SQL 기본

•
•
•
•
•
관계형 데이터베이스

관계형 데이터 모델에 기반한 데이터베이스
데이터?
: 측정 및 수집한 값
정보?
: 데이터를 가공하여 의미를 부여한 것
데이터베이스 (DataBase)
: “데이터 저장소”
데이터 + 베이스
•
데이터 : 측정 및 수집한 값
•
베이스 : 기지
•
데이터베이스 : 데이터가 저장된 기지; “데이터 저장소”

공유하기 위해 통합하여 저장한 운영 데이터의 집합

데이터베이스 특징


데이터를 파일 시스템으로 관리하면 데이터가 중복 및 누락될 가능성이 비교적 더 크다. 또한, 여러 시스템 간의 데이터를 공유하는 것이 어렵다. 하지만, 데이터베이스를 사용하면, 여러 시스템을 사용하더라도 데이터를 중복 및 누락을 최소화할 수 있으며 시스템 간 실시간 데이터 공유가 가능하다.
데이터베이스 시스템
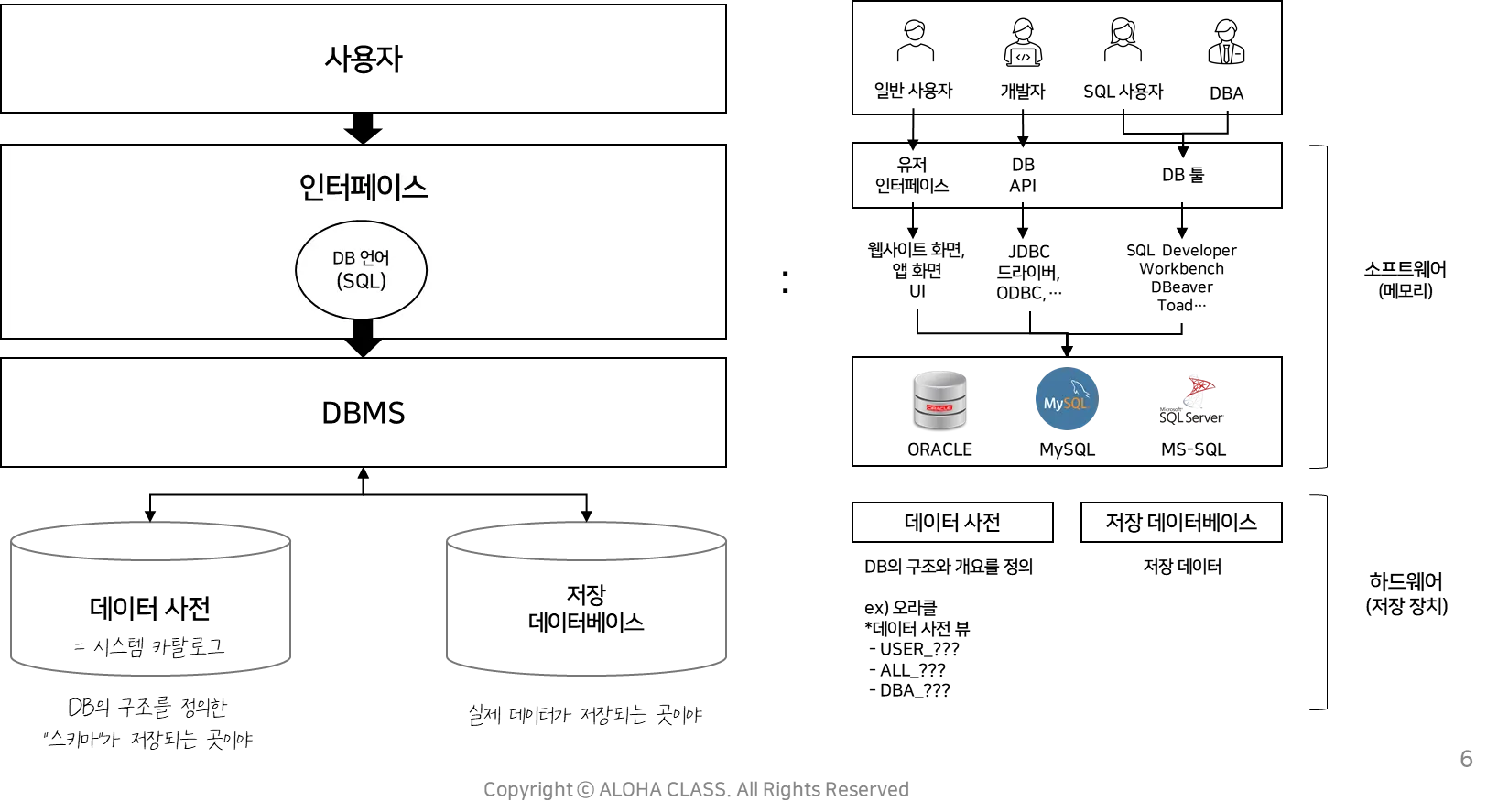
데이터베이스 시스템
: 사용자 + 인터페이스 + DBMS + 데이터베이스(데이터사전, 저장DB)
•
사용자
: 일반 사용자, 개발자, SQL 사용자, DBA
•
인터페이스
: UI, DB API, DB TOOL
◦
UI
: 사용자가 데이터를 요청하는 화면
▪
웹, 앱, 프로그램 화면
◦
DB API
: 개발자가 개발하는 프로그램과 연결된 인터페이스
▪
DB 드라이버 (JDBC 등)
◦
DB TOOL
: 데이터 관리자가 DBMS 를 사용하는 프로그램
▪
SQL Developer, Workbench, DBeaver, Toad 등
•
데이터베이스
: 데이터 사전 + 저장 데이터베이스
◦
데이터 사전
▪
메타 테이터가 저장되는 곳
▪
메타데이터 : 데이터베이스 구조, 스키마, 테이블 정의, 제약 조건, 인덱스, 뷰 등
◦
저장 데이터베이스
▪
실제 데이터가 저장되는 곳
•
DBMS
: 데이터베이스를 관리하는 시스템
◦
주요 제품 : ORACLE, MySQL, MS-SQL
데이터베이스 시스템의 구성요소는 사용자, 인터페이스, DBMS, 데이터베이스 입니다.
사용자는,
데이터베이스 시스템을 사용하는 사람 또는 응용 프로그램을 말합니다. 사용자는 데이터를 조회, 추가, 수정, 삭제하고 데이터베이스 시스템의 기능을 활용할 수 있습니다.
인터페이스는,
사용자와 데이터베이스 시스템 간의 상호 작용을 위한 매개체로, 명령을 입력하고 결과를 표시하는 방식을 제공합니다. 인터페이스는 명령 줄 인터페이스(CLI), 그래픽 사용자 인터페이스(GUI), 응용 프로그램 API 등 다양한 형태로 존재할 수 있습니다.
DBMS(Database Management System) 는,
데이터베이스 시스템의 핵심 구성 요소로, 데이터를 관리하고 조작하는 데 사용되는 소프트웨어입니다. DBMS는 데이터베이스 생성, 조작, 유지 관리, 보안, 무결성 등의 기능을 제공합니다.
데이터베이스는,
실제 데이터가 저장되는 장소입니다. 데이터베이스는 데이터 사전(메타데이터)과 저장 데이터베이스로 구성됩니다. 데이터 사전은 데이터에 대한 정보를 포함하고, 저장 데이터베이스는 실제 데이터 레코드를 보유합니다.
