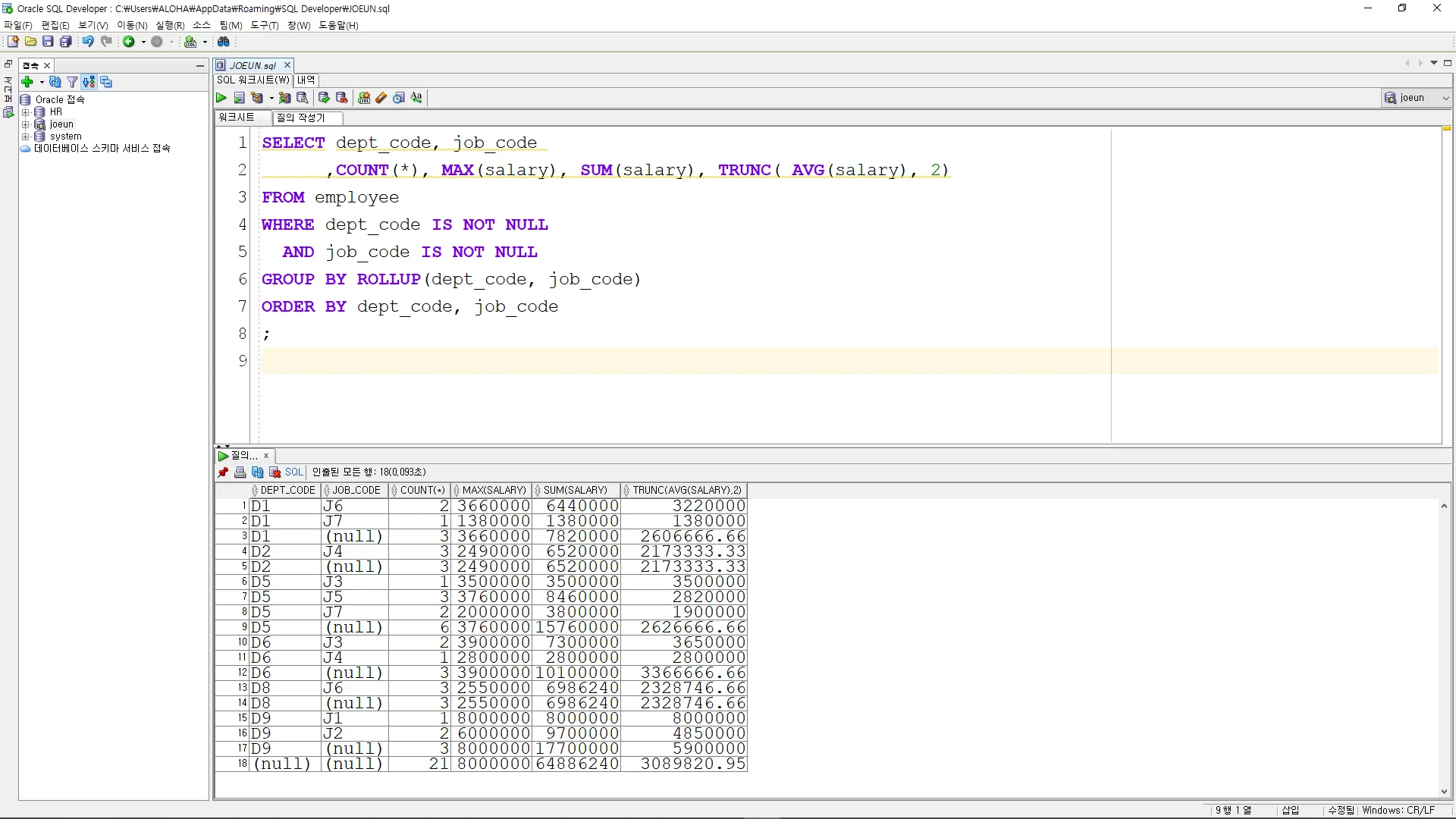
ROLLUP 사용
: 그룹 기준으로 집계한 결과와 추가적으로 총 집계 정보 출력하는 함수
SELECT dept_code, job_code
,COUNT(*), MAX(salary), SUM(salary), TRUNC( AVG(salary), 2)
FROM employee
WHERE dept_code IS NOT NULL
AND job_code IS NOT NULL
GROUP BY ROLLUP(dept_code, job_code)
ORDER BY dept_code, job_code
;
SQL
복사
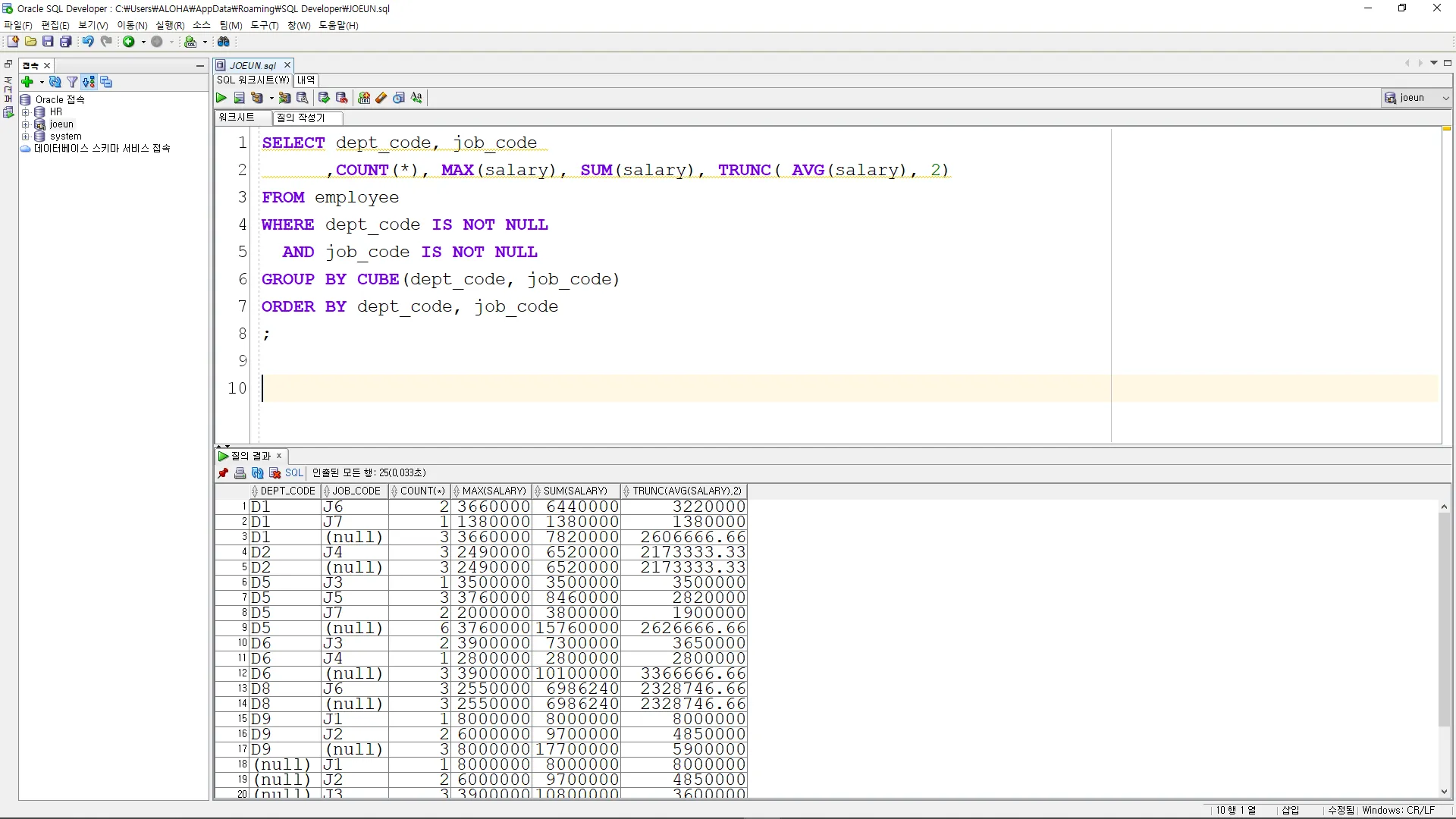
CUBE
그룹 기준으로 집계한 정보를 가능한 모든 조합별로 출력하는 함수
CUBE(인자1, 인자2, ...)
SQL
복사
SELECT dept_code, job_code
,COUNT(*), MAX(salary), SUM(salary), TRUNC( AVG(salary), 2)
FROM employee
WHERE dept_code IS NOT NULL
AND job_code IS NOT NULL
GROUP BY CUBE(dept_code, job_code)
ORDER BY dept_code, job_code
;
SQL
복사
GROUPING SETS()
그룹컬럼이 여러 개 일 때, 집계한 정보를 컬럼별로 출력하는 함수
GROUPING SETS(인자1, 인자2, ...)