데이터 모델
: 데이터를 저장하는 방식을 간단하게 설명해주는 구조
( 모델 : 실체를 간단하게 설명해주는 작은 구조 )
데이터 모델의 종류
•
계층형
•
네트워크형
•
객체지향형
•
관계형
관계형 데이터 모델
: 행과 열을 갖는 2차원 구조의 테이블 형태를 통하여 자료를 표현하는 것
관계형 데이터 모델의 핵심 구성 요소
•
개체(Entity) = 릴레이션 (실제 DB의 테이블과 대응)
•
속성(Attriute)
•
관계(Relationship)
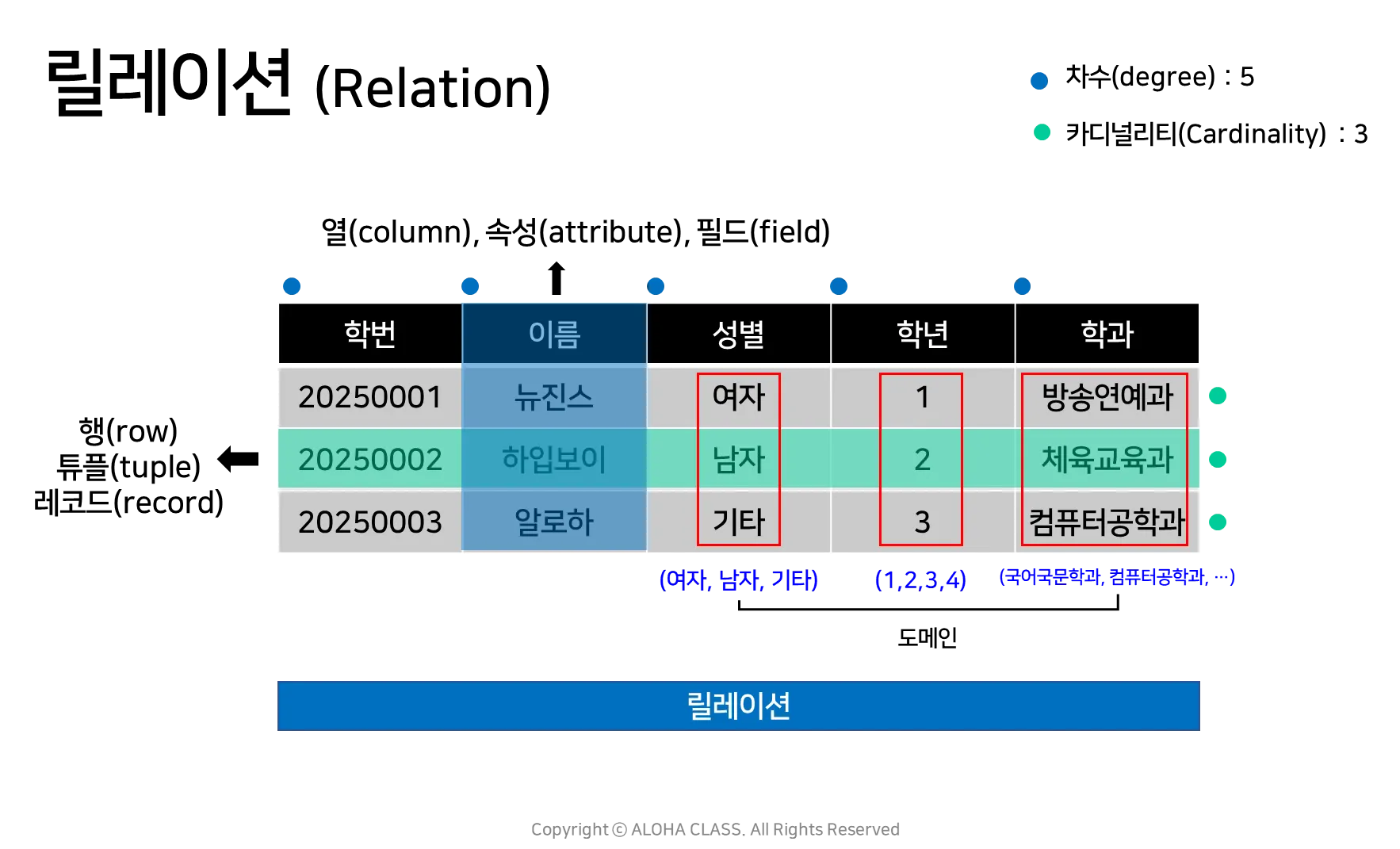
릴레이션의 구성요소
•
릴레이션(Relation) : 데이터들을 2차원 테이블의 구조로 저장한 것(테이블)
•
속성(Attribute) : 릴레이션의 열 (컬럼; column)
•
튜플(Tuple) : 릴레이션의 행 (로우; row)
•
차수(Degree) : 릴레이션 속성의 개수
•
카디널리티(Cardinality) : 릴레이션의 입력된 튜플의 개수
•
도메인(Domain) : 하나의 속성이 가질 수 있는 값의 범위
릴레이션의 특징
•
튜플의 속성은 하나의 데이터만 저장한다
•
튜플은 모두 다른 데이터로 유일한 값을 갖는다
•
튜플 간의 순서는 의미가 없다
•
속성 간의 순서는 의미가 없다
•
속성은 분해되지 않는 원자값를 갖는다 (하나의 속성은 하나의 값만 갖는다)
데이터 모델은 데이터를 저장하는 방식을 이해하기 쉽게 단순화한 구조이다.
데이터 모델에 대한 연구가 진행되면서, 다양한 형태의 데이터 모델이 등장하였으나, 현재까지 가장 널리 사용되는 데이터 모델은 바로 관계형 데이터 모델이다. 관계형 데이터 모델은 행과 열로 구성된 표의 형태, 즉 테이블이라는 기본 구조로 데이터를 표현하고 관리하는 구조이다.
관계형 데이터 모델은 데이터베이스의 구조를 명확하게 정의하여 데이터의 일관성, 무결성, 보안 등을 유지하고 관리하기에 적합한 방법 중 하나이다. 이러한 관계형 데이터 모델을 기반으로 데이터를 다루는 데이터 저장소를 관계형 데이터베이스라고 한다. 쉽게 말해, 행과 열의 2차원 구조인 테이블을 기본으로 다루는 데이터베이스를 관계형 데이터베이스라고 할 수 있다.
관계형 데이터베이스
: 관계형 데이터 모델에 기반한 데이터베이스
RDBMS(Relational Database Management System)
: 관계형 데이터 모델을 바탕으로 데이터를 저장 및 관리하는 시스템
SQL (Sturctrured Query Language)
: "구조화된 질의어"
RDBMS 에서 데이터를 다루고 관리하는 질의 언어
관계형 데이터베이스 제품
•
ORACLE
•
MySQL
•
MS-SQL
집합 연산 & 관계 연산
집합연산
집합 연산 | 설명 |
합집합 | 두 집합의 모든 요소를 포함하는 새로운 집합을 생성합니다. |
차집합 | 첫 번째 집합에서 두 번째 집합에 있는 요소를 제외한 새로운 집합을 생성합니다. |
교집합 | 두 집합에 공통으로 있는 모든 요소로 구성된 새로운 집합을 생성합니다. |
곱집합 | 두 집합의 모든 가능한 조합으로 구성된 새로운 집합을 생성합니다. |
이러한 집합 연산을 사용하여 데이터베이스에서 여러 테이블의 데이터를 결합하거나 필요한 정보를 추출할 수 있습니다.
관계 연산
관계 연산 | 설명 |
선택 연산 | 특정 조건을 만족하는 튜플들을 선택하여 새로운 관계를 생성합니다. |
투영 연산 | 관계에서 특정 속성(열)들을 선택하여 새로운 관계를 생성합니다. |
결합 연산 | 두 개 이상의 관계를 조합하여 새로운 관계를 생성합니다. |
나누기 연산 | 하나의 관계에서 다른 관계의 튜플들로 나누어 새로운 관계를 생성합니다. |
이러한 관계 연산은 데이터베이스에서 데이터를 추출하고 조작하는 데 사용됩니다.
테이블(Table)
관계형 데이터 베이스는 릴레이션에 데이터를 저장하고 연산
최종적으로 DBMS 에서는 릴레이션이 테이블(Table) 로 생성된다.
최종적으로 DBMS 에서는 릴레이션이 테이블(Table) 로 생성된다.구성 요소 | 설명 |
컬럼 | - 속성(Attribute)라고도 함.
- 데이터의 특징을 나타나고 값을 저장하기 위한 영역이다. |
행 | - 튜플(Tuple) 이라고도 함.
- 각 컬럼에 속하는 저장된 값. |
기본 키 | - 각 행을 고유하게 식별하기 위해 사용되는 열 또는 열의 집합입니다.
- 유일성, 최소성, NOT NULL 을 만족해야되며, 테이블을 대표하는 속성이 된다. |
외래 키 | - 다른 테이블의 기본 키를 참조하는 열로, 두 테이블 간의 관계를 정의합니다.
- 외래키는 관계 연산 중 조인 연산을 하기 위해 사용된다. |
SQL 분류
종류 | 설명 |
DDL | - DB 의 객체 및 구조를 정의하는 언어
- Data Definition Language
- CREATE, ALTER, DROP, RENAME, TRUNCATE |
DML | - 데이터를 입력, 조회, 수정, 삭제 하는 언어
- Data Manipulation Language
- INSERT, SELECT, UPDATE, DELETE |
DCL | - 사용자에게 권한 부여 및 회수하는 언어
- Data Control Language
- GRANT, REVOKE |
TCL | - 트랜잭션을 제어하는 언어
- Transaction Control Language
- COMMIT, ROLLBACK, SAVEPOINT |
DDL (데이터 정의어)
: 테이블을 포함한 여러 객체 생성, 수정, 삭제 하는 명령어
- CREATE : 객체 생성
- ALTER : 객체 수정
- DROP : 객체 삭제
- TRUNCATE : 내부의 내용을 삭제
Plain Text
복사
DML (데이터 조작어)
: 테이블 내의 데이터를 조회, 추가, 수정, 삭제하는 명령어
- SELECT : 데이터 조회
- INSERT : 데이터 추가
- UPDATE : 데이터 수정
- DELETE : 데이터 삭제
Plain Text
복사
DCL (데이터 제어어)
: 데이터에 대한 사용 권한을 부여하거나 해제하는 명령어
- GRANT : 권한 부여
- REVOKE : 권한 해제
Plain Text
복사
TCL (트랜잭션 제어어)
: 트랜잭션 단위로 데이터 변경사항을 영구 저장하거나 되돌리는 명령어
- COMMIT : 트랜잭션에서 변경 사항을 영구적으로 저장하는 명령
- ROLLBACK : 트랜잭션에서 변경 사항을 취소하고 이전 상태로 되돌리는 명령
Plain Text
복사
트랜잭션? (Transaction)
: DBMS 에서 발생하는 하나의 논리적 작업 단위
트랜잭션의 특징 - ACID
•
A
◦
원자성 (Atomicity): 하나의 트랜잭션은 모든 연산이 완전히 수행되거나 아무런 연산도 수행되지 않은 상태로 유지되어야 함을 의미합니다. 즉, 트랜잭션 내의 모든 작업은 함께 실행되거나 아무것도 실행되지 않아야 합니다.
•
C
◦
일관성 (Consistency): 트랜잭션 완료 후에 데이터베이스는 미리 정의된 일관된 상태에 있어야 합니다. 트랜잭션 작업은 데이터베이스의 일관성을 유지해야 합니다.
•
I
◦
격리성 (Isolation): 동시에 여러 트랜잭션이 실행될 때, 한 트랜잭션의 작업이 다른 트랜잭션에 영향을 미치지 않도록 격리되어야 합니다. 각 트랜잭션은 다른 트랜잭션의 작업을 모르고 독립적으로 처리되어야 합니다.
•
D
◦
영속성 (Durability): 트랜잭션이 성공적으로 완료되면 그 결과는 영구적으로 데이터베이스에 저장되어야 합니다. 시스템 장애 또는 비정상 종료가 발생하더라도 데이터의 지속성이 보장되어야 합니다.
이러한 트랙잭션의 특징으로 인해, 데이터베이스의 무결성과 일관성을 보장할 수 있다.