SQL
복사
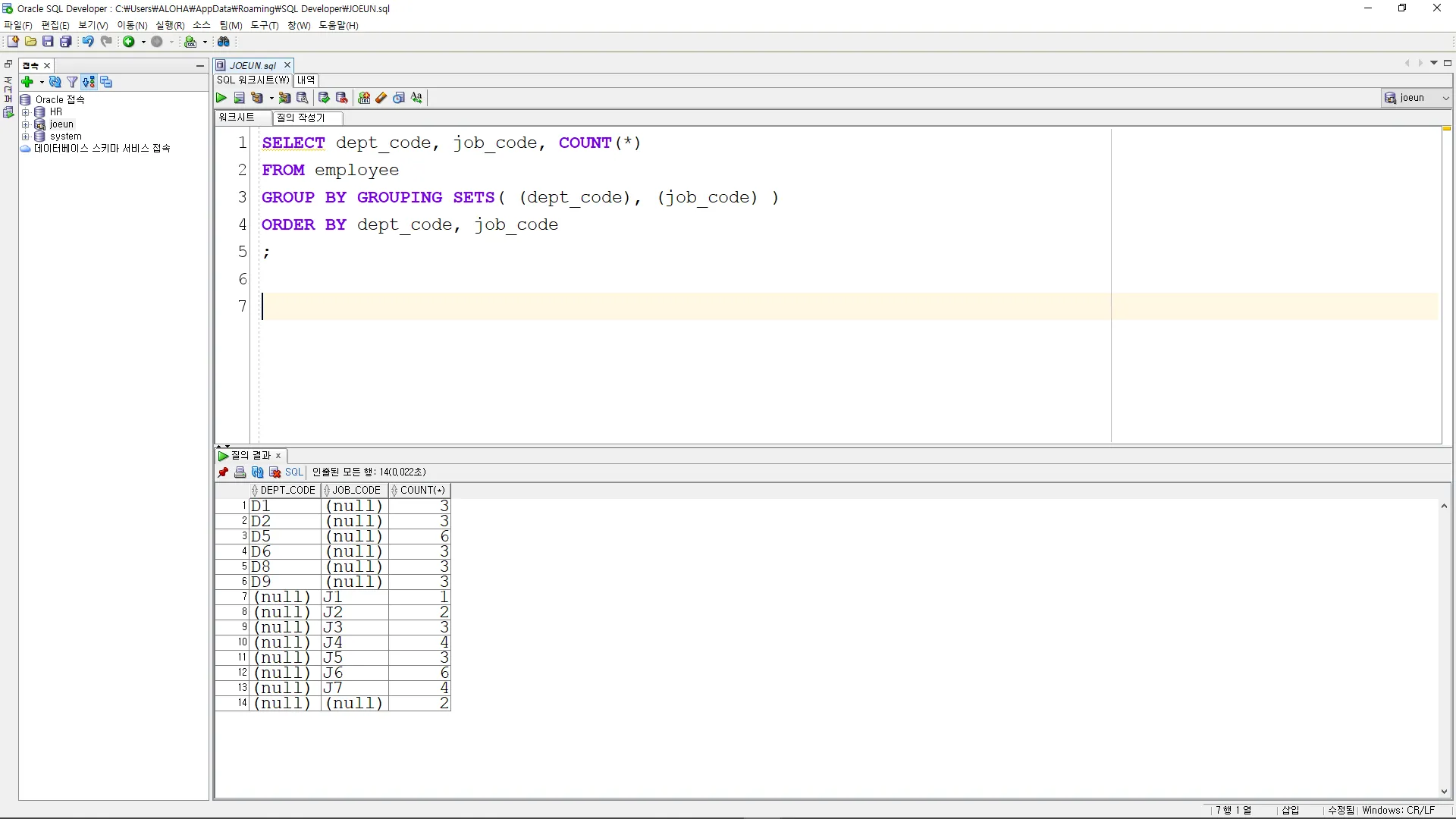
•
각각 부서별, 직급별 별도로 인원 수
SELECT dept_code, job_code, COUNT(*)
FROM employee
GROUP BY GROUPING SETS( (dept_code), (job_code) )
ORDER BY dept_code, job_code
;
SQL
복사
•
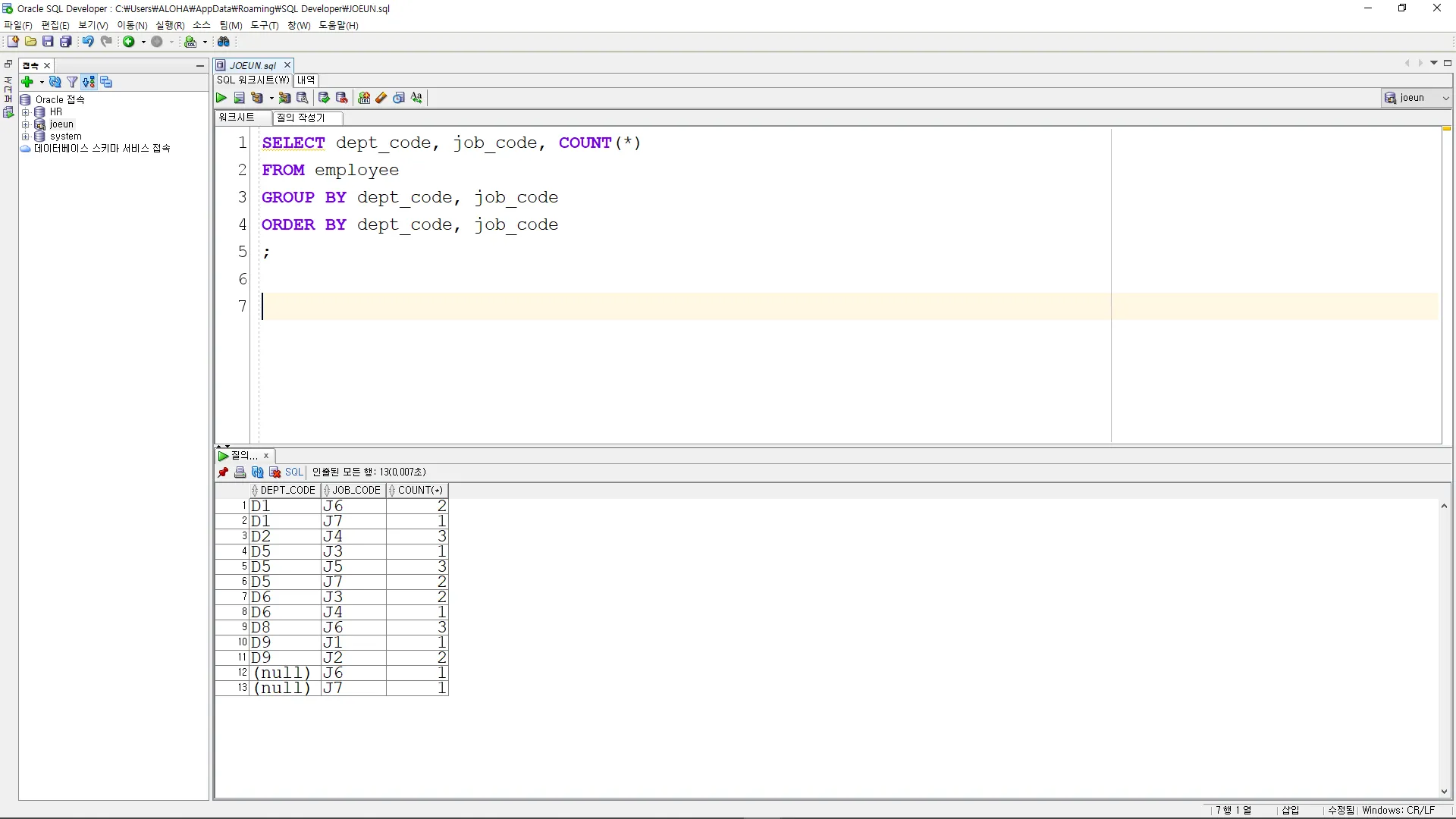