SQL 실행순서
순서 | 단계 | 설명 |
1 | 파싱(Parsing) | SQL 문장을 검사하고 구문 트리를 생성합니다. |
2 | 실행(Execution) | 파싱된 쿼리를 기반으로 데이터베이스 엔진이 실행됩니다. |
3 | 인출(Fetch) | 실행된 결과가 클라이언트로 반환됩니다. |
SELECT
데이터를 조회하는 SQL 명령어
SELECT 컬럼명1, 컬럼명2, ... (전체 *)
FROM 테이블명
WHERE 조건
GROUP BY 그룹기준 컬럼... HAVING 그룹 조건
ORDER BY 정렬기준 컬럼... [ASC | DESC]
Java
복사
필수 키워드 : SELECT, FROM 선택 키워드 : WHERE, GROUP BY, ORDER BY 유의사항
- 위에서 작성한 순서대로 키워드를 작성하지 않으면 오류가 발생한다WHERE
SELECT, UPDATE, DELETE, MERGE 문에 조건을 지정하는 키워드
문법
WHERE 조건;
WHERE 컬럼 (연산) (값 또는 서브쿼리);
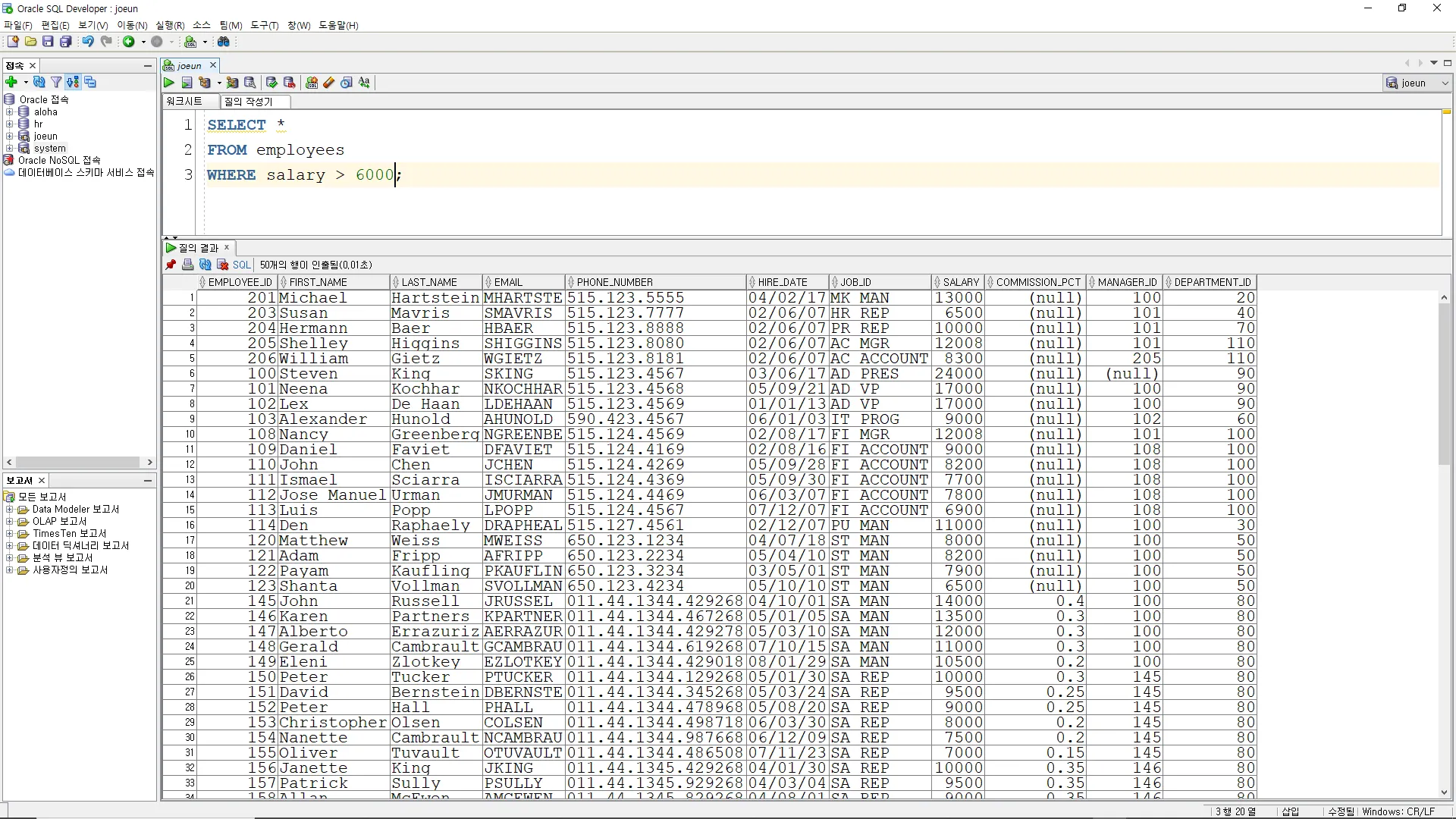
WHERE 컬럼 (연산) (값 또는 서브쿼리);(예시1)
테이블 EMPLOYEES 의 SALARY(급여)가 6000을 초과하는 사원의 모든 컬럼을
조회하는 SQL 문을 작성하시오.
SELECT *
FROM employees
WHERE salary > 6000;
SQL
복사
(예시2)
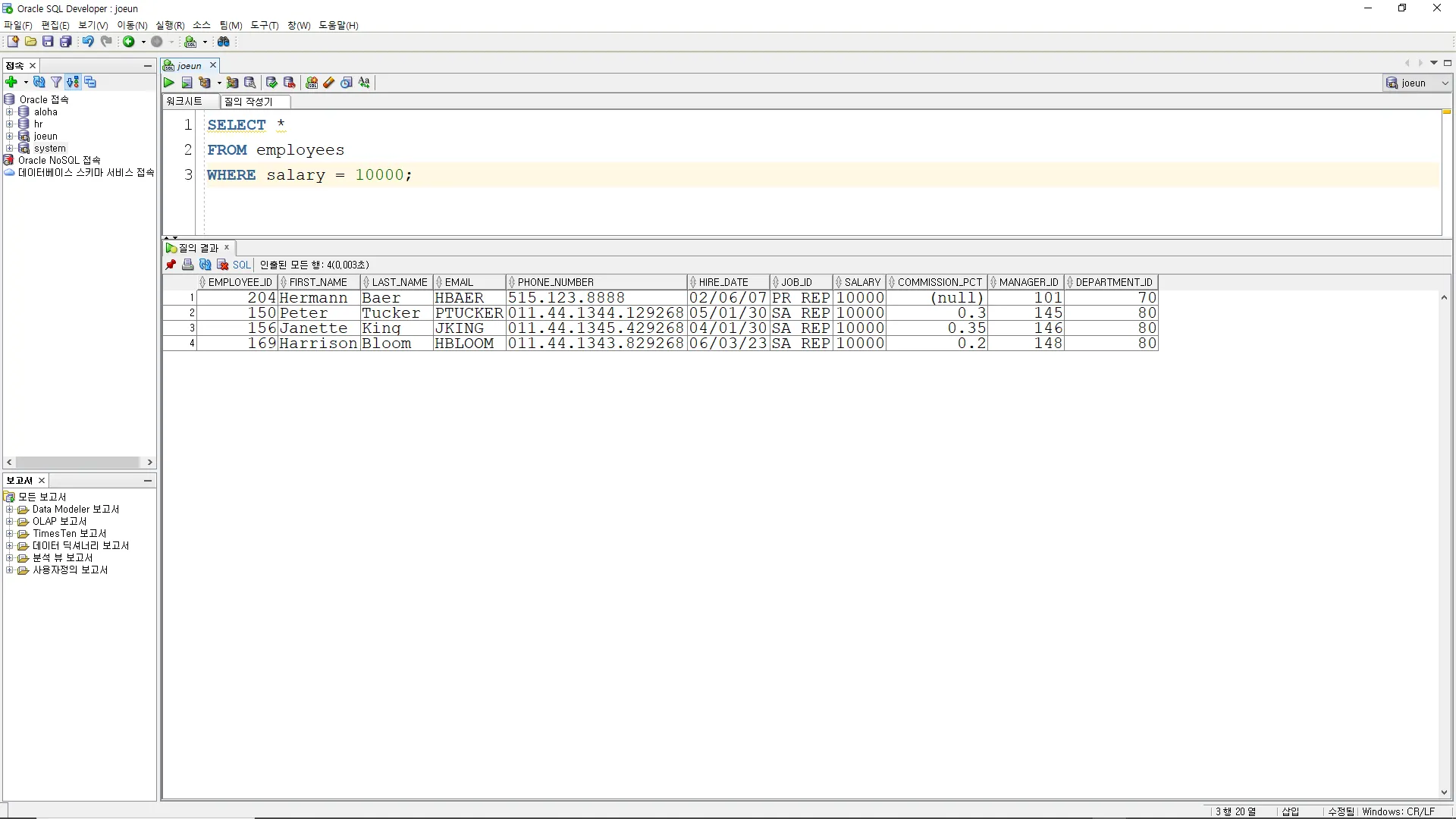
테이블 EMPLOYEES 의 SALARY(급여)가 10000인 사원의 모든 컬럼을
조회하는 SQL 문을 작성하시오.
SELECT *
FROM employees
WHERE salary = 10000;
Java
복사
연산자
▪
산술 연산자
▪
비교 연산자
▪
논리 연산자
산술 연산자
연산자 | 설명 | EX( A : 10, B : 3 ) |
+ | 더하기 | A + B = 13 |
- | 빼기 | A - B = 7 |
* | 곱하기 | A * B = 30 |
/ | 나누기 | A / B = 3.333.. |
% | 나머지 연산 | A % B = 1 |
비교 연산자
연산자 | 설명 | EX( A : 10, B : 3 ) |
= | A = B, A와 B가 같으면 참(TRUE) | A = B, 결과 : FALSE |
!= | A != B, A와 B가 다르면 참(TRUE) | A != B, 결과 : TRUE |
<> | A <> B, A와 B가 다르면 참(TRUE) | A <> B, 결과 : TRUE |
> | A > B, A가 B보다 크면 참(TRUE) | A > B, 결과 : TRUE |
< | A < B, A가 B보다 작으면 참(TRUE) | A < B, 결과 : FALSE |
>= | A ≥ B, A가 B보다 크거나 같으면 참(TRUE) | A ≥ B, 결과 : TRUE |
<= | A ≤ B, A가 B보다 작거나 같으면 참(TRUE) | A ≤ B, 결과 : FALSE |
논리 연산자
▪
BETWEEN A AND B : X >= A AND X <= B
▪
NOT : 논리 부정 연산
- NOT A : A가 TRUE 면 FALSE 로, FALSE 면 TRUE 로 바꾼다
▪
IN 연산자 : 특정 열에 포함되는 여러 값을 조회할 때
◦
A IN (값1, 값2, 값3, ...) : A 속성의 값1,값2,값3 을 포함하여 조회
◦
A NOT IN (값1, 값2, 값3, ...) : A 속성의 값1,값2,값3 을 제외하여 조회
▪
LIKE
◦
A LIKE '_' : _ 한 문자를 대체하는 와일드 카드
◦
A LIKE '%' : % 공백포함 여러글자를 대체하는 와일드 카드
▪
IS NULL
: 열의 값이 존재하는지 확인하는 연산자
A IS NULL : A가 NULL 일 때
A IS NOT NULL : A가 NULL 이 아닐 때
NULL 과의 연산
NULL + 10 = NULL
NULL > 10 = NULL
NULL 과의 연산
NULL + 10 = NULL
NULL > 10 = NULL
▪
AND, OR
◦
A AND B : A 조건, B 조건 둘 다 참일 때만 결과가 참(true)
◦
A OR B : A 조건, B 조건 둘 중 하나라도 참일 때 결과가 참(true)
▪
집합 연산자
◦
UNION : A UNION B, A와 B의 결과를 합집합으로 묶는다. 중복된 데이터는 제거된다.
◦
UNION ALL : A UNION B, A와 B의 결과를 합집합으로 묶는다. 중복된 데이터도 출력된다.
◦
MINUS : A MINUS B, A와 B의 결과를 차집합으로 출력한다.
◦
INTERSECT : A INTERSECT B, A와 B의 결과를 교집합으로 출력한다.
연산자 우선순위
↑ (높음) | |
*, / 곱하기, 나누기 | |
+, - 더하기, 빼기 | |
=, !=, ^=, <>, >, >=, <, <= 비교 연산 | |
IS NULL, LIKE, IN | |
BETWEEN A AND B | |
NOT | |
AND | |
OR | |
↓ (낮음) |
ORDER BY
데이터 조회(SELECT) 시, 결과 데이터를 정렬하는 키워드
문법
ORDER BY 정렬 기준 컬럼… [ASC | DESC];
* ASC : 오름차순
* DESC : 내림차순
* (생략) : 오름차순이 기본값
SQL
복사
ORDER BY 컬럼;
지정한 컬럼을 기준으로, 데이터를 오름차순 정렬한다.
지정한 컬럼을 기준으로, 데이터를 오름차순 정렬한다.ORDER BY 컬럼 [ASC | DESC]
지정한 컬럼을 기준으로, 데이터를 오름차순(ASC) 또는 내림차순(DESC) 정렬한다.
지정한 컬럼을 기준으로, 데이터를 오름차순(ASC) 또는 내림차순(DESC) 정렬한다.ORDER BY 컬럼1 [ASC | DESC], 컬럼2 [ASC | DESC]
정렬 기준 1 : 컬럼1을 기준으로, 데이터를 오름차순 또는 내림차순 정렬한다.
정렬 기준 2 : 컬럼1의 데이터가 같은 경우, 컬럼2를 기준으로, 정렬한ㄴ다.
정렬 기준 1 : 컬럼1을 기준으로, 데이터를 오름차순 또는 내림차순 정렬한다.
정렬 기준 2 : 컬럼1의 데이터가 같은 경우, 컬럼2를 기준으로, 정렬한ㄴ다.(예시)
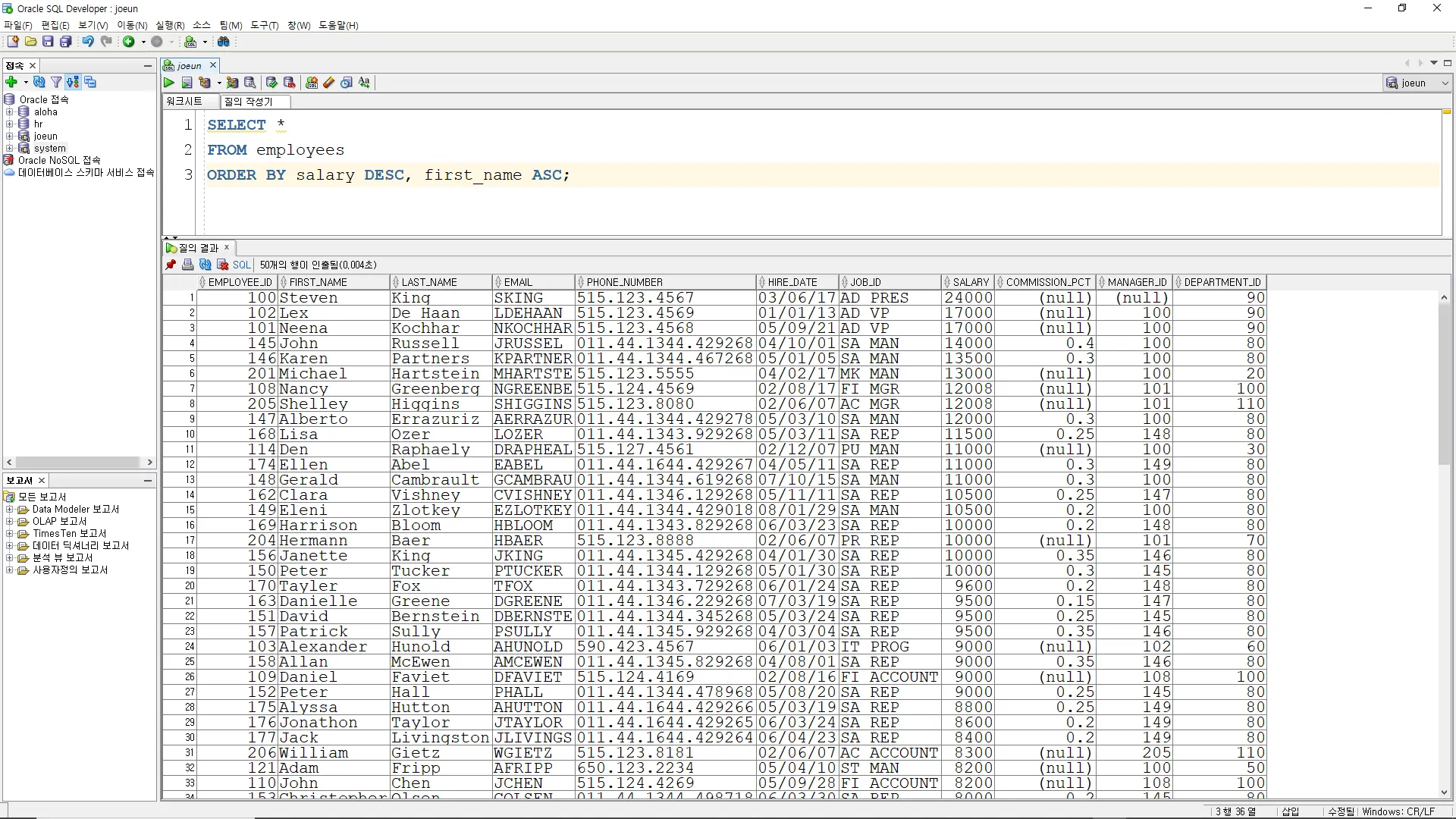
테이블 EMPLOYEES 의 모든 속성들을
SALARY 를 기준으로 내림차순 정렬하고,
FIRST_NAME 을 기준으로 오름차순 정렬하여 조회하는 SQL 문을 작성하시오.
SELECT *
FROM employees
ORDER BY salary DESC, first_name ASC;
SQL
복사
GROUP BY
데이터를 그룹화하여 그룹함수(합계, 평균, 최댓값, 최솟값 등)와 함께 조회하는 키워드
문법
GROUP BY 그룹기준 컬럼 … HAVING 그룹 조건
(예시)
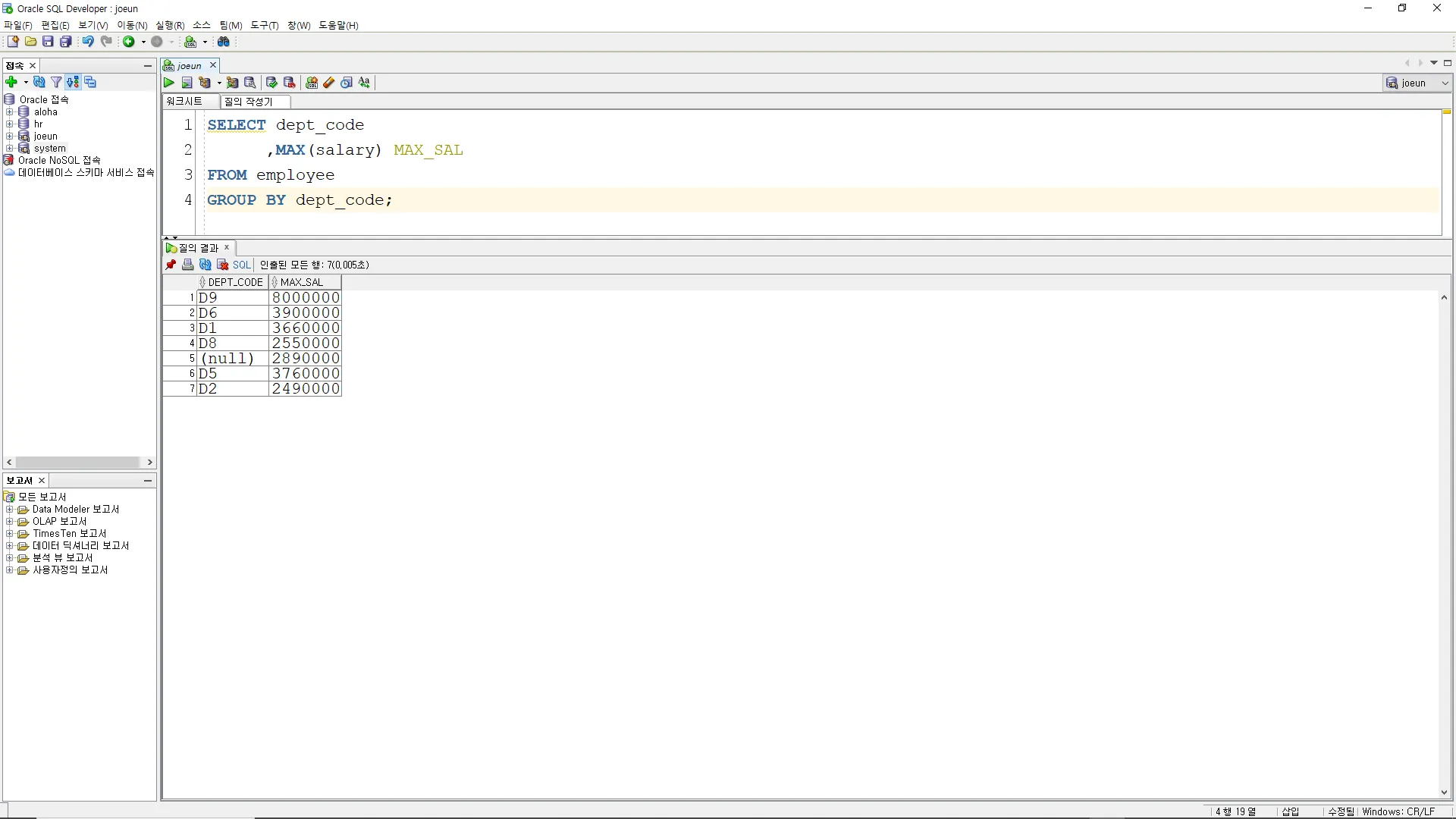
테이블 EMPLOYEES 에 대하여 부서별로 부서코드와 최고급여를 조회하시오.