특정 부서의 직급별 인원 수
SELECT dept_code, job_code, COUNT(*)
FROM employee
GROUP BY dept_code, job_code
ORDER BY dept_code, job_code
;
SQL
복사
GROUPING
그룹화한 컬럼들에 대해 그룹화된 여부를 출력하는 함수
GROUPING()
SQL
복사
•
그룹화 O : 출력 결과 0
•
그룹화 X : 출력 결과 1
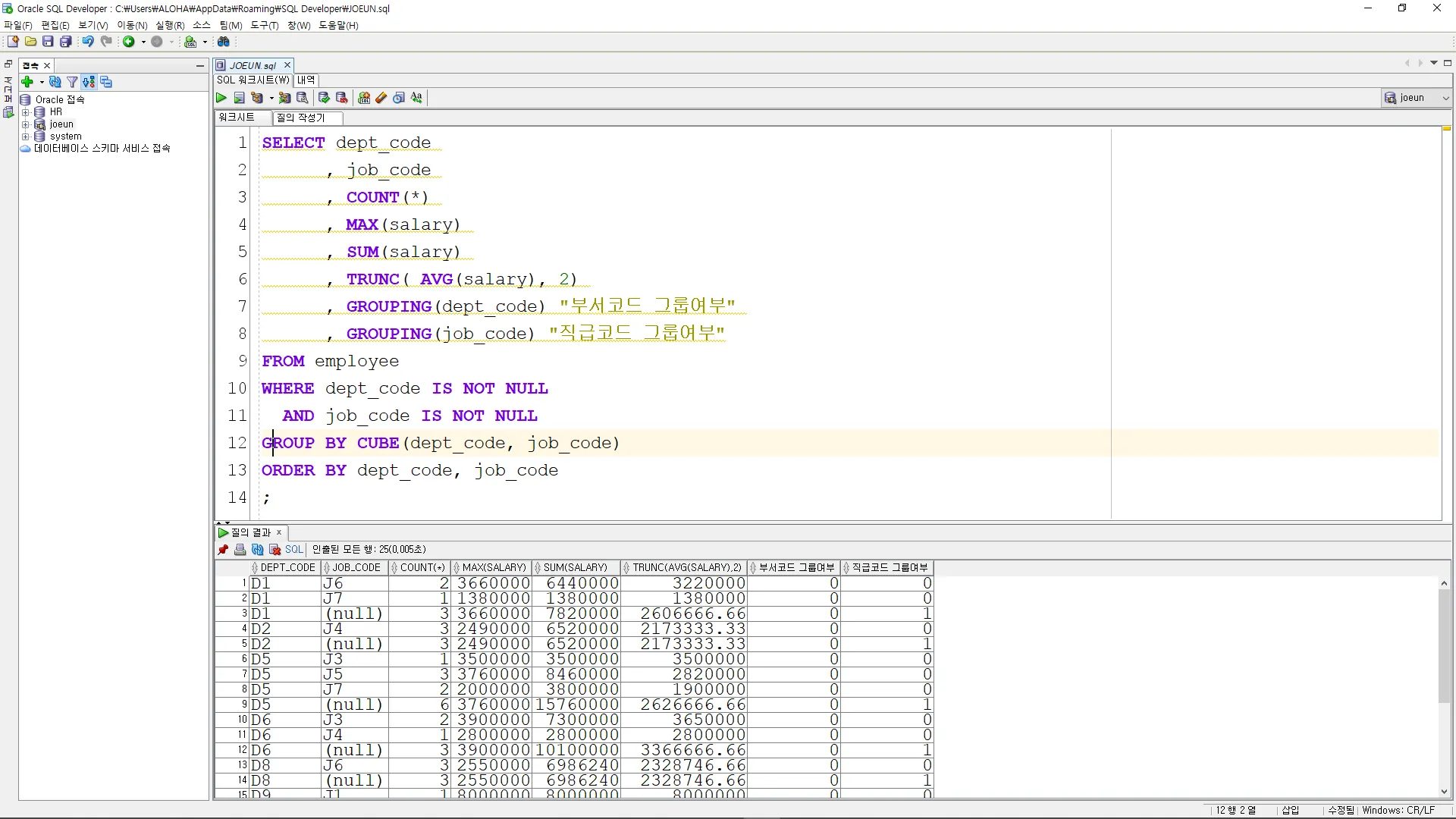
SELECT dept_code
, job_code
, COUNT(*)
, MAX(salary)
, SUM(salary)
, TRUNC( AVG(salary), 2)
, GROUPING(dept_code) "부서코드 그룹여부"
, GROUPING(job_code) "직급코드 그룹여부"
FROM employee
WHERE dept_code IS NOT NULL
AND job_code IS NOT NULL