SELECT dept_code
,MAX(salary) MAX_SAL
FROM employee
GROUP BY dept_code;
SQL
복사
(예시)
테이블 EMPLOYEES 에 대하여, 부서별 인원이 2명이 넘는 부서중, 부서별로 부서코드와 최고급여를 조회하시오.
SELECT dept_code
,MAX(salary) MAX_SAL
FROM employee
GROUP BY dept_code HAVING COUNT(dept_code) > 2;
SQL
복사
SELECT 문 실행순서
FROM WHERE GROUP BY HAVING SELECT ORDER BY
WHERE GROUP BY HAVING SELECT ORDER BY1.
테이블을 선택한다
2.
조건에 맞는 데이터를 선택한다
3.
그룹기준을 지정한다
4.
그룹별로 그룹조건에 맞는 데이터를 선택한다
5.
조회할 컬럼을 선택한다
6.
조회된 결과를 정렬기준에 따라 정렬한다.
형변환
2개의 데이터 타입이 일치하도록 변환하는 것
분류
•
명시적 형변환
•
암시적 형변환
명시적 형변환
형변환 함수를 사용하여 데이터 타입을 명시적으로 변환하는 것.
형변환 함수
함수 | 설명 |
TO_CHAR(인자, 출력포맷) | 인자(날짜, 숫자)를 문자로 변환하는 함수 |
TO_DATE(인자, 포맷) | 문자 데이터를 날짜 데이터로 변환하는 함수 |
TO_NUMBER(인자, 포맷) | 문자 데이터를 숫자 데이터로 변환하는 함수 |
TO_CHAR( )
•
날짜 데이터 문자 데이터
문자 데이터•
숫자 데이터 문자 데이터
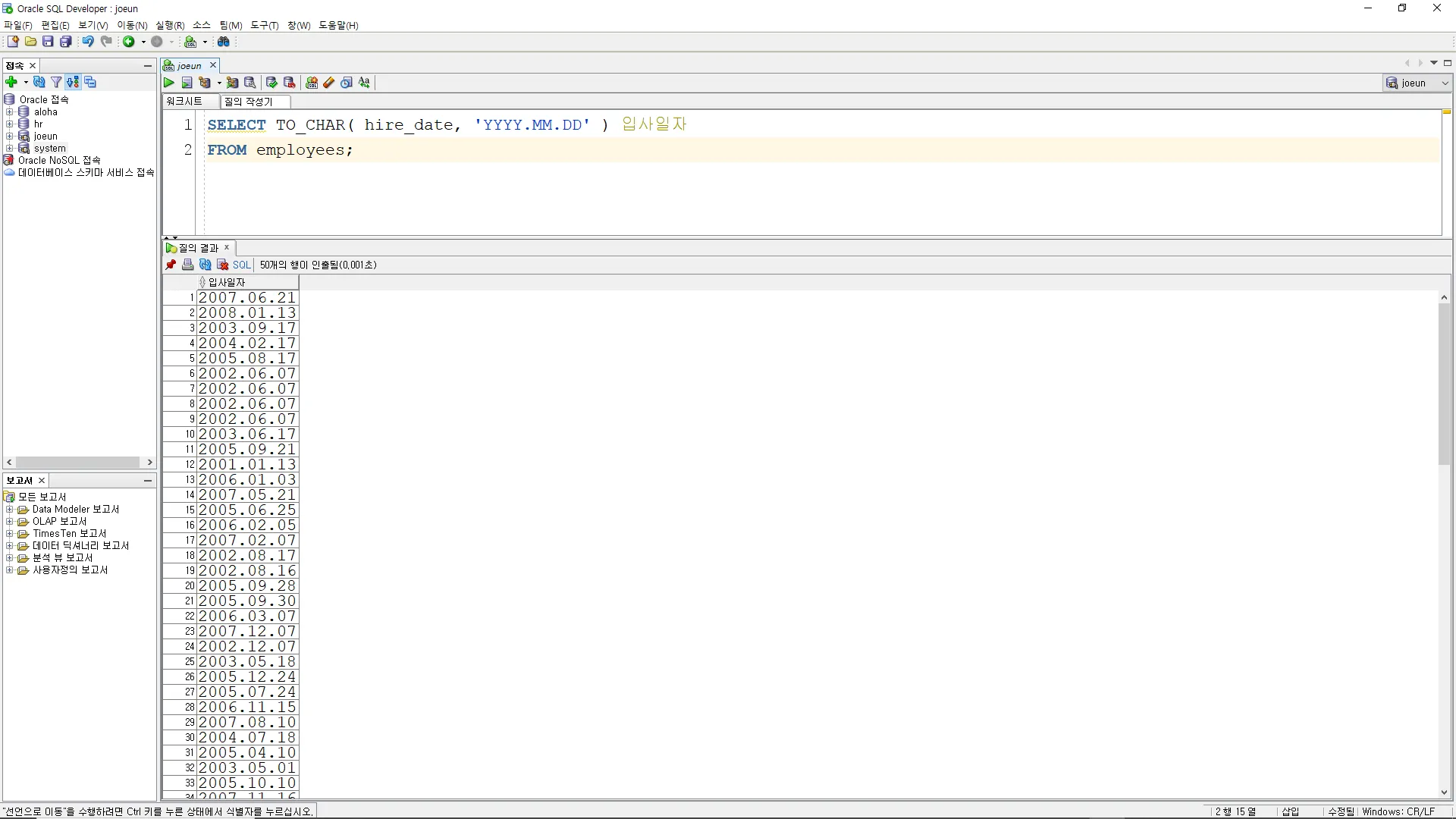
문자 데이터날짜 데이터 문자 데이터 - TO_CHAR( 날짜, 포맷 )
(예시)
SELECT TO_CHAR( hire_date, 'YYYY.MM.DD' ) 입사일자
FROM employees
SQL
복사
날짜 데이터 포맷
포맷 | 설명 |
CC | 세기 |
YYYY | 연도 (4자리) |
YY | 연도 (2자리) |
MM | 월 (2자리) |
MON | 월 (언어별 월 이름의 약자) |
MONTH | 월 (언어별 월 이름) |
DD | 일 (2자리) |
DDD | 1년 중 몇일 (3자리) [1~366] |
DY | 요일 (언어별 요일 이름의 약자) |
DAY | 요일 (언어별 요일 이름) |
W | 1년 중 몇 번째 주 [1~53] |
HH24 | 24시 기준 시간 |
HH | 12시 기준 시간 |
MI | 분 |
SS | 초 |
AM, PM | 오전, 오후 |
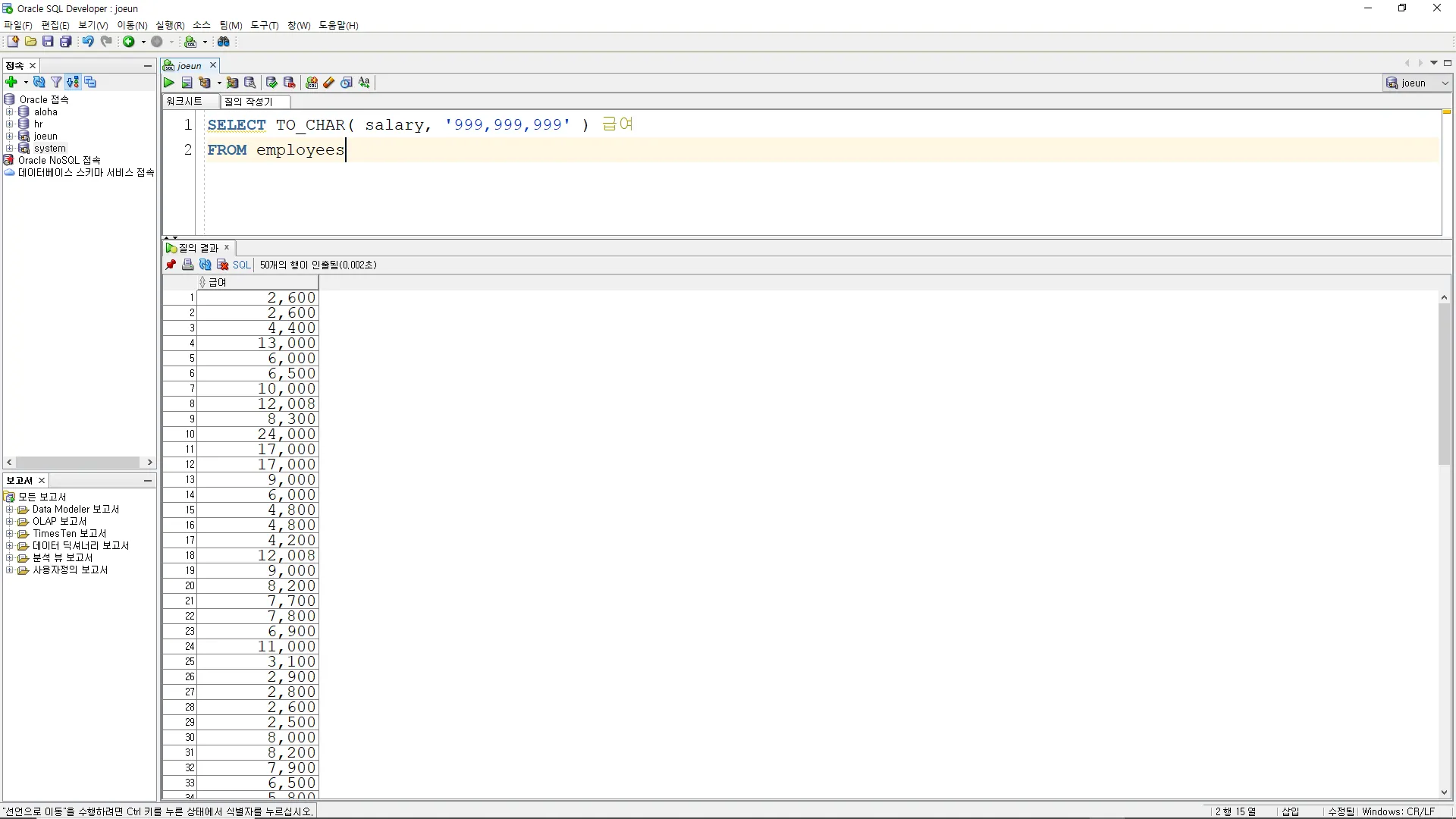
숫자 데이터 문자 데이터 - TO_CHAR( 숫자, 포맷 )
(예시)
SELECT TO_CHAR( salary, '999,999,999' ) 급여
FROM employees
SQL
복사
숫자 데이터 포맷
포맷 | 설명 |
9 | 숫자 한 자리 (값이 없으면 채우지 않음) |
0 | 숫자 한 자리 (값이 없으면 0으로 채움) |
$ | 달러 표시 |
L | 지역 화폐 단위 기호 |
. | 소수점 |
, | 천 단위 구분 기호 |
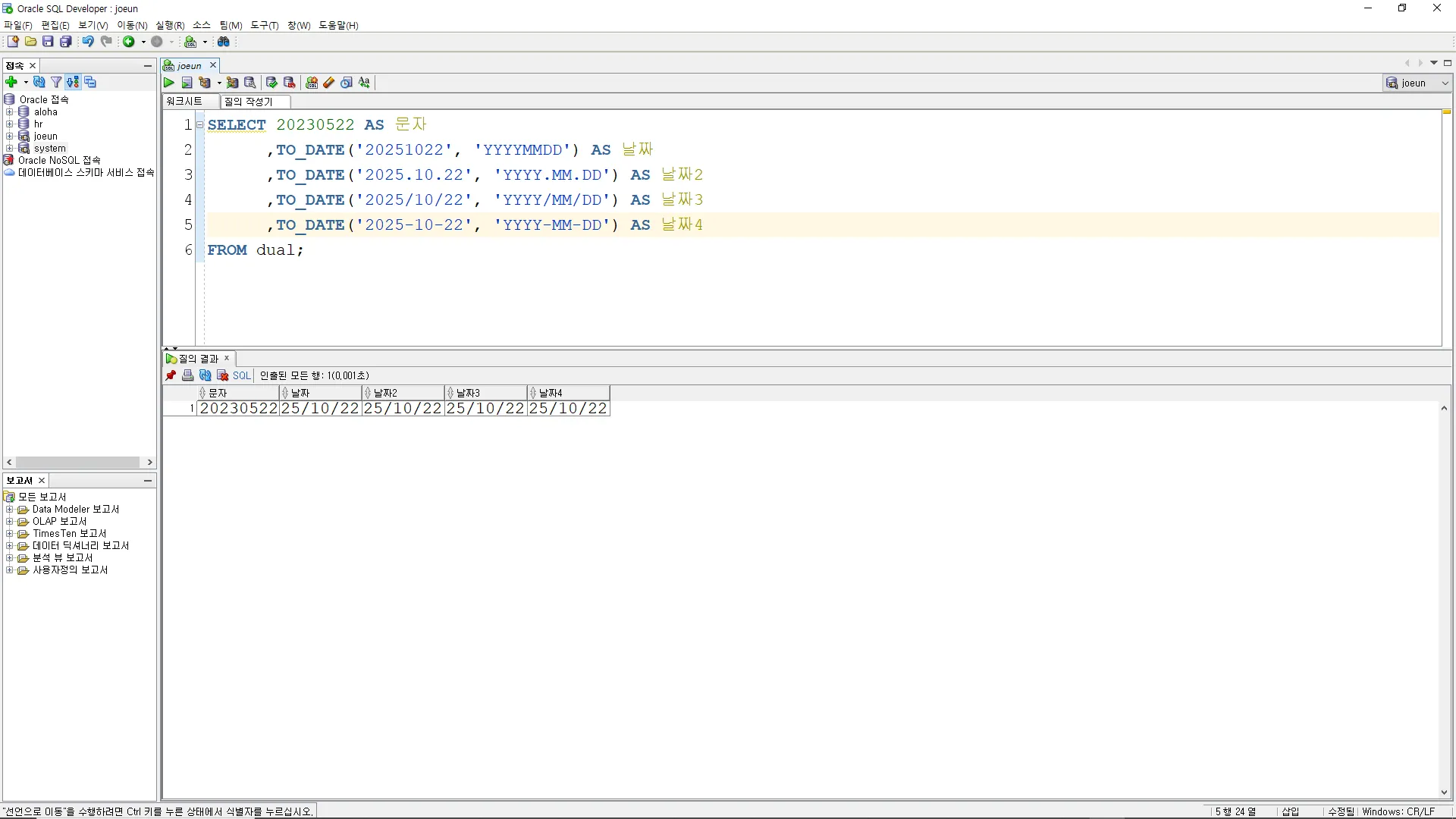
TO_DATE( 문자, 포맷 )
문자형 데이터를 날짜형 데이터로 변환하는 함수
SELECT 20230522 AS 문자
,TO_DATE('20251022', 'YYYYMMDD') AS 날짜
,TO_DATE('2025.10.22', 'YYYY.MM.DD') AS 날짜2
,TO_DATE('2025/10/22', 'YYYY/MM/DD') AS 날짜3
,TO_DATE('2025-10-22', 'YYYY-MM-DD') AS 날짜4
FROM dual;
SQL
복사
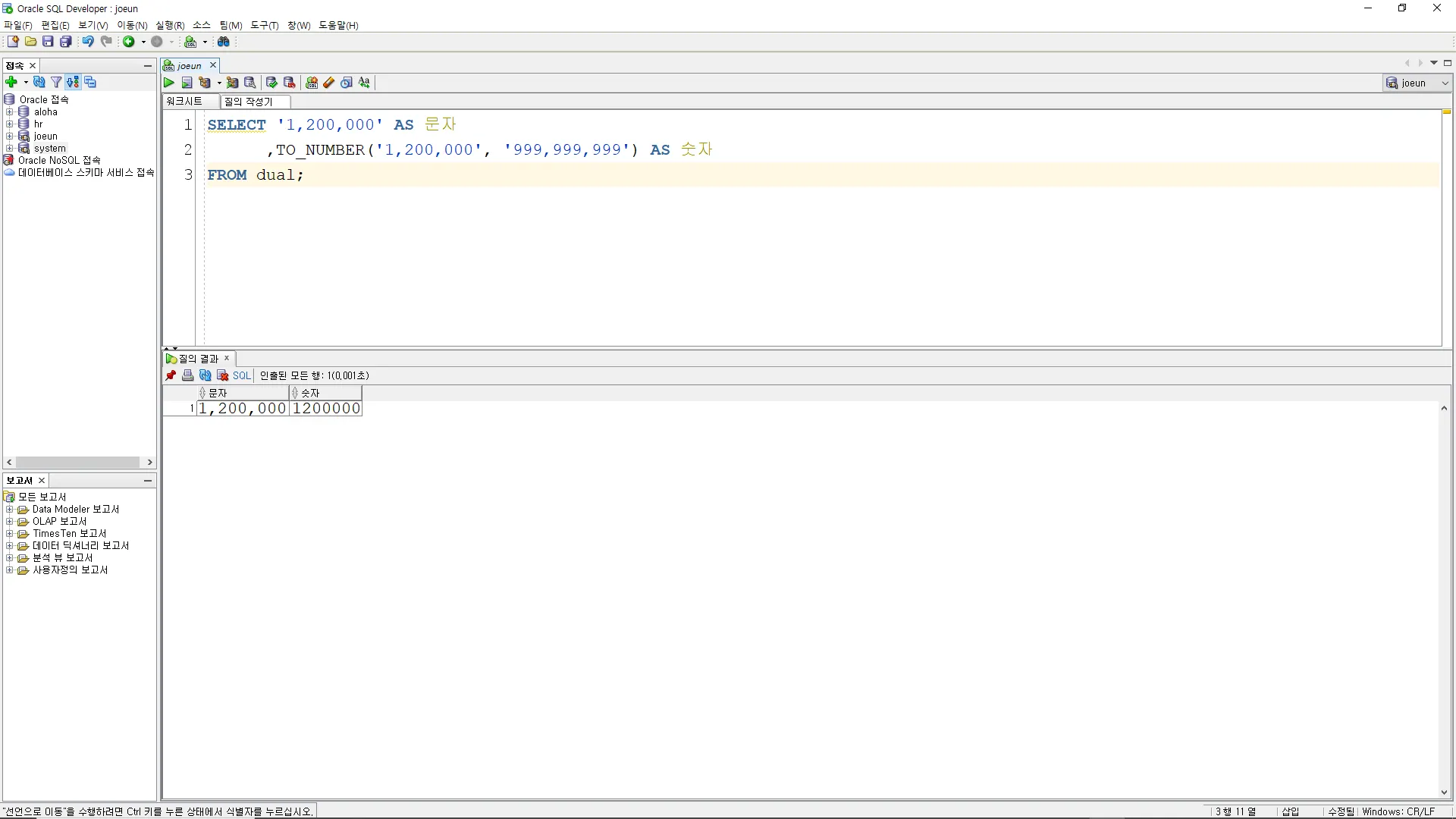
TO_NUMBER( 문자, 포맷 )
문자형 데이터를 숫자형 데이터로 변환하는 함수
SELECT '1,200,000' AS 문자
,TO_NUMBER('1,200,000', '999,999,999') AS 숫자
FROM dual;
SQL
복사
암시적 형변환
개발자가 형변환 처리를 하지 않고, DBMS 가 자동으로 데이터 타입을 변환하는 것.