GROUP BY CUBE(dept_code, job_code)
ORDER BY dept_code, job_code
;
SQL
복사
LISTAGG
그룹화된 데이터를 하나의 열에 목록으로 나열하여 출력하는 함수
LISTAGG( 나열할 컬럼, [구분자] )
WITHIN GROUP (ORDER BY 정렬기준 컬럼)
SQL
복사
LISTAGG : LIST + Aggregate : 목록 + 결합
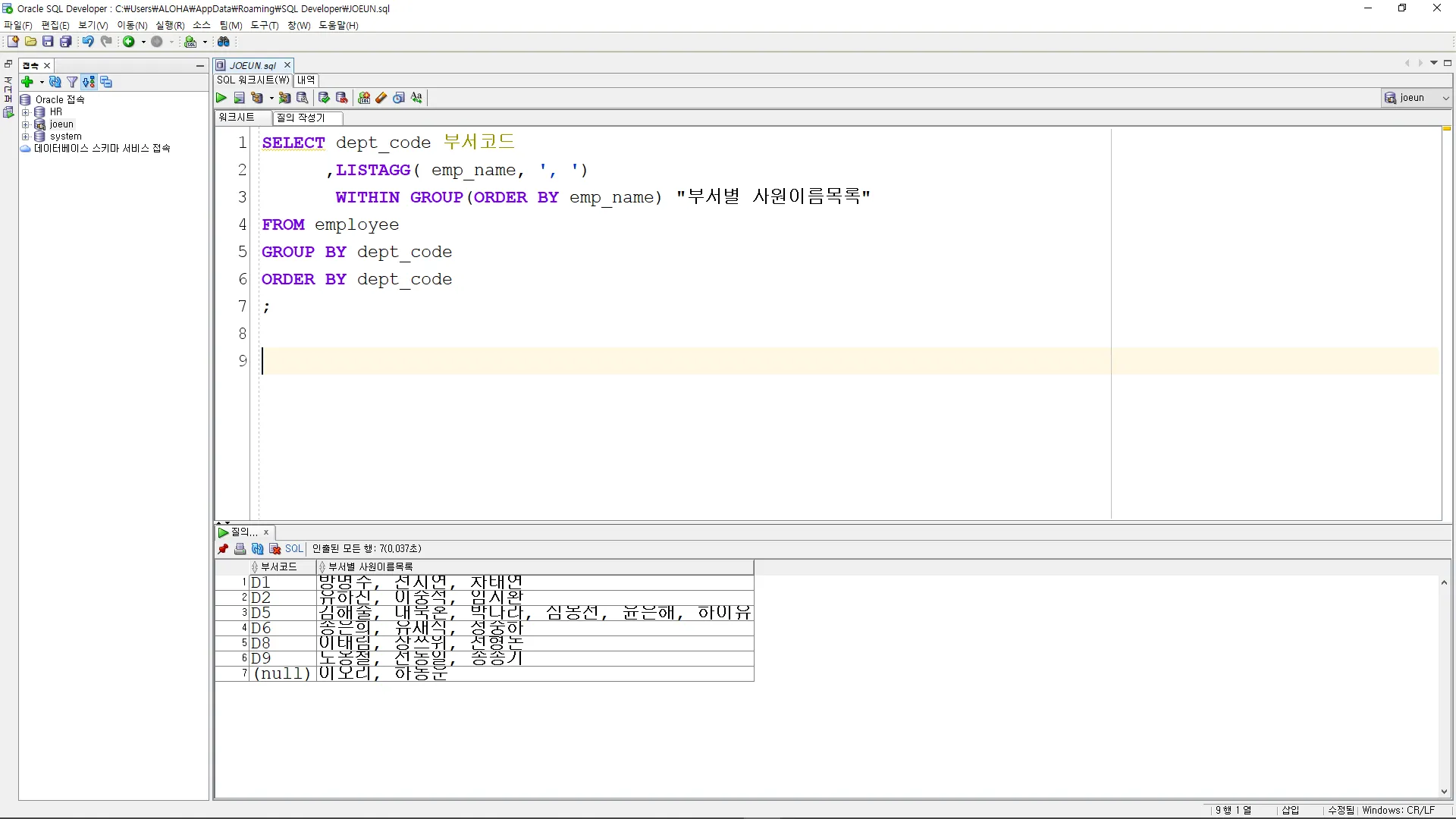