암시적 형변환 예시
숫자 타입 : empno, 문자 타입 : ‘100’SELECT *
FROM emp
WHERE empno = '100';
SQL
복사
(좌변) = (우변)
이렇게 있을 때, 일반적으로 좌변의 데이터 타입에 맞춰 우변의 데이터 타입을 변환합니다.
즉, EMPNO = TO_NUMBER('100'); 으로 실행됩니다.
따라서 숫자타입인 EMPNO 와 '100' 을 암시적 형변환에 의해서 비교할 수 있습니다.
그렇지만, 인덱스라는 개념은 형변환이 발생하면 사용할 수 없습니다.
이렇게 암시적 형변환이 되어 좌변과 우변이 정상적으로 비교는 가능하지만, 인덱스는 사용할수 없습니다.
내장 함수
데이터베이스에 미리 정의된 함수
대부분의 함수가 유사하게 사용되지만, DBMS 별로 고유하게 정의된 함수도 있다.dual
산술 연산, 함수 결과 등 내장 함수를 사용할 때 자동으로 생성되는 임시 테이블
•
ex) -20 의 절댓값 구하기
내장 함수 종류
•
문자함수
•
날짜함수
•
숫자함수
문자함수
UPPER(인자) | 인자(영문자)를 대문자로 변환하는 함수 |
LOWER(인자) | 인자(영문자)를 소문자로 변환하는 함수 |
INITCAP(인자) | 인자(영문자)를 단어를 기준으로 첫글자를 대문자로 변환하는 함수 |
LENGTH(인자) | 인자의 글자 수를 반환하는 함수 |
LENGTHB(인자) | 인자의 바이트 수를 반환하는 함수 |
CONCAT(인자1, 인자2) | 인자1과 인자2를 연결하는 함수 || : 2개 이상의 문자열을 연결하는 기호 |
SUBSTR(문자열, 시작번호, 글자수) | 문자열에서 시작번호부터 지정한 글자 수만큼의 문자열을 추출하여 반환하는 함수 |
SUBSTRB(문자열, 시작번호, 바이트수) | 문자열에서 시작번호부터 지정한 바이트 수만큼의 문자열을 추출하여 반환하는 함수 |
INSTR(문자열, 문자, 시작번호, 순서) | 문자열 안에서 지정한 시작번호부터 문자를 찾아서, 지정한 순서에서 있는 문자의 위치를 반환하는 함수 |
INSTRB(문자열, 문자, 시작번호, 순서) | 문자열 안에서 지정한 시작번호부터 문자를 찾아서, 지정한 순서에서 있는 문자의 위치를 바이트로 반환하는 함수 |
LPAD(문자열, 칸, 문자) | 지정한 칸에서 왼쪽 빈공간을 특정문자로 채우는 함수 |
RPAD(문자열, 칸, 문자) | 지정한 칸에서 오른쪽 빈공간을 특정문자로 채우는 함수 |
날짜함수
SYSDATE | 현재 날짜와 시간을 DATE 타입의 데이터로 반환하는 함수 |
SYSTIMESTAMP | 현재 날짜와 시간을 TIMESTAMP 타입의 데이터로 반환하는 함수 |
ADD_MONTHS(날짜, 개월수) | 해당 날짜로부터 개월 수를 더한 날짜를 반환하는 함수 |
MONTHS_BETWEEN(날짜1, 날짜2) | 날짜1 부터 날짜2 사이의 개월 수를 반환하는 함수 |
NEXT_DAY(날짜, 요일번호) | 지정한 날짜 이후에 나오는 요일번호에 해당하는 날짜를 반환하는 함수- 요일 번호 : 일요일(1) ~ 토요일(7) |
LAST_DAY(날짜) | 지정한 날짜와 같은 달의 마지막 날짜를 반환하는 함수 (월말) |
TRUNC( 날짜, 날짜형식 ) | 날짜형식 단위로 날짜 데이터를 절삭하여 반환하는 함수ex) TRUNC( 날짜, 'MM' ) : 월 단위로 날짜 데이터를 절삭하여 같은 달의 첫번째 날짜를 구하는 함수 (월초) |
숫자함수
CEIL(인자) | 인자보다 크거나 같은 정수 중 제일 작은 수를 반환하는 함수- [ceil : "천장"] ex) CEIL(12.34) : 13 (결과값은 정수) |
FLOOR(인자) | 인자보다 작거나 같은 정수 중 제일 큰 수를 반환하는 함수- [floor : "바닥"] ex) FLOOR(12.34) : 12 (결과값은 정수) |
ROUND(인자, 자리수 | 인자를 지정한 자리수에서 반올림한 값을 반환하는 함수 |
MOD(인자1, 인자2) | 인자1을 인자2를 나눈 나머지를 반환하는 함수 |
POWER(인자1, 인자2) | 인자1을 인자2로 제곱하는 값을 반환하는 함수 |
SQRT(인자) | 인자의 제곱근을 구한 값을 반환하는 함수 |
TRUNC(인자, 자리수) | 인자를 자리수에서 절삭한 값을 반환하는 함수 |
ABS(인자) | 인자의 절댓값을 반환하는 함수 |
DECODE, CASE
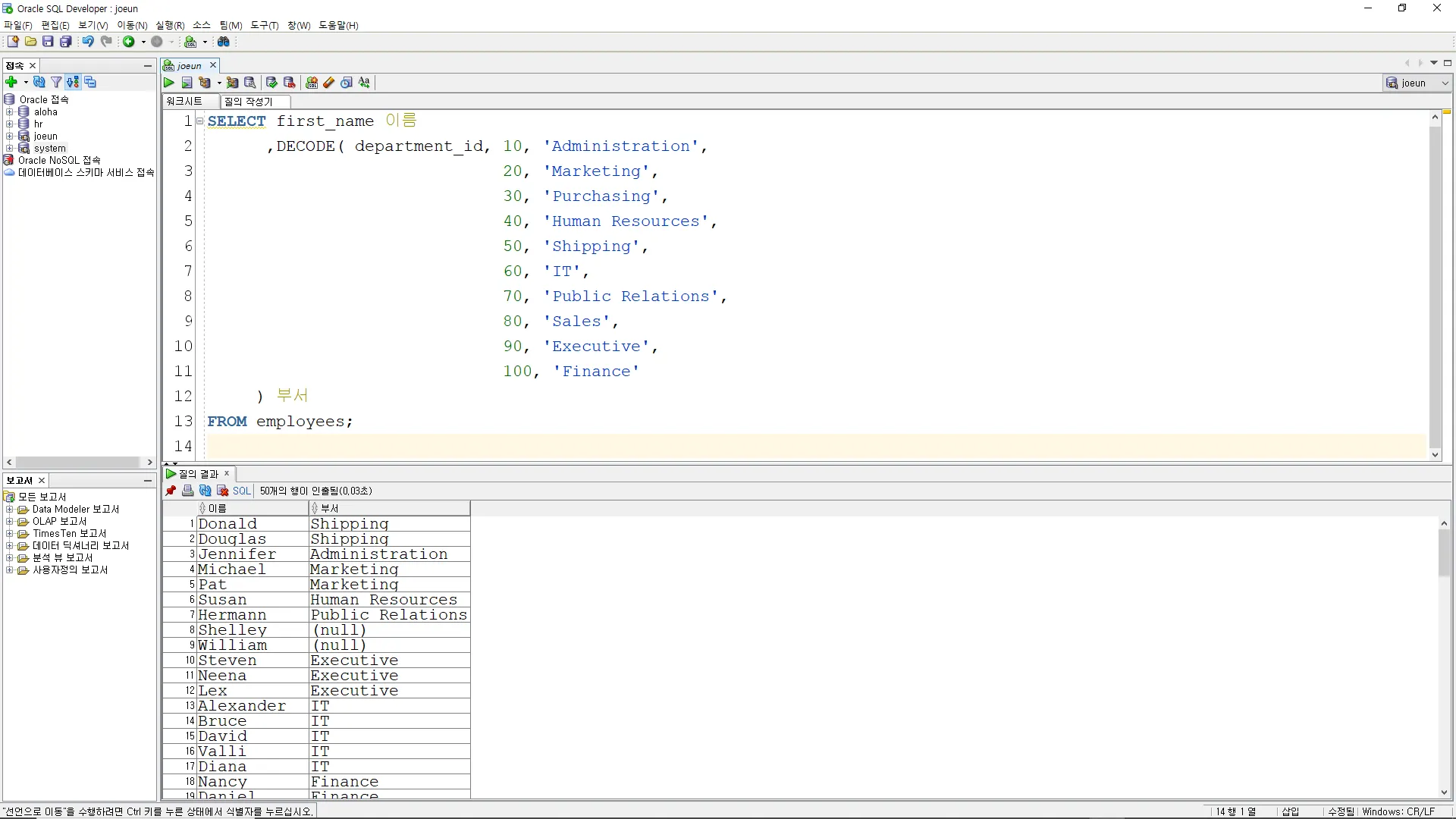
DECODE
지정한 컬럼의 값이 조건값에 일치하면 바로 뒤의 반환값을 출력하는 함수
•
문법
DECODE( 컬럼명, 조건값1, 반환값1, 조건값2, 반환값2, ... )
•
예시
: DEPARTMENTS 테이블을 참조하여, 사원의 이름과 부서명을 출력하시오.
SELECT first_name 이름
,DECODE( department_id, 10, 'Administration',
20, 'Marketing',
30, 'Purchasing',
40, 'Human Resources',
50, 'Shipping',
60, 'IT',
70, 'Public Relations',
80, 'Sales',
90, 'Executive',
100, 'Finance'
) 부서
FROM employees;
SQL
복사
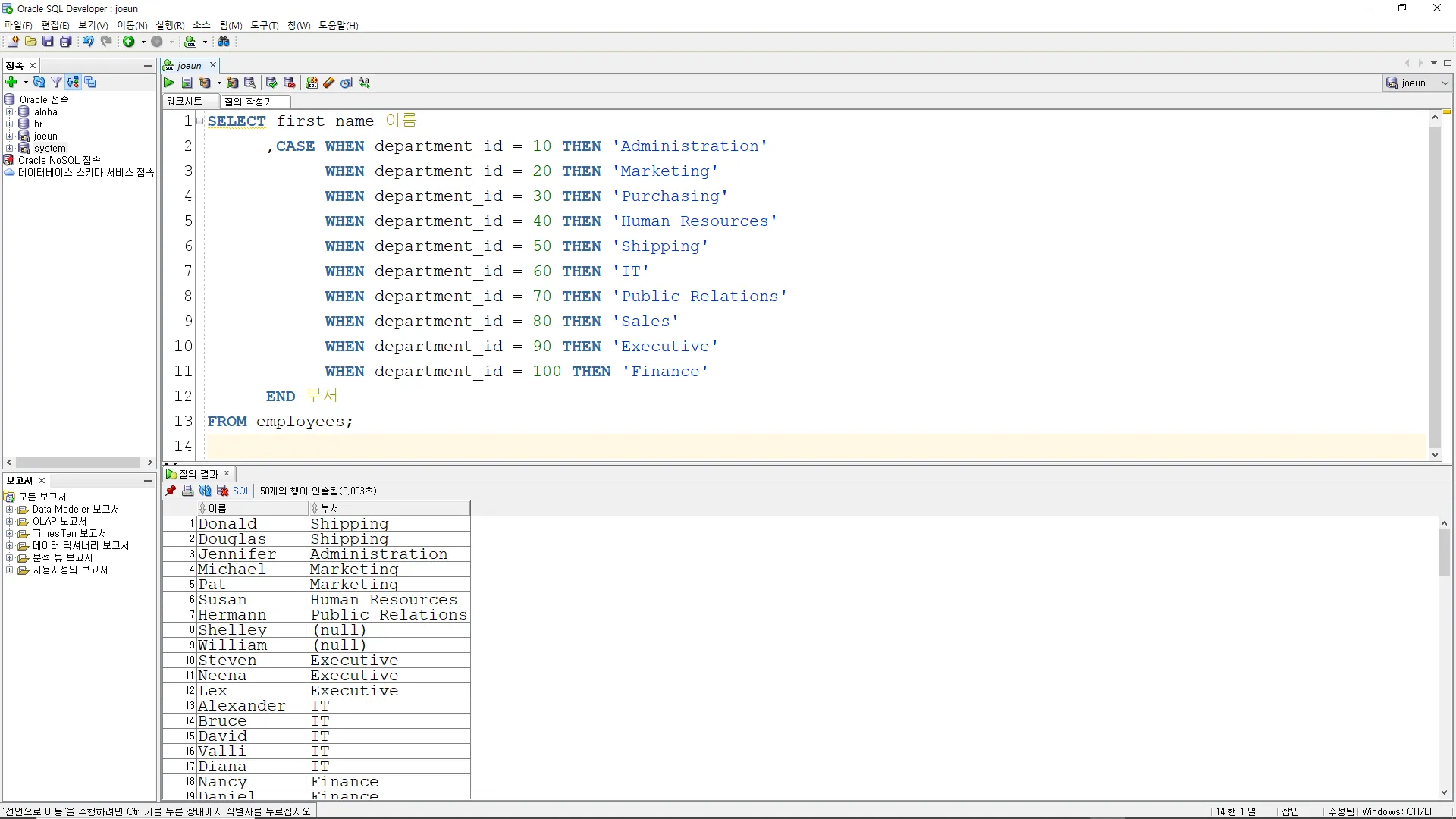
CASE
조건식을 만족할 때, 출력할 값을 지정하는 구문
•
문법
CASE
WHEN 조건1 THEN 반환값1
WHEN 조건2 THEN 반환값2
…
END
•
예시
: 테이블 EMPLOYEES 의 FIRST_NAME, DEPARTMENT_ID 속성을 이용하여 <예시>와 같이 SQL 문을 작성하시오.
SELECT first_name 이름
,CASE WHEN department_id = 10 THEN 'Administration'
WHEN department_id = 20 THEN 'Marketing'
WHEN department_id = 30 THEN 'Purchasing'
WHEN department_id = 40 THEN 'Human Resources'
WHEN department_id = 50 THEN 'Shipping'
WHEN department_id = 60 THEN 'IT'
WHEN department_id = 70 THEN 'Public Relations'
WHEN department_id = 80 THEN 'Sales'
WHEN department_id = 90 THEN 'Executive'
WHEN department_id = 100 THEN 'Finance'
END 부서
FROM employees;
SQL
복사
WITH
서브쿼리를 사용해서 임시 테이블을 미리 조회할 수 있는 구문
문법
WITH 임시테이블명 AS (
서브쿼리
)
SELECT …
FROM …;
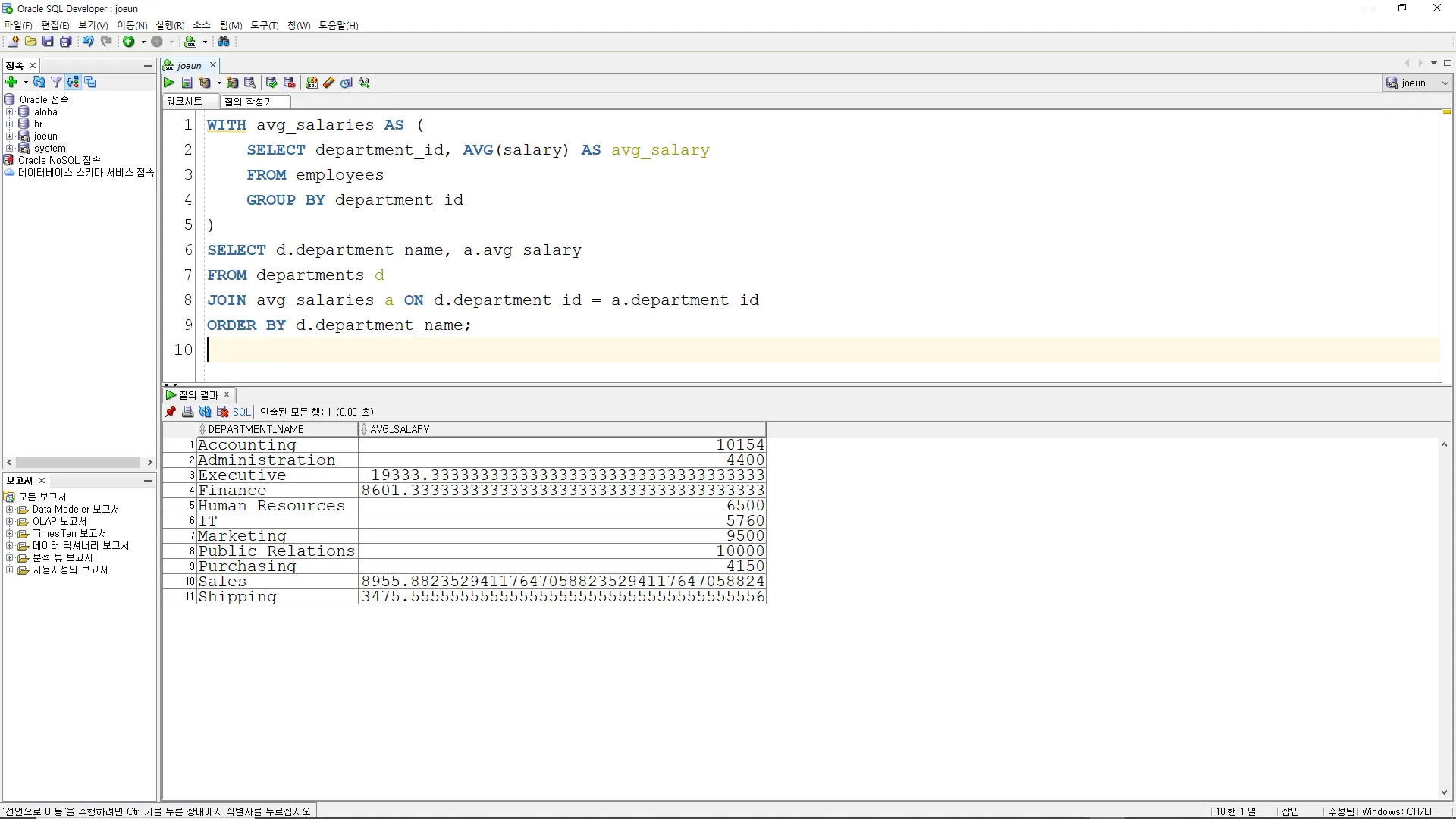
예시
: 각 부서별로 직원들의 평균 급여를 계산하고, 부서명과 부서별 평균급여를 조회하시오.
WITH avg_salaries AS (
SELECT department_id, AVG(salary) AS avg_salary
FROM employees
GROUP BY department_id
)
SELECT d.department_name, a.avg_salary
FROM departments d
JOIN avg_salaries a ON d.department_id = a.department_id
ORDER BY d.department_name;
SQL
복사