SELECT dept_code 부서코드
,LISTAGG( emp_name, ', ')
WITHIN GROUP(ORDER BY emp_name) "부서별 사원이름목록"
FROM employee
GROUP BY dept_code
ORDER BY dept_code
;
SQL
복사
PIVOT
•
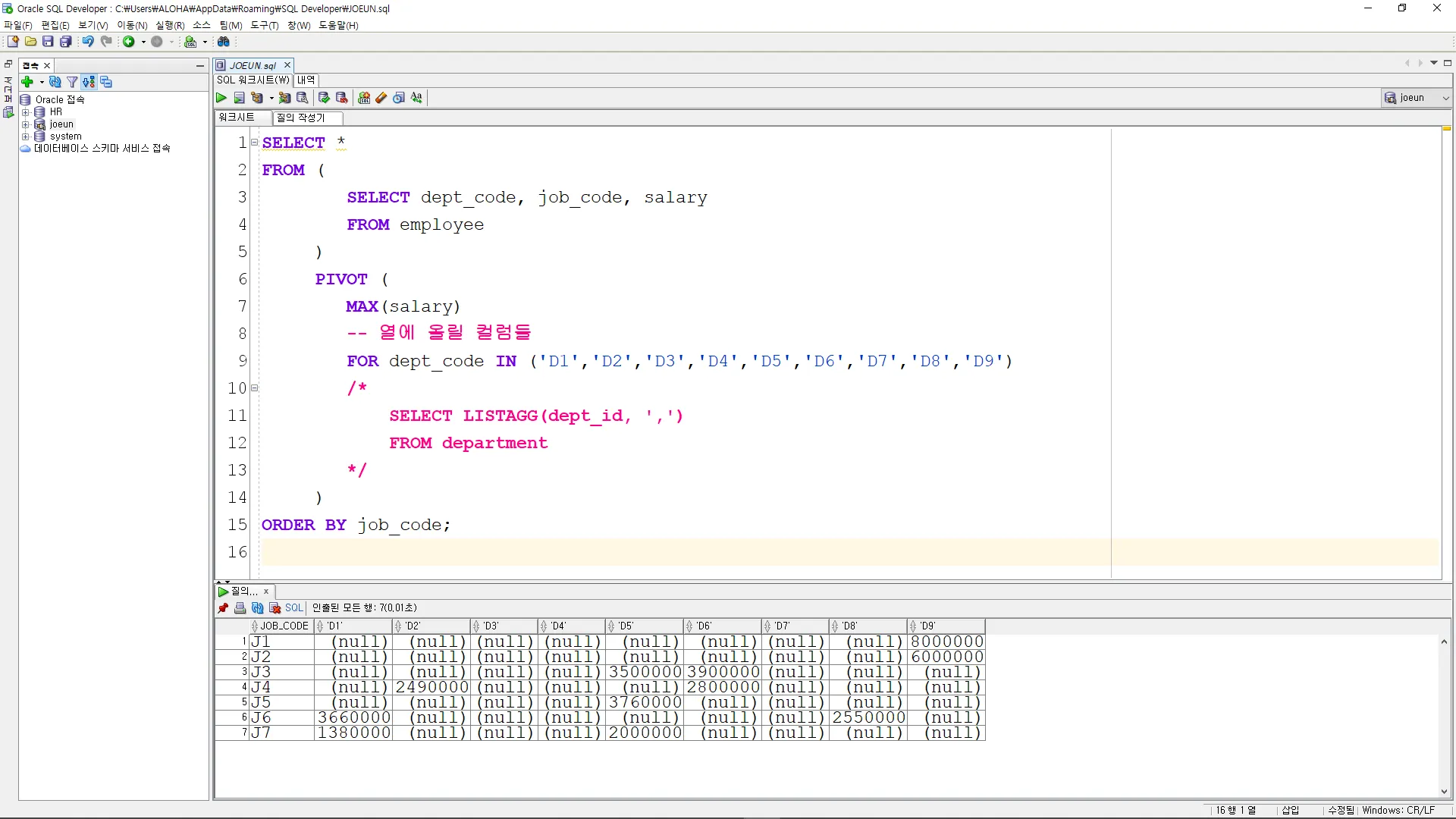
직급을 행에 표시, 부서는 열에 그룹화하여 최고급여를 출력하시오.
SELECT *
FROM (
SELECT dept_code, job_code, salary
FROM employee
)
PIVOT (
MAX(salary)
-- 열에 올릴 컬럼들
FOR dept_code IN ('D1','D2','D3','D4','D5','D6','D7','D8','D9')
/*
SELECT LISTAGG(dept_id, ',')
FROM department
*/
)
ORDER BY job_code;
SQL
복사
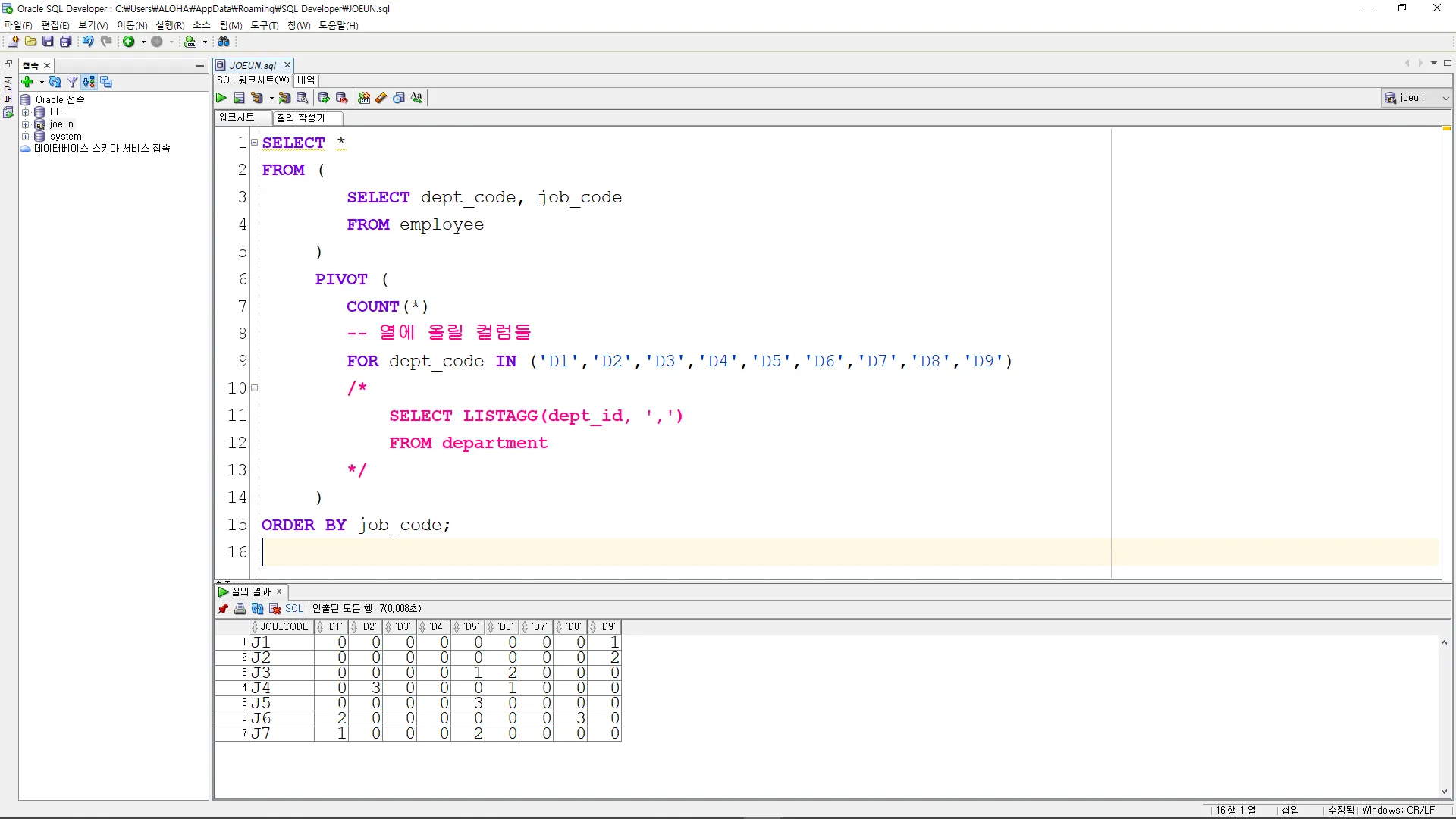
SELECT *
FROM (
SELECT dept_code, job_code
FROM employee
)
PIVOT (
COUNT(*)
-- 열에 올릴 컬럼들
FOR dept_code IN ('D1','D2','D3','D4','D5','D6','D7','D8','D9')
/*
SELECT LISTAGG(dept_id, ',')
FROM department
*/
)
ORDER BY job_code;
SQL
복사
UNPIVOT
SELECT *
FROM (
SELECT dept_code
,MAX( DECODE(job_code, 'J1', salary ) ) J1
,MAX( DECODE(job_code, 'J2', salary ) ) J2
,MAX( DECODE(job_code, 'J3', salary ) ) J3
,MAX( DECODE(job_code, 'J4', salary ) ) J4
,MAX( DECODE(job_code, 'J5', salary ) ) J5
,MAX( DECODE(job_code, 'J6', salary ) ) J6
,MAX( DECODE(job_code, 'J7', salary ) ) J7
FROM employee
GROUP BY dept_code
ORDER BY dept_code
)
UNPIVOT (
salary
FOR job_code IN (J1, J2, J3, J4, J5, J6, J7)
)
;
SQL
복사